数据库大宽表设计图
 社区干货
社区干货
日增320TB数据,从ClickHouse迁移至ByConity后,查询性能十分稳定!
## 背景介绍ByConity适合多种业务场景,在实时数据接入、大宽表聚合查询、海量数据下复杂分析计算、多表关联查询场景下有非常好的性能。我们用一个实际的业务场景来介绍下,这套行为分析系统是基于用户多维度行为分... *图1* *行为分析系统* *架构设计* ## 问题和挑战早期这套系统部署在ClickHouse集群,一方面,由于业务的高速发展导致数据量日益膨胀,每日最大新增数据超过320TB,每日新增行数超过2.3万亿条,用户数据维度超过2万多个...
干货|字节跳动基于 Apache Hudi 的多流拼接实践
字节跳动存在较多业务场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个... 我们设计了一种完全基于存储层的多流拼接方案,支持多个数据流并发写入,读时按照主键合并多流数据,此外还支持异步 Compact 来加速下游读取数据。  特惠活动
特惠活动
 数据库大宽表设计图-优选内容
数据库大宽表设计图-优选内容
 数据库大宽表设计图-相关内容
数据库大宽表设计图-相关内容
干货|字节跳动基于 Apache Hudi 的多流拼接实践
字节跳动存在较多业务场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出... 我们设计了一种完全基于存储层的多流拼接方案,支持多个数据流并发写入,读时按照主键合并多流数据,此外还支持异步 Compact 来加速下游读取数据。 定制化。各业务根据需求进行定制,构建高可用,高性能,特性丰富的数据管理平台对基础设施的要求较高。 二、数据库选型下表展示了各类数据库的功能特性及相关产品...
分布式数据库TiDB的设计和架构
xiaoyu向大家介绍了数据库发展史、TiDB 设计、架构及生态及TiDB在得物的应用。数据库技术发展演进**2008年以前**2008 年以前应用最为广泛的是单机关系型数据库(SQL),能很好的解决复杂的数据运算及表间处理,多... 图|TiDB整体架构### TiDB ServerSQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负...
最高提升10倍性能!揭秘火山引擎ByteHouse查询优化器实现方案
作为火山引擎推出的一款云原生数据库产品,ByteHouse以开源ClickHouse为基础,在字节跳动多年打磨下,致力于提供更丰富的能力和更强性能,为用户带来极速分析体验。而ClickHouse以快速处理数据而著名,但其查询优化器在处理多表查询和高维度数据时却显得力不从心。 ClickHouse查询优化器的局限性,主要体现在:为了获取最佳的性能,用户往往需要预先生成数据大宽表,来避免复杂的多表查询开销。然而,该做法的代价巨大。每当维度变化...
分布式数据库TiDB的设计和架构
那么目前数据库圈最火的分布式关系型数据库之一TiDB你了解吗?相信很多同学以前听说过TiDB,也知道是一款国人研发的数据库,但你知道TiDB到底是如何实现的?它跟其他数据库产品相比,它的核心优势是什么?此次夜校分享,xiaoyu向大家介绍了数据库发展史、TiDB 设计、架构及生态及TiDB在得物的应用。# 数据库技术发展演进**2008年以前**2008 年以前应用最为广泛的是单机关系型数据库(SQL),能很好的解决复杂的数据运算及表间处理,...
Serverless StarRocks表模型设计
表中所有的行按照维度列,做多重排序,排序后的位置就是该行的行号。 1.2 索引StarRocks 通过前缀索引 (Prefix Index) 和列级索引,能够快速找到目标行所在数据块的起始行号。StarRocks 表设计原理如下图所示。一张表... 存算分离模式支持创建主键模型表,并且自 3.1.4 版本起,支持基于本地磁盘上的持久化索引。 5.1 适用场景主键模型适用于实时和频繁更新的场景,例如: 实时对接事务型数据至 StarRocks。事务型数据库中,除了插入数据外...
达梦@记一次国产数据库适配思考过程|社区征文
若是通过**DM8工具去建表建字段或者带小写加双引号创建脚本**,出现双引号则在实际的sql方言中也需要加上双引号,否则执行sql会抛出视图或表不存在,字段列名不存在的异常。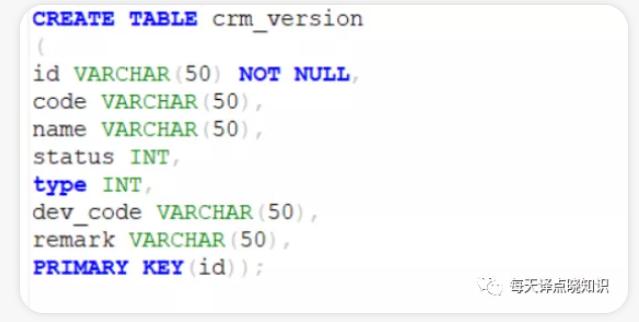若是通过**Mysql或Oracle或其他数据库,文件等方式迁移导入**。这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超...
一文读懂火山引擎云数据库产品及选型
> **火山引擎存储&数据库产品解决方案团队**,由资深的存储&数据库解决方案架构师组成。团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软...
StarRocks表模型设计
表中所有的行按照维度列,做多重排序,排序后的位置就是该行的行号。 1.2 索引StarRocks 通过前缀索引 (Prefix Index) 和列级索引,能够快速找到目标行所在数据块的起始行号。StarRocks 表设计原理如下图所示。一张表... 存算分离模式支持创建主键模型表,并且自 3.1.4 版本起,支持基于本地磁盘上的持久化索引。 5.1 适用场景主键模型适用于实时和频繁更新的场景,例如: 实时对接事务型数据至 StarRocks。事务型数据库中,除了插入数据外...
