数据库er图用什么画
 社区干货
社区干货
2022技术盘点之平台云原生架构演进之道|社区征文
下图为SmartOps架构全景: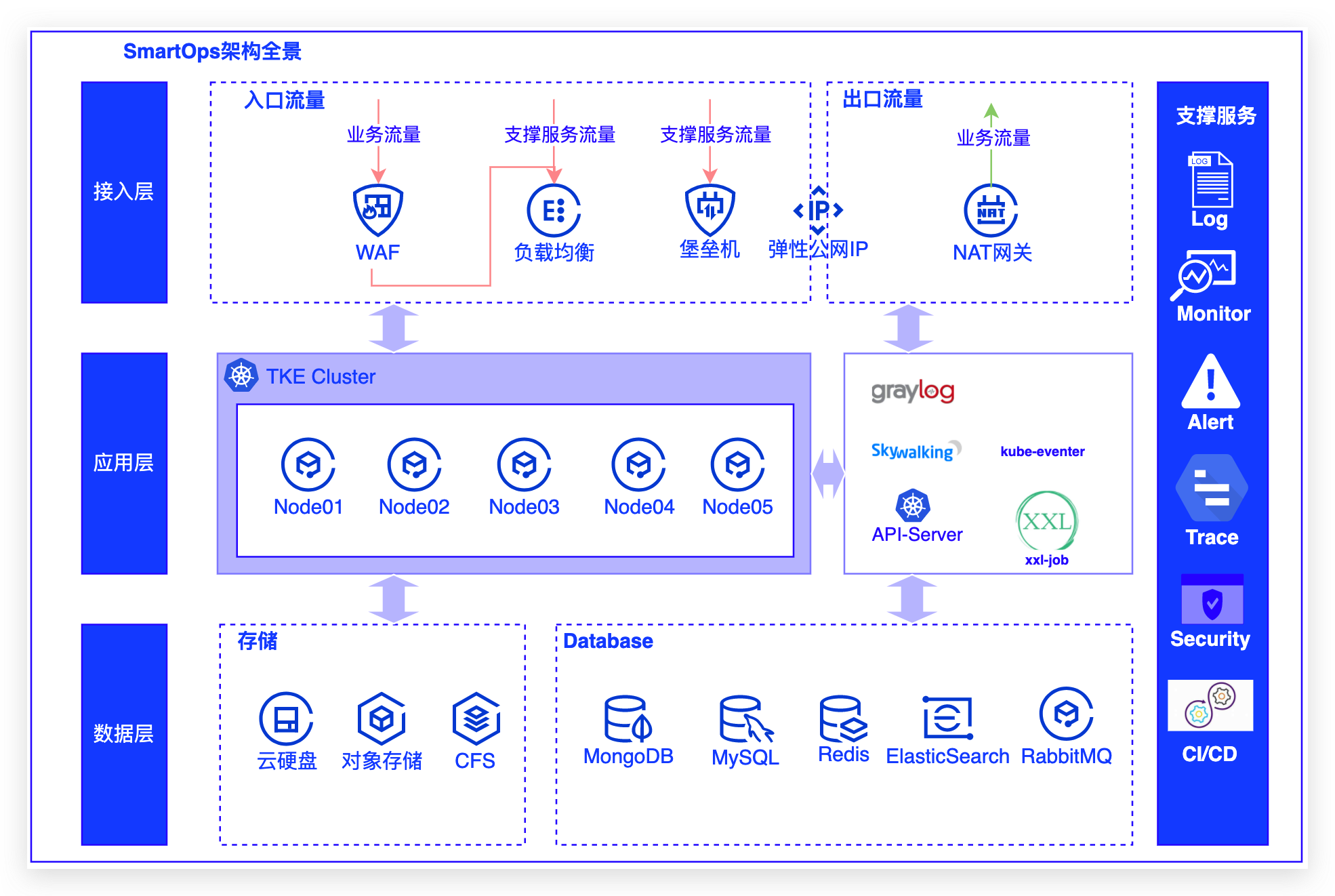- 接入层:通过WAF/SLB,配合NAT网关治理出方向流量,部署有堡垒机进行运维等其他辅助业务进行支撑;- 应用层:采用腾讯TKE进行业务容器部署,配合K8s原生服务注册发现/配置中心/分布式调度中心/日志/监控/告警/链路追踪/DevOps等构筑完整应用体系;- 数据层:存储使用有云硬盘/对象存储/CFS,数据库有Mon...
字节跳动自研万亿级图数据库 & 图计算实践
ByteGraph 主要用于在线 OLTP 场景,而在离线场景下,图数据的分析和计算需求也逐渐显现。在这篇文章中,将从 ByteGraph 的适用场景、内部架构、关键问题分析几个方面作深入介绍,并将介绍图计算相关实践。 自研图数据库(ByteGraph)介绍 从数据模型角度看,图数据库内部数据是有向属性图,其 **基本元素是 Graph 中的点(Vertex)、边(Edge)以及其上附着的属性** ;作为一个工具,图数据对外提供的接...
一文读懂火山引擎云数据库产品及选型
其中主流的商业关系型数据库代表有 Oracle、SQL Server、DB2 等;主流的开源关系型数据库代表有 MySQL、PostgreSQL、MariaDB 等。**NoSQL**,Not Only SQL,"不仅仅是 SQL",广泛应用于以互联网业务为代表的场景。NoSQL 数据库又可以 **细分为 KV 型 NoSQL 数据库(以 Redis 为代表)、文档型 NoSQL 数据库(以 MongoDB 为代表)、宽列型 NoSQL 数据库(以 HBase 为代表)、时序型 NoSQL 数据库(以 InfluxDB 为代表)以及图 NoSQL 数据...
2022下半年《软考-系统架构设计师》备考经验分享
如下图所示,软考有3个级别5个专业,很多同学在报名的时候不知道如何选择科目。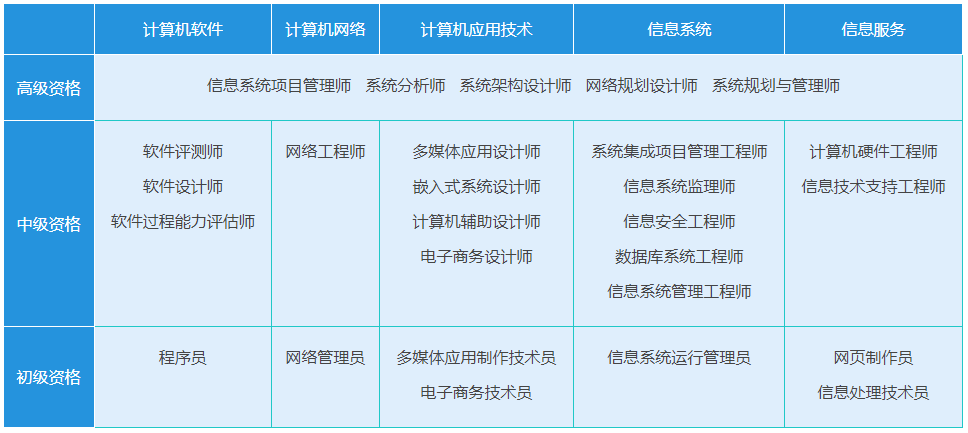软考高级比中级的难度要大一些。中级考试为基础... 数据库系统(设计范式、关系代数、SQL、数据架构、并发控制等)、计算机网络(常见网络设备、常用协议、组网方式等)、嵌入式系统(嵌入式操作系统、多核处理等),每个部分基本就是学校里面所学知识的简化版。针对这一部...
 特惠活动
特惠活动
 数据库er图用什么画-优选内容
数据库er图用什么画-优选内容
 数据库er图用什么画-相关内容
数据库er图用什么画-相关内容
OLAP引擎也能实现高性能向量检索,据说QPS高于milvus!
用来提升非结构化数据的分析和检索能力。ByteHouse是火山引擎推出的云原生数据仓库,近期推出高性能向量检索能力,本篇将结合ByteHouse团队对向量数据库行业和技术的前沿观察,详细解读OLAP引擎如何建设高性能的向量检索能力,并最终通过开源软件VectorDBBench测试工具,在 cohere 1M 标准测试数据集上,recall 98 的情况下,QPS性能已可以超过专用向量数据库(如milvus)。# 向量检索现状分析## 向量检索定义对于诸如图片、视频、音...
抖音大规模实践,火山引擎向量数据库是这样炼成的
成为生成式AI应用开发新范式的重要组成部分。用图片搜索图片或者文本搜索文本时,在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是为了通过向量相似来进行非结构化数据的检索,向量化后的数据才能够被AI模型更好的理解使用。向量数据库就是用于生产、存储、索引和分析来自机器学习模型产生的海...
集简云本周自动化流程模板推荐
=&rk3s=8031ce6d&x-expires=1714926006&x-signature=lHB6mv6GAquqRpJjk%2FXerU4mVfU%3D)](https://www.jijyun.cn/apps/processes/1187) [(点击文字或图片使用此模板)](https://www.jijyun.cn/apps/p... 目前已经接入200+款应用系统,它可以与企业的各种自建或者第三方业务系统对接,包括客服系统,CRM系统,网站数据分析系统,电子商务系统,物流管理系统,企业数据库,企业API接口等,通过无代码集成方式无需开发即可建立自动...
如何构建企业内的 TiDB 自运维体系
TiDB Server、PD 采用无本地 SSD 机型,TiKV 采用本地 SSD 机型。既兼顾了性能,又能降低成本。详细的机型选择会在后面的内容提到。# 3 MySQL 与 TiDB 的对比圈内一直流传着一句话,没有一种数据库是"银弹"。绝大... 上图的流程主要是用于管控非白屏化的 TiDB 基础设施变更。通过变更文档整理、运维小组 Review 的机制,确保复杂变更的规范化。- - 面向研发变更的系统管控DML\DDL 变更工单风险自动化识别](https://www.jijyun.cn/apps/processes/854)[(点击文字或图片使用此模板)](https://www.jijyun.cn/apps/processes/854) **使用场景**财务人员每月汇总审批记录,需要手动导出导入,耗费人力,还容易出错,用了此流程,员工提交钉钉审批信息自动记录并分析,生成自定义的数据库看板,配合维格表的计算字段功能自动统计审批信息...
数据库顶会 VLDB 2023 论文解读:字节跳动如何解决超大规模流式任务运维难题
字节跳动基础架构-计算-流式计算团队联合发表在国际数据库与数据管理顶级会议 VLDB 2023 上的论文“StreamOps: Cloud-Native Runtime Management for Streaming Services in ByteDance”,介绍字节跳动内部基于数万... 上图展示了 StreamOps 的总体架构和工作流程。其主要包括 3 个组件:1. 控制平面服务 (Control Plane Service) :可水平拓展的无状态服务来管理集群级别的流式作业,独立于流式作业部署以解耦控制平面和流式计算引...
开源数据集成平台SeaTunnel:MySQL实时同步到es
## 一、前言- 最近,项目有几个表要从 MySQL 实时同步到 另一个 MySQL,也有同步到 ElasticSearch 的。- 目前,公司生产环境同步,用的是 阿里云的 DTS,每个同步任务每月 500多元,有点小贵。- 其他环境:MySQL同步到ES,用的是 CloudCanal,不支持 数据转换,添加同步字段比较麻烦,社区版限制5个任务,不够用;MySQL同步到MySQL,用的是 debezium,不支持写入 ES。- 恰好3年前用过 SeaTunnel 的 前身 WaterDrop,那就开始吧。本文以 2.3.1...
「火山引擎」数智平台 VeDI 数据中台产品季刊 VOL.10
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/0b384afa9eee44d18dcf654dbfe404a3~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714753225&x-signature=imqersEYh... 保护用户数据隐私及安全合规;- 应用场景:传统数据库集群中,数据明文保存在行存/列存文件中,集群的维护人员或者恶意攻击者可在 OS 层面绕过数据库的权限控制机制或者窃取磁盘直接访问用户数据。LAS 通过集成密钥...
