数据库和内存过程流程图
 社区干货
社区干货
火山引擎ByteHouse:分析型数据库如何设计列式存储
分析型数据库中的列式存储,是一种数据库的物理存储结构,它是根据数据的列而不是行来存储数据的。列式存储的主要优势在于它能够提高数据分析和查询的性能,尤其是在处理大规模数据集时。以下是列式存储的一些主要特点:1. **数据压缩**: 由于同一列中的数据往往具有相似或相同的数据模式(例如日期、时间、地址等),因此列式存储可以更有效地进行数据压缩,从而节省存储空间。1. **数据筛选性能**: 列式存储使得只读取查询所需的...
[数据库系统] 业界列式存储浅析
# 简介众所周知,在数据库存储引擎侧通常有两类存储模型,行式存储NSM(N-ary Storage Model)和列式存储DSM(Decomposition Storage Model),两种存储模型各有其特定的擅长场景。在以前,主流存储设备是机械磁盘的情况... 而且会影响内存中cache的使用效率;在计算时,由于行数据在内存中是顺序存储在一起的,所以对 cpu cache 也很不友好。 列存就是解决上述问题的灵丹妙药,首先读取时只需要读取关心的列数据,在计算时也对cpu cache非常友...
自建数据库与RDS性能对比注意事项
# 前言从 on-premise 数据库迁移到火山引擎(ECS 自建或是RDS),您可能希望做一次全面的性能测试,本文主要说明在测试前,我们需要提前考虑哪些先决条件。在测试之前,需要尽可能的保证二者具有相同的环境,如网络,实例... 那么应用与数据库之前的网络路径更短。# 实例规格本地自建数据库,与 ECS 自建数据库和 RDS实例请保持相同的 CPU 核数与内存大小。同时,磁盘性能需要重点考虑,主要有如下几点:1. 本地盘还是云盘,云盘的网络访问...
自建数据库与RDS性能对比注意事项
# 前言从 on-premise 数据库迁移到火山引擎(ECS 自建或是RDS),您可能希望做一次全面的性能测试,本文主要说明在测试前,我们需要提前考虑哪些先决条件。在测试之前,需要尽可能的保证二者具有相同的环境,如网络,实... 那么应用与数据库之前的网络路径更短。# 实例规格本地自建数据库,与 ECS 自建数据库和 RDS实例请保持相同的 CPU 核数与内存大小。同时,磁盘性能需要重点考虑,主要有如下几点:1. 本地盘还是云盘,云盘的网络访...
 特惠活动
特惠活动
 数据库和内存过程流程图-优选内容
数据库和内存过程流程图-优选内容
 数据库和内存过程流程图-相关内容
数据库和内存过程流程图-相关内容
自建数据库与RDS性能对比注意事项
# 前言从 on-premise 数据库迁移到火山引擎(ECS 自建或是RDS),您可能希望做一次全面的性能测试,本文主要说明在测试前,我们需要提前考虑哪些先决条件。在测试之前,需要尽可能的保证二者具有相同的环境,如网络,实例... 那么应用与数据库之前的网络路径更短。# 实例规格本地自建数据库,与 ECS 自建数据库和 RDS实例请保持相同的 CPU 核数与内存大小。同时,磁盘性能需要重点考虑,主要有如下几点:1. 本地盘还是云盘,云盘的网络访问...
自建数据库与RDS性能对比注意事项
# 前言从 on-premise 数据库迁移到火山引擎(ECS 自建或是RDS),您可能希望做一次全面的性能测试,本文主要说明在测试前,我们需要提前考虑哪些先决条件。在测试之前,需要尽可能的保证二者具有相同的环境,如网络,实... 那么应用与数据库之前的网络路径更短。# 实例规格本地自建数据库,与 ECS 自建数据库和 RDS实例请保持相同的 CPU 核数与内存大小。同时,磁盘性能需要重点考虑,主要有如下几点:1. 本地盘还是云盘,云盘的网络访...
一文读懂火山引擎云数据库产品及选型
> **火山引擎存储&数据库产品解决方案团队**,由资深的存储&数据库解决方案架构师组成。团队致力于帮助企业与组织更好的使用火山引擎云存储与云数据库产品,针对实际业务场景设计最优的解决方案,用专业技术助力组织和企业实现业务成功。## 为什么要做数据库选型### 数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软...
一文读懂火山引擎云数据库产品及选型
# 1、为什么要做数据库选型## 1.1、数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三... 那么也需要同时考虑数据库的可扩展性,通过扩展来获取更强的数据处理能力以及更大的数据存储空间,以保证业务应用可以平稳运行。| **数据模型** | **适用的数据库类型** | **主要特点** ...
一文读懂火山引擎云数据库产品及选型
为什么要做数据库选型 **数据库选型的重要性与难点**发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础... 那么也需要同时考虑数据库的可扩展性,通过扩展来获取更强的数据处理能力以及更大的数据存储空间,以保证业务应用可以平稳运行。数据模型:首先肯定会有一个基于page/blo...
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
Redis 拥有高性能的数据读写功能,被我们广泛用在缓存场景,一是能提高业务系统的性能,二是为数据库抵挡了高并发的流量请求,[点我 -> 解密 Redis 为什么这么快的秘密](https://mp.weixin.qq.com/s/z4VjDaDDbspFz1rIB... 由缓存抽象层来完成缓存数据和数据库数据的更新**,时序流程图如下: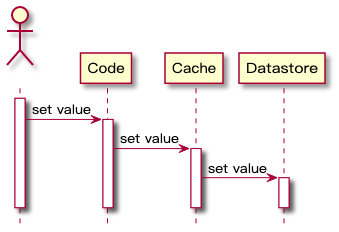`Write-Through` 的主要好处是应用系统的不需要...
VikingDB:大规模云原生向量数据库的前沿实践与应用
在内部产品的不断迭代过程中,VikingDB 也逐渐契合云原生的理念,为孵化商业化向量数据库产品打下了坚实的基础。依托于 VikingDB 在字节内部积累的丰富经验,我们在火山引擎推出了 VikingDB 的商业化版本,以更好地对外... 单机无法构建和服务整个索引,因此需要支持索引的分片,通过控制单分片的向量条数,来约束构建耗时和内存开销。在线服务为了加载并 serving 多分片索引,需要引入一定的状态编排调度机制。对于实时性需求,单靠全量索...
抖音大规模实践,火山引擎向量数据库是这样炼成的
在数据库中存储和对比的并不是图片和视频片段,而是通过深度学习等算法将其提取出来的“特征”,“特征”提取的过程称为 Embedding,提取出的“特征”用数学中的向量来表示。向量化的目的是为了通过向量相似来进行非结... 数量规模早已超出单机内存的极限,举个例子,对于1亿条128维的Float向量,不考虑任何辅助结构,就需要100000000 * 128 * 4 bytes 也就是约48GB的服务器内存。研发团队设计了一套存算分离的分布式系统架构,来进行向量...
