超市管理数据库流程图
 社区干货
社区干货
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
由缓存组件来管理自身与数据库之间的数据同步。**### 2.3 Write-Through 同步直写**与 Read-Through 类似,发生写请求时,Write-Through 将写入责任转移到缓存系统,由缓存抽象层来完成缓存数据和数据库数据的更新**,时序流程图如下: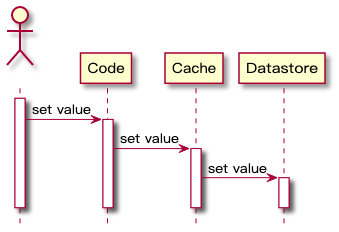`Write-Through` 的主要好处是应用系统的不需要考虑故障处理和重试逻辑,交给缓存抽象层来管理实...
一文读懂火山引擎云数据库产品及选型
数据库在所有IT系统中的地位都是重中之重。数据库作为基础软件的重要性不言而喻,各行各业的数字系统都离不开数据库系统。但不同行业特点不同,行业需求也就不同。面对着业界上百种数据库类型,到底应该如何根据自己的业务特征去选择最合适的数据库系统?这个问题非常的重要,因为如果数据库选择不合适,可能会让业务系统停摆,造成严重经济损失。所谓合适的数据库系统,不仅仅要满足业务需求,还要尽可能降低成本,减轻运维管理难度,满足...
一文读懂火山引擎云数据库产品及选型
数据库在所有IT系统中的地位都是重中之重。数据库作为基础软件的重要性不言而喻,各行各业的数字系统都离不开数据库系统。但不同行业特点不同,行业需求也就不同。面对着业界上百种数据库类型,到底应该如何根据自己的业务特征去选择最合适的数据库系统?这个问题非常的重要,因为如果数据库选择不合适,可能会让业务系统停摆,造成严重经济损失。所谓合适的数据库系统,不仅仅要满足业务需求,还要尽可能降低成本,减轻运维管理难度,满足...
火山引擎ByteHouse:分析型数据库如何设计并发控制?
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 分析型数据库设计并发控制的主要原因是为了确保数据的完整性和一致性,同时提高数据库的吞吐量和响应速度。并发控制可以... ByteHouse事务处理主要是对用户数据的元数据进行管理,元数据包括用户的db,table和part(part是数据文件的元数据,包括了part名字,columns,行数,状态,版本,提交时间等信息)。随着数据的增长,元数据本身数量级也会线性...
 特惠活动
特惠活动
 超市管理数据库流程图-优选内容
超市管理数据库流程图-优选内容
 超市管理数据库流程图-相关内容
超市管理数据库流程图-相关内容
揭秘|字节跳动基于Hudi的数据湖集成实践
这是最终的CDC数据导入流程图首先,不同的数据库会将Binlog发送到消息队列中,Flink任务会将所有数据转换成HoodieRecord格式,然后通过哈希索引找到对应的文件ID,通过一层对文件ID的shuffle后,数据到达了写入层,写... 这个平台会托管所有数据湖的运维管理,达到自我治理的一个状态,用户则不需要再为运维而烦恼。同时,我们希望提供自动化调优的功能,基于数据的分布找到最佳的配置参数,例如之前提到的不同索引之间的性能取舍问题,我...
字节跳动实时数据湖构建的探索和实践
主要用于将在线数据库导入到离线数仓,和不同数据源之间的批式传输。在2020年,我们基于Flink构造了MQ-Hive的实时数据集成通道,主要用于将消息队列中的数据实时写入到Hive和HDFS,在计算引擎上做到了流批统一。到... 这是最终的CDC数据导入流程图。首先,不同的数据库会将Binlog发送到消息队列中,Flink任务会将所有数据转换成HoodieRecord格式,然后通过哈希索引找到对应的文件ID,通过一层对文件ID的shuffle后,数据到达了写入层,写...
485天,远程办公的 21 条心得分享|社区征文
来管理的,上面可以根据标签来查看所有 Issue 的进度。如下图所示:#### 2.4.2 实施团队项目进度跟踪我们是有很多个定制开... 都是用**蓝湖**来统一管理。对于功能流程图、代码逻辑流程图,我们一般是用 **ProcessOn** 在线画图工具进行团队协作,该工具支持多人协作修改。### 4.2 跨公司的团队协作对于跨公司的团队协作,我们会拉钉钉群...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可... 最终的损失函数为loss_wc+loss_wo+loss_ws+loss_sel。模型的优化器可使用Adam优化器,是目前深度模型常用的优化器,包含两阶动量对梯度进行处理,其算法流程图如图五。 # 背景腾讯自选股App在增加了综合得分序的Feed流排序方式:需要每天把(将近1000W数据量)的feed流信息进行算分计算更新后回写到数据层。目前手上的批跑物理机器是16核(因为混部,无法独享CPU),同... [业务流程图.png](https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/f9026c5796404507b7104e3dec3346f7~tplv-k3u1fbpfcp-5.jpeg?)### 针对上述的业务逻辑,设计出了最初方案- 查询DB或者本地缓存获取索引f...
