深圳市数据库维护流程图
 社区干货
社区干货
一文读懂火山引擎云数据库产品及选型
因为如果数据库选择不合适,可能会让业务系统停摆,造成严重经济损失。所谓合适的数据库系统,不仅仅要满足业务需求,还要尽可能降低成本,减轻运维管理难度,满足业务未来的发展等等。这是个复杂的问题, 因为各行各业的... 简单说就是准备花多少钱建设与维护数据库系统。投入越多,可以获得更强的数据库能力,也可以聘请更专业的DBA进行数据库维护,保障数据库系统稳定运行。企业组织中越是重要核心的数据库系统,会获得更多的资源投入。D...
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
Redis 拥有高性能的数据读写功能,被我们广泛用在缓存场景,一是能提高业务系统的性能,二是为数据库抵挡了高并发的流量请求,[点我 -> 解密 Redis 为什么这么快的秘密](https://mp.weixin.qq.com/s/z4VjDaDDbspFz1rIB... 由缓存抽象层来完成缓存数据和数据库数据的更新**,时序流程图如下: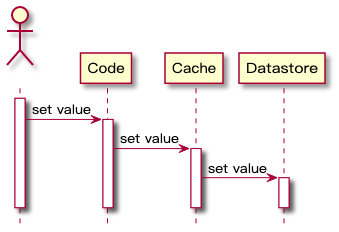`Write-Through` 的主要好处是应用系统的不需要...
一文读懂火山引擎云数据库产品及选型
数据库在所有IT系统中的地位都是重中之重。数据库作为基础软件的重要性不言而喻,各行各业的数字系统都离不开数据库系统。但不同行业特点不同,行业需求也就不同。面对着业界上百种数据库类型,到底应该如何根据自己的业务特征去选择最合适的数据库系统?这个问题非常的重要,因为如果数据库选择不合适,可能会让业务系统停摆,造成严重经济损失。所谓合适的数据库系统,不仅仅要满足业务需求,还要尽可能降低成本,减轻运维管理难度,满足...
一文读懂火山引擎云数据库产品及选型
因为如果数据库选择不合适,可能会让业务系统停摆,造成严重经济损失。所谓合适的数据库系统,不仅仅要满足业务需求,还要尽可能降低成本,减轻运维管理难度,满足业务未来的发展等等。这是个复杂的问题, 因为各行各业的... 简单说就是准备花多少钱建设与维护数据库系统。投入越多,可以获得更强的数据库能力,也可以聘请更专业的 DBA 进行数据库维护,保障数据库系统稳定运行。企业组织中越是重要核心的数据库系统,会获得更多的资源投入。...
 特惠活动
特惠活动
 深圳市数据库维护流程图-优选内容
深圳市数据库维护流程图-优选内容
 深圳市数据库维护流程图-相关内容
深圳市数据库维护流程图-相关内容
揭秘|字节跳动基于Hudi的数据湖集成实践
这是最终的CDC数据导入流程图首先,不同的数据库会将Binlog发送到消息队列中,Flink任务会将所有数据转换成HoodieRecord格式,然后通过哈希索引找到对应的文件ID,通过一层对文件ID的shuffle后,数据到达了写入层,写... 这个平台会托管所有数据湖的运维管理,达到自我治理的一个状态,用户则不需要再为运维而烦恼。同时,我们希望提供自动化调优的功能,基于数据的分布找到最佳的配置参数,例如之前提到的不同索引之间的性能取舍问题,我...
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可... 最终的损失函数为loss_wc+loss_wo+loss_ws+loss_sel。模型的优化器可使用Adam优化器,是目前深度模型常用的优化器,包含两阶动量对梯度进行处理,其算法流程图如图五。 