C写入时间不一致
 社区干货
社区干货
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
因此初次调用的数据请求响应时间会增加一些开销,因为需要额外的缓存填充和数据库查询耗时。#### 2.1.2 更新数据使用 `cache-aside` 模式写数据时,如下流程。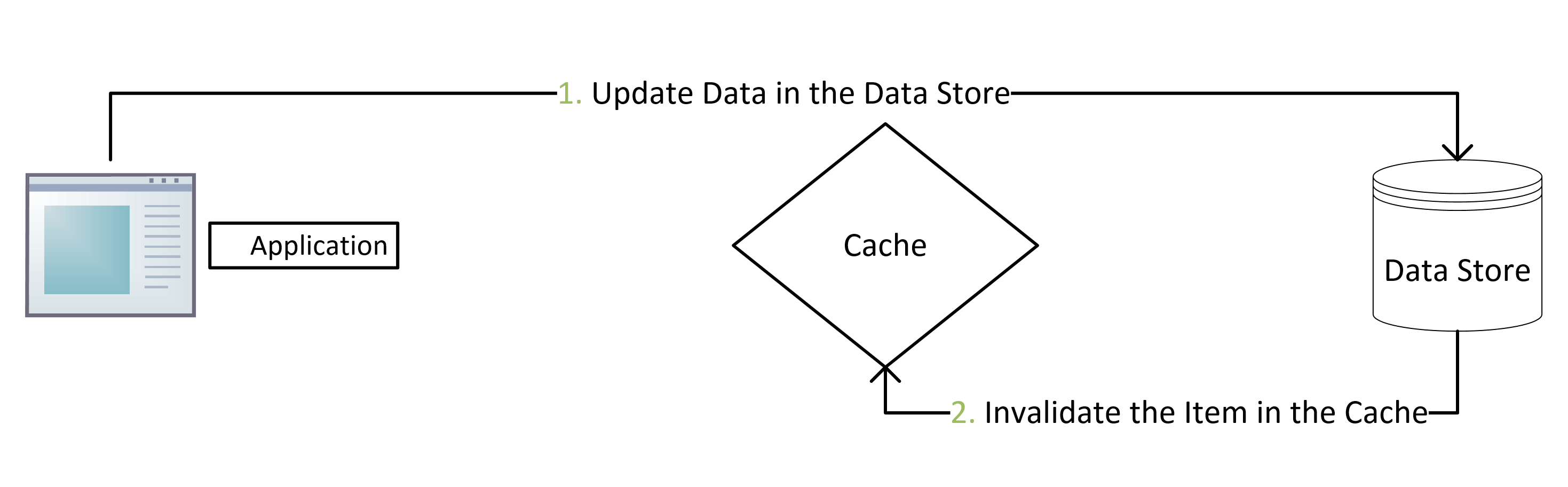1. 写数据到数据库;2. 将缓存中的数据失效或者更新缓存数据;使用 `cache-aside` 时,最常见的写入策略是直接将数据写入数据库,但是缓存可能会与数据库不一致。我们...
干货|从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
=&rk3s=8031ce6d&x-expires=1714407631&x-signature=3%2B9mDfnN64TqjgzZTqGTPMoCM34%3D)**最终方案及效果**由于外部写入并不可控和技术栈上的原因,我们最终采用了 **Kafka Engine** 的方案,也就是 ... 也可以从 Hive 把数据导入至 ClickHouse 中,除此之外,业务方还会将 1% 抽样的离线数据导入过来做一些简单验证,1% 抽样的数据一般会保存更久的时间。除了技术选型和实现方案,我们在支持推荐系统的实时数据时遇到...
字节跳动极高可用 KV 存储系统详解
但这段时间内服务会受影响。另一种处理极端故障的方法是 **搭建多活模式集群,通过中间件同步数据** 。但这种方案存在的问题是集群间数据难以保障最终一致性,一旦数据有冲突就会对用户造成困扰。 Abase 2.0 应对业务高可用挑战的解决方案 **Abase 2.0 架构**我们的思路源于 Dynamo 多年前的一篇论文中做到了极致高可用的 Column 读写方案。但这一方案又不完全满足我们的需求,我们提出...
干货|解析开源OLAP引擎基于共享存储的选主方式
ByConity 是由字节跳动开源的云原生数仓,采用了存储计算分离的架构,支持主流的 OLAP 引擎优化技术,实现了租户资源隔离、弹性扩缩容,并具有数据读写的强一致性等特性。 **「基于共享存储的选主方式」** 作为 ByCon... ByConity 实现过一个使用固定的共享域名来代替给每个 keeper 节点配置地址的方案,但又进一步带来了处理 域名解析的可访问节点数量和 keeper 中配置数量不一致时的复杂性。 3.容器重启后如果服务变换...
 特惠活动
特惠活动
 C写入时间不一致-优选内容
C写入时间不一致-优选内容
 C写入时间不一致-相关内容
C写入时间不一致-相关内容
字节跳动 NoSQL 的探索与实践
但这个过程有一定的时间延迟。BASE 理论是对 CAP 中 AP 理论的扩展,通过牺牲强一致性获得可用性。当出现故障时,允许部分不可用,但能保证核心功能可用;允许数据在一段时间内不一致,但最终要达到一致。NoSQL 大致... 为了满足内部 social graph 在线增删改查的场景,字节跳动自研了分布式图存储数据库 ByteGraph。针对刚才提到的图状数据结构,ByteGraph 支持有向属性的图数据模型、Gremlin 查询语言以及丰富的写入和查询接口,具有海...
一口气看完43个关于 ElasticSearch 的使用建议
Cache=false 等。另外一些存在不确定性的查询例如:范围查询带有 Now,由于它是毫秒级别的,缓存下来没有意义,类似的还有在脚本查询中使用了 Math.random() 等函数的查询也不会进行缓存。当有新的 Segment 写入到分... 只返回聚合结果而不返回文档 sourceBuilder.size(0);```**03. 日期范围查询使用绝对时间值。**日期字段上使用 Now,一般来说不会被缓存,因为匹配到的时间一直在变化。因此, 可以从业务的角度来考虑是否一...
字节跳动 NoSQL 的探索与实践
数据同步中等,在数据达到最终一致的状态后才改为成功。* **Eventually Consistent**:指经过一段时间后所有节点的数据将会达到一致。比如最终支付中的状态会变成支付成功或者支付失败;订单的状态和实际交易的过程达成一致;但这个过程有一定的时间延迟。BASE 理论是对 CAP 中 AP 理论的扩展,通过牺牲强一致性获得可用性。当出现故障时,允许部分不可用,但能保证核心功能可用;允许数据在一段时间内不一致,但最终要达到一致。...
从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
也可以从 Hive 把数据导入至 ClickHouse 中,除此之外,业务方还会将 1% 抽样的离线数据导入过来做一些简单验证,1% 抽样的数据一般会保存更久的时间。除了技术选型和实现方案,我们在支持推荐系统的实时数据时遇到过不少问题,其中最大的问题随着推荐系统产生的数据量越来越大,单个节点的消费能力也要求越来越大,主要碰到如下问题:**问题一:写入吞吐量不足****挑战**:在有大量辅助跳数索引的场景下,索引的构建严重影响写...
干货|火山引擎DataTester:A/B实验平台数据集成技术分享
确定导入时间范围、修改业务处理逻辑、代码编写、测试环境调试...... Hudi 表由 timeline 和 file group 两大项构成。Timeline 由一个个 commit 构成,一次写入过程对应时间线中的一个 commit,记录本次操作修改的文件。相较于传统数仓,Hudi 要求每条记录必须有唯一的主键,并且同分区内,相同主键只存在在一个 file group 中。底层存储由多个 file group 构成,有其特定的 file ID。File group 内的文件分为 base ...
干货丨字节跳动基于 Apache Hudi 的湖仓一体方案及应用实践
基于时间戳维护数据版本。通过 filegroup 的方式对文件进行分组,相同逐渐的数据存储在同一个文件组内。后期结合数据构建索引能力,能够比较大幅度提升数据入湖和查询的性能。 架构的第二层是元数据层。对数据湖的元数据进行管理,包括表、分区以及 instant、timeline、snapshot 等这些数据湖特有的元数据。在 **这一层不光实现了元数据的管理,还能够解决多并发写入的冲突检查和解决,保障 ACID 能力** 。 架构的第...
Flink 替换 Logstash 解决日志收集丢失问题
=&rk3s=8031ce6d&x-expires=1714407637&x-signature=xvyUy2CxkUmUozG4kvb2aoFNsF0%3D)在某客户日志数据迁移到火山引擎使用 ELK 生态的案例中,由于客户反馈之前 Logstash 经常发生数据丢失和收集性能较差的使用痛点,我们尝试使用 Flink 替代了传统的 Logstash 来作为日志数据解析、转换以及写入 ElasticSearch 的组件,得到了该客户的认可,并且已经成功协助用户迁移到火山。目前,Flink 已经支持该业务高峰期 1000+k/s 的数据写...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.05
每个节点时间都有实时监控,如果产生延迟和破线情况,会推动业务登记。