开源的对象化存储工具
 社区干货
社区干货
干货|解析开源OLAP引擎基于共享存储的选主方式
[picture.image](https://p3-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/cd1bea40bcf24f6bba73e68d10a83887~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1714666836&x-signature=N4ir8po00tgbIjoVhhs1KBBDYfQ%3D) ByConity 是由字节跳动开源的云原生数仓,采用了存储计算分离的架构,支持主流的 OLAP 引擎优化技术,实现了租户资源隔离、弹性扩缩容,并具有数据读写的强一致性等特性。 **「基于...
云原生之旅:一年的变革、成长与启示|社区征文
Kubernetes是一个开源的容器编排系统,它提供了自动化部署、弹性扩展、自我修复等功能,帮助开发者更好地管理容器化应用程序。Kubernetes的核心概念包括节点、Pod、Service、Deployment等,通过这些概念可以构建和管理... 共享一些网络和存储资源。(3)Service:Service为Pod提供负载均衡和可持续性,它可以将多个Pod映射到一个公共IP地址上。(4)Deployment:Deployment是用于部署和管理Pod的控制器,它提供了声明式API和滚动更新功能。...
字节跳动宣布开源 KubeWharf,一个实践驱动的云原生项目集
工具和最佳实践。来源 | 字节跳动基础架构在 7 月 23 日稀土开发者大会上,字节跳动宣布 KubeWharf 项目正式开源。KubeWharf 是字节跳动基础架构团队在对 Kubernetes 进行了大规模应用和不断优化增强之后的技术结晶。这是一套以 Kubernetes 为基础构建的分布式操作系统,由一组云原生组件构成,专注于提高系统的可扩展性、功能性、稳定性、可观测性、安全性等,以支持大规模多租集群、在离线混部、存储和机器学习云原生化等场景...
Bio-OS 开源开放大赛—论文复现示例
在Bio-OS中数据可以上传到Workspace所对应的对象存储中(创建Workspace时会创建一一对应的对象存储桶),并通过配置密钥实现Notebook对对象存储的直接访问。1. 进入Workspace,点击【数据】-【文件列表】1. 选择文... 选择R/Bioconductor基础镜像容器(镜像选择基于论文复现所需要的工具,示例论文主要用到了Bioconductor中相关工具包)  特惠活动
特惠活动
 开源的对象化存储工具-优选内容
开源的对象化存储工具-优选内容
 开源的对象化存储工具-相关内容
开源的对象化存储工具-相关内容
云原生环境下的日志采集、存储、分析实践
开源系统的采集配置难以管理,数据源也比较单一。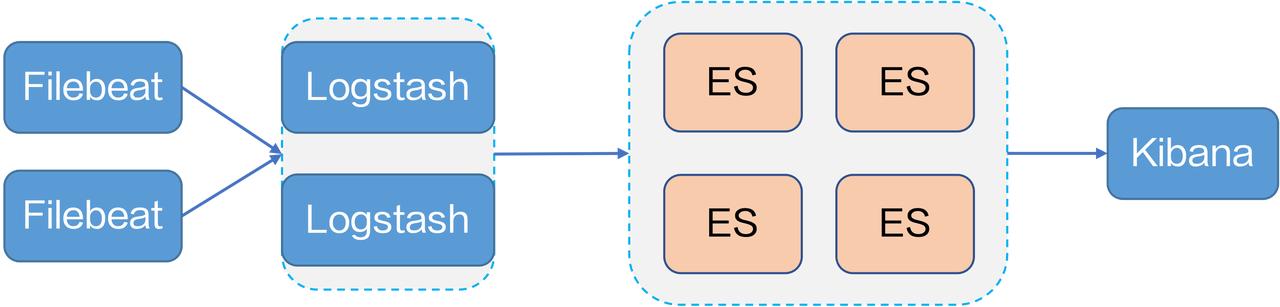### Kubernetes 下的日志采集Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的文件。- Str...
免费公测|火山引擎大数据文件存储公测现已开启!
在云计算、人工智能、物联网等技术发展迅速的今天,海量数据的规模化增长成为常态。当前行业通用的存储方案也面临巨大挑战。而随着云原生的逐渐兴起,原有的存算一体架构越来越多地暴露出弊端:1. 计算资源和存储资... 2. **易使用**:支持完整的 HDFS 语义,兼容开源大数据生态,支持业务无缝上云。同时可与火山引擎 流式计算 Flink、批式计算 Spark、云原生消息引擎深度集成,提供端到端的 Serverless 大数据计算及存储解决方案。 3....
云原生环境下的日志采集、存储、分析实践
存储、查询、分析、可视化、告警以及消费投递,将日志的生命周期进行闭环。 Kubernetes 下日志采集的开源自建方案 **开源自建**火山引擎早期为了快速上线业务,各团队基于开源项目搭建了自己的日志系统,以满足基本的日志查询需求,例如使用典型的开源日志平台 **Filebeat+Logstash+ES+Kibana** 的方案。但是在使用过程中,我们发现了开源日志系统的不足:* 各业务模块自己搭建日志系统,造成...
KubeWharf:解析云原生未来的分布式操作系统|社区征文
成为云原生领域备受瞩目的开源项目。它以一组云原生组件为基础,专注于提升系统的可扩展性、功能性、稳定性、可观测性以及安全性,以满足大规模多租集群、离线混部、云原生存储和机器学习等多样化场景的需求。在这篇... 存储和机器学习技术,而 KubeWharf 的云原生组件集成了这些技术,使用户能够更好地构建和部署这些复杂的应用。云原生存储的需求包括高性能、高可用性和弹性,而 KubeWharf 提供了相应的功能和工具,使得存储服务能够适...
云原生环境下的日志采集、存储、分析实践
开源系统的采集配置难以管理,数据源也比较单一。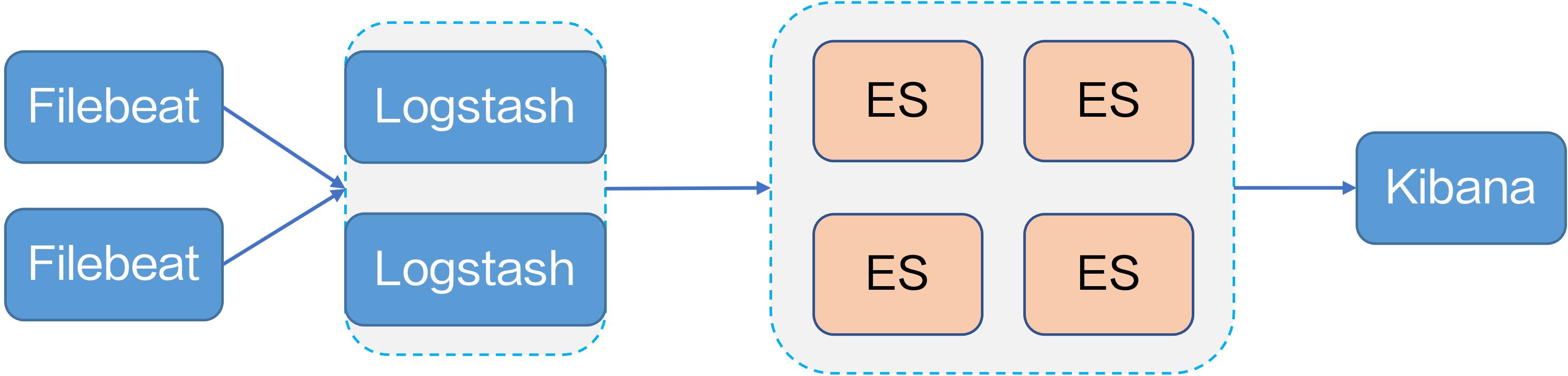### Kubernetes 下的日志采集Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的...
字节跳动基于 Iceberg 的海量特征存储实践
**字节跳动特征存储痛点**当前行业内的特征存储整体流程主要分为以下四步: