jvm对象存储结构
 社区干货
社区干货
关于大数据计算框架 Flink 内存管理的原理与实现总结 | 社区征文
对象序列化二进制存储,下面在来详细介绍下flink内存管理。## 完全JVM内存管理存在的问题基于JVM的数据分析引擎都需要面对将大量数据存到内存当中,就不得不面对JVM存在的几个问题:- java对象存储密度低:比如... 因为Java对象及jvm内存管理存在的问题,flink针对这些问题基于jvm进行了优化, Flink内存管理主要会涉及内存管理、定制的序列化工具、缓存友好的数据结构和算法、堆外内存、JIT编译优化。Flink并不是将大量对象存在堆...
JVM类加载读取class文件的机制
它们可以帮助我们更好地理解JVM类加载机制的原理和过程:- 类加载器:Java虚拟机大多使用双亲委派模型来实现类加载机制,它使用一系列多级联类加载器来完成类加载中的各种验证和转换工作。- 类型描述符:每个类都有一个关联的类型描述符,它用来描述类的字节码信息,包括类的继承关系、域、方法等。- 元空间:元空间是JVM运行时内存中用于存储已加载的类信息的一部分,它可以用来实现从类文件到内存的映射。 ## 二、JVM类加载机制...
打造通用缓存层:字节跳动 Flink StateBackend 性能提升之路
**FsStateBackend** 底层实现是在内存中通过 Map 的数据结构来存储数据,把原始的数据对象直接存储到内存中。这种 StateBackend 的优点是访问速度特别快,所有操作都是在内存中进行,基本没有额外的 CPU 开销。缺点是随着状态规模的增长,JVM 的 GC 停顿时间也会越来越长,同时状态规模会受到内存的限制。**RocksDBStateBackend** 底层选用了 RocksDB 来存储数据,存储的状态规模理论上受限于磁盘,序列化后的结果也会比以 Object 的形...
策略模式 之 一键切换云存储方式|社区征文
我们需要去对应的云服务厂商开通对象存储服务,然后获取到`accessKey`、`accessKeySecret`、`endpoint`、`bucket`、`domainUrl`等必须的参数。> 因为这些信息基本是不会发生改变,所以我们可以将这些信息存储在配置... * 构造器注入bean */ private final ObjectStoreProperties properties; /** * 当前类的属性 */ private OSS ossClient; @Override public void initClient() { ...
 特惠活动
特惠活动
 jvm对象存储结构-优选内容
jvm对象存储结构-优选内容
 jvm对象存储结构-相关内容
jvm对象存储结构-相关内容
打造通用缓存层:字节跳动 Flink StateBackend 性能提升之路
**FsStateBackend** 底层实现是在内存中通过 Map 的数据结构来存储数据,把原始的数据对象直接存储到内存中。这种 StateBackend 的优点是访问速度特别快,所有操作都是在内存中进行,基本没有额外的 CPU 开销。缺点是随着状态规模的增长,JVM 的 GC 停顿时间也会越来越长,同时状态规模会受到内存的限制。**RocksDBStateBackend** 底层选用了 RocksDB 来存储数据,存储的状态规模理论上受限于磁盘,序列化后的结果也会比以 Object 的形...
策略模式 之 一键切换云存储方式|社区征文
我们需要去对应的云服务厂商开通对象存储服务,然后获取到`accessKey`、`accessKeySecret`、`endpoint`、`bucket`、`domainUrl`等必须的参数。> 因为这些信息基本是不会发生改变,所以我们可以将这些信息存储在配置... * 构造器注入bean */ private final ObjectStoreProperties properties; /** * 当前类的属性 */ private OSS ossClient; @Override public void initClient() { ...
对象存储创建同名桶限制变更公告
存储桶的名字全局唯一,如果您创建了某个名称的存储桶,任何用户将无法再创建同名的存储桶。如果您需要创建同名的存储桶,您需要将源存储桶删除后才可创建。为了保证业务的安全性和稳定性,火山引擎对象存储产品将于 2024 年 04 月 22 日变更创建同名存储桶的限制,删除存储桶后,需要等待一段时间(通常为 30 分钟)之后才可以创建同名的存储桶。 预计变更时间2024 年 04 月 22 日,具体时间请以控制台上线为准。 变更说明变更前:删除存储...
「跨越障碍,迈向新的征程」盘点一下2022年度我们开发团队对于云原生的技术体系的变革|社区征文
并允许用户以可移植的方式在任何 Kubernetes 环境和支持的存储提供程序上合并快照操作。6. **【容器能力扩展】在v1.20版本开始它移除 dockershim** ,从而就实现了可以扩展为其他容器实现的急促> tips:维护dock... 而我们的JVM参数是1.8G。这会导致我们JVM都crash了,这边还没有达到预警呢!所以这边我...
替换 Spring Cloud,使用基于 Cloud Native 的服务治理
Spring Cloud 虽然是 JVM 体系,但是离开了 JVM 很多事情都做不了,因此不得不逼迫客户随着一起做变动,这个体验其实不太好。所以我们后面也说服了同公司的一些团队一起参与到 CNCF 云原生技术架构的建设。## Sprin... 有了多运行时架构,会发现一个很大的变化:一旦业务单元变得足够小,我们只需要去写业务本身,进行数据的读取和存储就可以了。这时如果想获得额外的服务发现、熔断、配置管理等服务,只需要在外围添加这些能力即可。大...
OLAP 在火山 EMR 的最佳实践
基于火山的对象存储,做了弹性存算分离的架构,同时,也自研了透明加速的能力,引入Job Committer逻辑;提供冷热分层,通过表查询做行为HOOK,形成自动的数据冷热判断,进行数据自动的冷热迁移;- 实时数仓:这个场景是今... 存放近3个月的数据,用于在线报表查询;在线和离线数据存储在不同地方,读取离线数据需要先读取到在线存储中。客户核心痛点:实时性及查询性能问题,原有Gp模式需每15分钟批量写入最新数据到在线数据存储;实时更新能力...
基于Prometheus的企业级监控体系探索与实践|社区征文
告警信息持久化存储等能力。## 通过服务发现简化运维Prometheus提供多种客户端配置方式,包括服务发现,静态文件等。在目前云原生环境下,应用具备高度弹性,通过静态配置监控目标的行为是多么的低效。所以我们要尽可能的通过服务发现来管理客户端列表。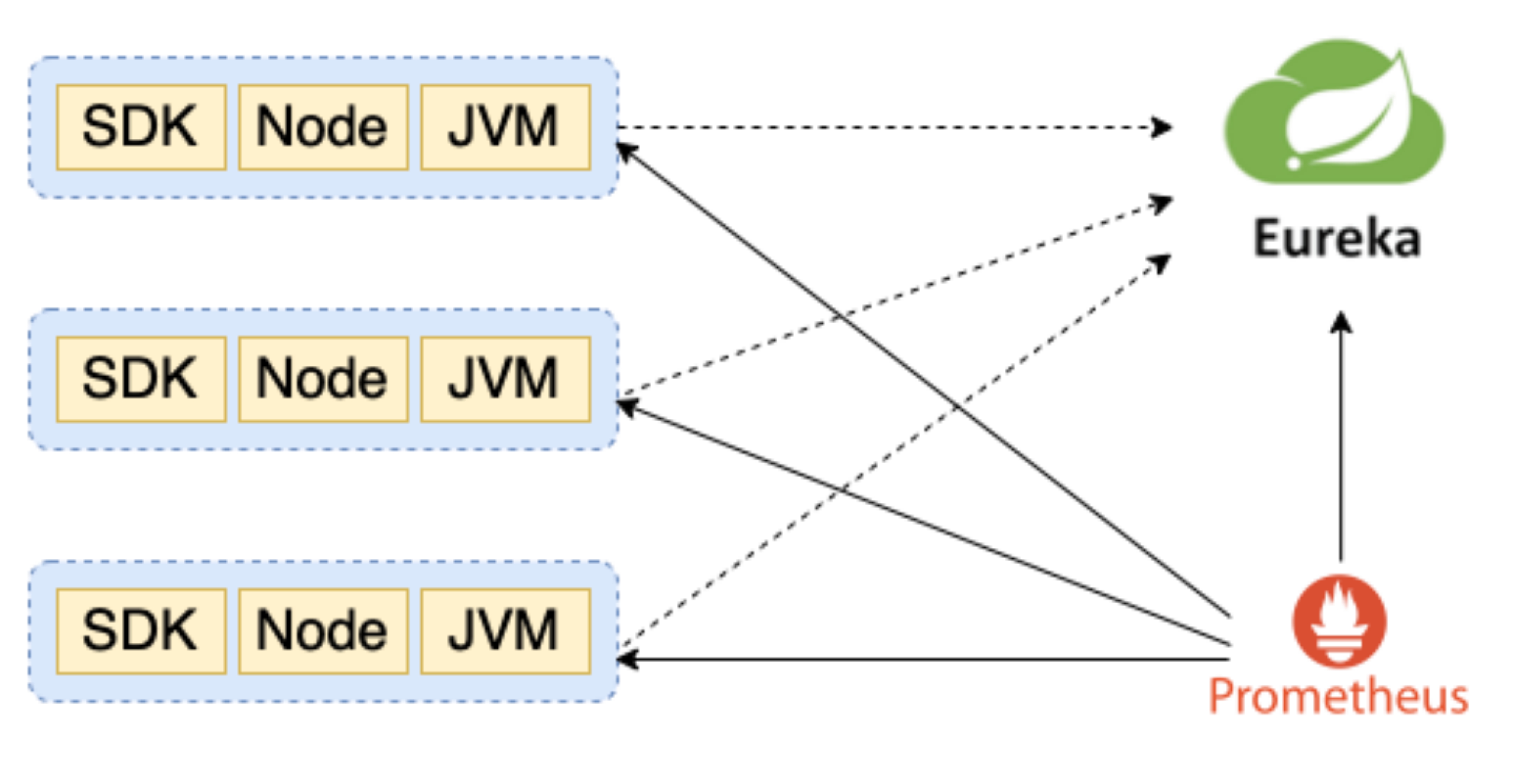借助于架构转型,全行使用统一的spr...
什么是对象存储 TOS
火山引擎对象存储 TOS(Tinder Object Storage)是火山引擎提供的海量、安全、低成本、易用、高可靠、高可用的分布式云存储服务。您可以通过 RESTful API 接口、SDK 和工具等多种形式使用火山引擎 TOS。通过网络,您可以在任何应用、任何时间、任何地点管理和访问火山引擎 TOS 上的数据。 产品优势规模海量 火山引擎 TOS 通过自研分布式对象存储技术,通过领先的架构与技术支持,目前内部部署对象存储机器万台规模,存储规模超过 EB。传...
如何使用函数服务实现对象存储同步刷新CDN
前言本实验使用函数服务,实现对象存储资源删除、上传时自动调用刷新CDN缓存的接口。 关于实验预计部署时间:20分钟 级别:初级 相关产品:函数服务、对象存储、内容分发网络 受众: 通用 实验说明点击此链接登录控制台... 同时需要初始化签名结构体。一些签名计算时需要的属性也在这里处理。 初始化身份证明结构体 credential = { "access_key_id": ak, "secret_access_key": sk, "service": Service, ...
