重试已确认消息
 社区干货
社区干货
Kafka 消息传递详细研究及代码实现|社区征文
发送了一条/批消息之后,需要什么条件或者需要等待多久才能发送下一条消息呢,发送失败会重试吗?......Kafka Documentation 中 *[Producer Configs](https://kafka.apache.org/documentation/#producerconfigs)* ... producer 在确认一个请求发送完成之前需要收到的反馈信息。这个参数是为了保证发送请求的可靠性。acks = 0:producer 把消息发送到 broker 即视为成功,不等待 broker 反馈。该情况吞吐量最高,消息最易丢失acks ...
Redis 使用 List 实现消息队列有哪些利弊?|社区征文
消息队列是一种异步的服务间通信方式,适用于分布式和微服务架构。消息在被处理和删除之前一直存储在队列上。每条消息仅可被一位用户处理一次。消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高峰期工作负载。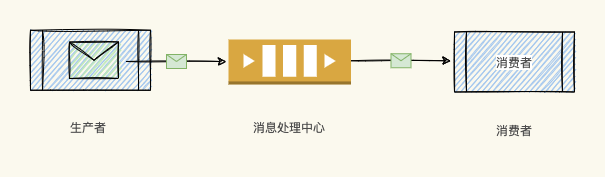- Producer:消息生产者,负责产生和发送消息到 Broker;- Broker:消息处理中心。负责消息存储、确认、重试等,一...
字节跳动基于Apache Atlas的近实时消息同步能力优化 | 社区征文
延迟消息 | 支持将消息标记为延迟处理,最高延迟1 min || 重试 | 自动对处理失败消息重试,重试次数可定义 || 并... 我们不确认客户环境一定有Flink集群,即使部署的数据底座中带有Flink,后续的维护也是个头疼的问题。另外一个角度,作为通用流式处理框架,Flink的大部分功能我们并没有用到,对于单条消息的流转路径,其实只是简单的读取...
干货|字节跳动基于Apache Atlas的近实时消息同步能力优化
延迟消息 | 支持将消息标记为延迟处理,最高延迟1 min || 重试 | 自动对处理失败消息重试,重试次数可定义 || 并行与顺序处理 | Partition内部支持按照某个Key重新分组,不同Key之间接受并行,同一个Key要求顺序处理... 我们不确认客户的环境一定有Flink集群,即使部署的数据底座中带有Flink,后续的维护也是个头疼的问题。另外一个角度,作为通用流式处理框架,Flink的大部分功能其实我们并没有用到,对于单条消息的流转路径,其实只是简单...
 特惠活动
特惠活动
 重试已确认消息
-优选内容
重试已确认消息
-优选内容
 重试已确认消息
-相关内容
重试已确认消息
-相关内容
迁移至火山引擎版 Redis
前提条件已创建缓存数据库 Redis 版数据库和设置默认账号 default 的密码。详细操作,请参见创建实例和设置默认账号密码。 创建数据迁移任务之前,请确认源库和目标库的网络连通性与服务可用性。 (可选)根据预检查... 关于缓存数据库 Redis 企业版的详细信息,请参见什么是缓存数据库 Redis 企业版。 使用限制类型 说明 源库限制 带宽要求:源库所属的服务器需具备足够出口带宽,否则将影响数据迁移的速率。 当源库中的某些 Key 使...
重试迁移任务
在迁移任务出现问题或故障导致任务中断时,您可以在定位问题并解决故障后通过重试任务来继续执行数据迁移。本文介绍如何在数据库传输服务 DTS 控制台重试迁移任务。 前提条件已创建数据迁移任务,且任务状态处于迁移... 重试任务登录 DTS 控制台。 在顶部菜单栏的左上角,选择项目和地域。 在左侧导航栏,单击数据迁移。 在迁移任务列表页面,勾选需要重试的迁移任务,在底部菜单栏,单击批量重试。 在重试任务对话框,单击确定。 在重...
重试同步任务
若同步任务出现问题或故障导致任务中断,您可以在定位问题并解决故障后通过重试任务来继续执行数据同步。本文介绍如何在数据库传输服务 DTS 控制台重试同步任务。 前提条件已创建数据同步任务,且任务状态处于同步失... 批量重试任务登录 DTS 控制台。 在顶部菜单栏的左上角,选择项目和地域。 在左侧导航栏,单击数据同步。 在数据同步列表页面,勾选需要重试的任务,在底部菜单栏,单击批量重试。 在重试任务对话框,单击确定。 在...
运行流水线
持续交付流水线支持 Webhook 触发、定时触发、手动触发 3 种触发规则,您可以根据具体使用场景,选择合适的方式来触发流水线运行。本文为您介绍手动触发流水线运行的操作步骤。 背景信息支持指定分支运行流水线、指定 Tag 运行流水线、指定 Commit ID 运行流水线,请按需选择。 流水线运行过程中,支持随时终止。终止后当前运行任务立即取消,未执行任务停止执行。 流水线某任务运行失败后,流水线停止运行。支持从失败任务重试,前序已...
同步至公网自建 ElasticSearch
本场景介绍如何在数据库传输服务 DTS 控制台创建火山引擎版 veDB MySQL 同步至公网自建 ElsticSearch 任务。 前提条件已创建云数据库 veDB MySQL 版实例和数据库。详细信息,请参见创建 veDB MySQL 实例和创建数据库... 已确认源端和目标端的网络连通性与服务可用性。 (可选)根据预检查项中的说明,检查源端和目标端中各同步对象。更多详情,请参见预检查项(MySQL) 和预检查项(ElasticSearch)。 注意事项在库表结构初始化过程中,数...
迁移至火山引擎版 MongoDB
前提条件已创建文档数据库 MongoDB 版实例和账号。详细操作,请参见创建实例和创建账号。 按需设置源端信息,具体如下所示: 在使用 VPN 实现数据迁移时,自建数据库所属的本地网络已通过 VPN 网关接入火山引擎。详细... 已确认源端和目标端的网络连通性与服务可用性。 (可选)根据预检查项中的说明,检查源端和目标端中各迁移对象。更多详情,请参见预检查项(MongoDB)。 注意事项若未选中增量迁移,数据迁移期间请勿在源实例中写入新...
ListModelCustomizationJobs - 获取模型调优任务列表
获取模型调优任务列表 请求参数下表仅列出该接口特有的请求参数和部分公共参数。更多信息请见公共参数。 参数类型是否必填示例值描述ActionString是ListModelCustomizationJobs 要执行的操作,取值:ListModelCustom... 模型微调任务在所属队列中的当前位次 RetryCountInteger模型微调任务已经失败重试的次数 MessageString对当前模型微调任务所处状态的解释性信息 OutputExpiredTimeString模型微调产物(如果有)计划过期的时间戳 Res...
同步至火山引擎版 MongoDB
按需设置源端端信息,具体如下所示: 在使用 VPN 实现数据同步时,自建数据库所属的本地网络已通过 VPN 网关接入火山引擎。详细操作,请参见搭建云上VPC与云下多数据中心网络互通。 在需要使用专线实现数据同步时,您需要搭建云上单私有网络和云下单数据中心网络连通的专线连接。详细操作,请参见配置专线连接。 已确认源端和目标端的网络连通性与服务可用性。 (可选)根据预检查项中的说明,检查源端和目标端中各同步对象。更多详...
同步至火山引擎版 MySQL
已确认源端和目标端的网络连通性与服务可用性。 (可选)根据预检查项中的说明,检查源端和目标端中各同步对象。更多详情,请参见预检查项(MySQL)。 注意事项当源端为自建 MySQL 时,您需要关注以下信息: 同步时,如... 然后单击确定。 说明 当同步类型勾选了全量初始化时,不支持此步骤。 在同步类型同时勾选了全量初始化和增量同步时,同步起始点默认为当前时间点且不支持修改。 GTID、GTID_EXECUTED 必须是源端合法的值,否则预检...
