AD服务器连接错误(LDAP)ETIMEOUT
 社区干货
社区干货
golang pprof
这种情况下直接使用runtime包的pprof工具来采集进程的性能数据是最方便,直接在进程运行中持续写入pprof文件或者在结束后将各项性能数据写入文件即可。2. net/http/pprof对应的场景是在线的程序,一般需要持续运... ("/debug/pprof/trace", Trace)}//...```> 注意,一般来说,在真正的线上服务里,为了与我们的对外服务端口隔离开,要用一个新的端口(debug port)来作为pprof的端口。编译程序后直接运行,访问`http://localho...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
但Livy更像一个Spark 服务器,而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难满足日常的业务开... 也就是说JavaEE里面仅仅定义了使用Java访问存储介质的标准流程,具体的实现需要依靠周边的第三方服务实现。 例如,访问MySQL的mysql-connector-java启动包,即基于java.sql包下定义的接口,实现了如何去连接MySQL的...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
**阿里云服务器连接**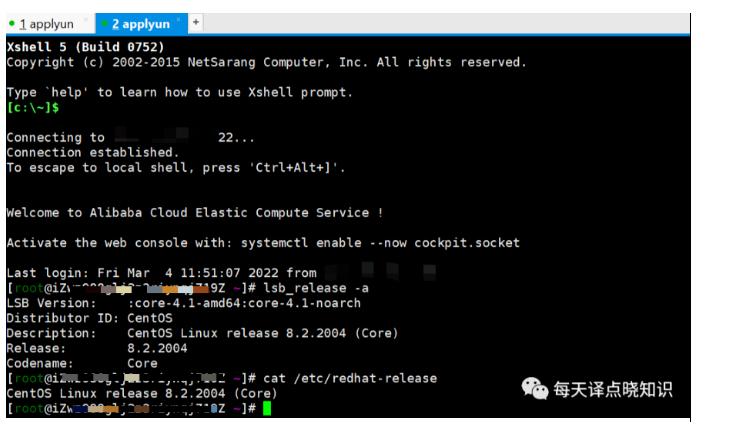 **附注:** 从上述可知,当前云主机的发行版本为CentO... 若是对于系统访问并发高,业务数据量非常之大的话,除了系统前后台代码本身质量优化之外,服务器配置(物理机or虚拟机or云主机)还可选择更高配些! Ok,now,有了这些前提条件,接下来开始**安装部署**我们**译点笔记...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难满足日常的业务开发需求,具体的分析请查看:[观点|SparkSQL在企业级数仓建设的优势](http://mp.weixin.qq.com/s?__biz=MzkwMzMwOTQwMg==&mid=2247490308&idx=1&sn=e83823427536f3c58fd226829593c969&chksm=c0996a31f7eee327ec4886d53676d207633e0637620bfc19adba...
 特惠活动
特惠活动
 AD服务器连接错误(LDAP)ETIMEOUT
-优选内容
AD服务器连接错误(LDAP)ETIMEOUT
-优选内容
 AD服务器连接错误(LDAP)ETIMEOUT
-相关内容
AD服务器连接错误(LDAP)ETIMEOUT
-相关内容
WindowsAD 下游同步
服务器地址 是 Windows AD 服务器域名或 IP 地址,必须使用 LDAPS 协议。 管理员账号 是 连接 Windows AD 域服务器的用户,必须是超级管理员,有创建、修改、删除域条目的权限。 管理员密码 是 连接 Windows AD 域服务器的用户密码。 用户对象类 是 在 Windows AD 服务器搜索的目标目录下,用户的过滤条件,支持过滤语法。 组织对象类 是 在 Windows AD 服务器搜索的目标目录下,组织的过滤条件,支持过滤语法。 Base DN...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
但Livy更像一个Spark 服务器,而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难满足日常的业务开... 也就是说JavaEE里面仅仅定义了使用Java访问存储介质的标准流程,具体的实现需要依靠周边的第三方服务实现。 例如,访问MySQL的mysql-connector-java启动包,即基于java.sql包下定义的接口,实现了如何去连接MySQL的...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
**阿里云服务器连接** **附注:** 从上述可知,当前云主机的发行版本为CentO... 若是对于系统访问并发高,业务数据量非常之大的话,除了系统前后台代码本身质量优化之外,服务器配置(物理机or虚拟机or云主机)还可选择更高配些! Ok,now,有了这些前提条件,接下来开始**安装部署**我们**译点笔记...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难满足日常的业务开发需求,具体的分析请查看:[观点|SparkSQL在企业级数仓建设的优势](http://mp.weixin.qq.com/s?__biz=MzkwMzMwOTQwMg==&mid=2247490308&idx=1&sn=e83823427536f3c58fd226829593c969&chksm=c0996a31f7eee327ec4886d53676d207633e0637620bfc19adba...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
而不是SparkSQL服务器,因此无法支持类似BI工具或者JDBC这样的标准接口进行访问。虽然Spark 提供Spark Thrift Server,但是Spark Thrift Server的局限非常多,几乎很难满足日常的业务开发需求,具体的分析请查看:[观点|SparkSQL在企业级数仓建设的优势](http://mp.weixin.qq.com/s?__biz=MzkwMzMwOTQwMg==&mid=2247490308&idx=1&sn=e83823427536f3c58fd226829593c969&chksm=c0996a31f7eee327ec4886d53676d207633e0637620bfc19adbad...
云原生时代,如何从 0 到 1 构建 K8s 容器平台的 LB(Nginx)负载均衡体系|社区征文
大型互联网公司全都拥抱 Kubernetes,没有其他方案可以与 Kubernetes 匹敌。所有业务(尤其是高并发业务)的访问必然要通过负载均衡 LB 代理层,服务端高并发系统离不开负载均衡,大中型公司下,负载均衡代理层都是有专... 负载均衡(Load Balancer,简称 LB)是指把客户端访问的流量通过负载均衡器,然后根据指定的一些负载均衡策略进行转发,最终可以均匀的分摊到后端上游服务器上,然后上游服务器进行响应后再返回数据给客户端。负载均衡的...
干货|开源OLAP引擎(ClickHouse、Doris、Presto、ByConity)性能对比分析
partial\_merge\_join\_optimizations = 1 | bucket配置:维表1,returns表10-20,sales表100-200 | Hive Catalog,ORC format,Xmx200GB | enable\_optimizer=1, dialect\_type='ANSI' | **服务器配... ****●**** Presto只在SQL67和SQL72发生Timeout,其他查询测试都跑通了。****●**** Clickhouse只跑通了50%的查询语句,大概有一部分是Timeout,另一部分是系统报错,分析原因是Clickhouse不能有效的支持多表关...
Kafka订阅埋点数据(私有化)
本文档介绍了在增长分析(DataFinder)产品私有化部署场景下,开发同学如何访问Kafka Topic中的流数据,以便进一步进行数据分析和应用,比如实时推荐等。 1. 准备工作 kafka消费只支持内网环境消费,在开始之前,需要提前... \"url\":\"http://demo.com.cn/product/list\",\"url_path\":\"/product/list\"}", "event_name": "predefine_pageview", "session_id": "aa7b79a1-4e27-44fe-bed8-56adfffddc07", "datetime": 1601590110, "s...
Kafka订阅埋点数据(私有化)
本文档介绍了在增长分析(DataFinder)产品私有化部署场景下,开发同学如何访问Kafka Topic中的流数据,以便进一步进行数据分析和应用,比如实时推荐等。 1. 准备工作 kafka消费只支持内网环境消费,在开始之前,需要提前... \"url\":\"http://demo.com.cn/product/list\",\"url_path\":\"/product/list\"}", "event_name": "predefine_pageview", "session_id": "aa7b79a1-4e27-44fe-bed8-56adfffddc07", "datetime": 1601590110, "s...
