执行存储过程并获取输出
 社区干货
社区干货
mysql事物存储过程
MySQL 数据库中的事务和存储过程是两个不同的概念,我将会分别解释这两个概念,然后提供一个简单的存储过程示例。1. **事务(Transaction)**:数据库事务是指一个或一组SQL语句的逻辑单元,这个逻辑单元中的操作要么全部执行,要么全部不执行。如果在执行过程中出现错误,那么事务将会回滚(Rollback),即撤销已经执行的操作;如果所有操作都成功执行,那么事务就会被提交(Commit),数据会被永久保存在数据库中。事务的主要特点是可以保证在...
Hive SQL 底层执行过程 | 社区征文
执行流程中的 SQL 编译成 MapReduce 的过程,第三节剖析 SQL 编译成 MapReduce 的具体实现原理。### 一、HiveHive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责... **步骤1**:UI 调用 DRIVER 的接口;**步骤2**:DRIVER 为查询创建会话句柄,并将查询发送到 COMPILER(编译器)生成执行计划;**步骤3和4**:编译器从元数据存储中获取本次查询所需要的元数据,该元数据用于对查询树中...
[数据库系统] 业界列式存储浅析
例如需要遍历全表获取符合要求的行,但只取部分列进行分组/排序/聚合等操作,行存就不太适合了,在读取时,由于会读取大量的无效的列的数据,且数据量很大,在存储是系统瓶颈的时代无疑是一大灾难,而且会影响内存中cache... 大多数商用优化器和执行器是基于行存的,RS 和 WS 都是列存的,所以需要做一个列存的优化器和执行器。C-Store 的比较创新的 feature:1. 针对频繁 insert 和 update 优化的 WS + 针对 query 优化的 RS 的混合架构...
字节跳动高性能 Kubernetes 元信息存储方案探索与实践
存储系统,其提供的能力是 K8s 所需的能力的超集。在使用过程中,其暴露出来的**主要问题**有:* etcd 的网络接口层限流能力较弱,雪崩时自愈能力差;* etcd 所采用的是单 raft group,存在单点瓶颈,单个 raft group 增加节点数只能提高容错能力,并不能提高写性能;* etcd 的 ExpensiveRead 容易导致 OOM,如果采用分页读取的话,延迟相对会提高;* boltdb 的串行写入,限制了写性能,高负载下写延迟会显著提高;* 长期运行容...
 特惠活动
特惠活动
 执行存储过程并获取输出
-优选内容
执行存储过程并获取输出
-优选内容
 执行存储过程并获取输出
-相关内容
执行存储过程并获取输出
-相关内容
使用对象存储静态存储卷
确保当前集群已安装对象存储服务组件 csi-tos。操作方法,请参见 安装组件。 已创建存储桶。操作方法,请参见 创建存储桶。 确保指定命名空间下已经存在合适的密钥,创建密钥所需的火山引擎账号 AK/SK 获取方法参见:... 单击存储卷列表左上角 创建存储卷。 在弹出的 创建存储卷 页面,完成参数配置。 配置项 说明 创建方式 选择存储卷的创建方式,目前支持静态创建。 名称 根据系统提示,自定义存储卷的名称,需确保存储卷名称在集群内...
[数据库系统] 业界列式存储浅析
例如需要遍历全表获取符合要求的行,但只取部分列进行分组/排序/聚合等操作,行存就不太适合了,在读取时,由于会读取大量的无效的列的数据,且数据量很大,在存储是系统瓶颈的时代无疑是一大灾难,而且会影响内存中cache... 大多数商用优化器和执行器是基于行存的,RS 和 WS 都是列存的,所以需要做一个列存的优化器和执行器。C-Store 的比较创新的 feature:1. 针对频繁 insert 和 update 优化的 WS + 针对 query 优化的 RS 的混合架构...
字节跳动高性能 Kubernetes 元信息存储方案探索与实践
存储系统,其提供的能力是 K8s 所需的能力的超集。在使用过程中,其暴露出来的**主要问题**有:* etcd 的网络接口层限流能力较弱,雪崩时自愈能力差;* etcd 所采用的是单 raft group,存在单点瓶颈,单个 raft group 增加节点数只能提高容错能力,并不能提高写性能;* etcd 的 ExpensiveRead 容易导致 OOM,如果采用分页读取的话,延迟相对会提高;* boltdb 的串行写入,限制了写性能,高负载下写延迟会显著提高;* 长期运行容...
RocketMQ 存储机制浅析
├── checkpoint // 其中存储着 commitlog、consumequeue、index 文件的最后刷盘时间戳 ├── commitlog // 其中存放着 commitlog 文件,而消息是写在 commitlog 文件中的 │ ├── 00000000000000000000 │ ├── 00000000001073741824 │ └── 00000000002147483648 ├── config // 存放着 Broker 运行期间的一些配置数据 │ ├── consu...
云盘持久化存储最佳实践
本节内容主要针对有状态服务挂载块存储实现数据持久化存储。有状态负载 StatefulSet 的应用场景如下: 稳定的部署次序:有序部署或扩展,需要根据定义的顺序依次进行,即从 0 到 N,在下一个 Pod 运行之前,所有之前的 P... Kubernetes 通过引用 PV 中的存储信息执行存储的挂载操作。 从消费存储的逻辑上看,使用时应用层会声明一个对存储的需求(PVC),而 Kubernetes 会通过最佳匹配的方式选择一个满足 PVC 需求的 PV,并与之绑定。而根据 P...
云原生环境下的日志采集、存储、分析实践
服务端日志又包括业务的运行/运维日志以及业务使用的云产品产生的日志。要管理诸多类型的日志,就需要一套统一的日志系统,对日志进行采集、加工、存储、查询、分析、可视化、告警以及消费投递,将日志的生命周期进行... 但是在使用过程中,我们发现了开源日志系统的不足:- 各业务模块自己搭建日志系统,造成重复建设。- 以 ES 为中心的日志架构可以利用 ES 查询便利的优势,但是资源开销大、成本高。而且 ES 与 Kibana 在界面上强绑定...
2022技术盘点之平台云原生架构演进之道|社区征文
容器编排:在CD过程中,利用kubectl set image进行容器编排部署,自建Kubernetes集群进行业务容器编排管理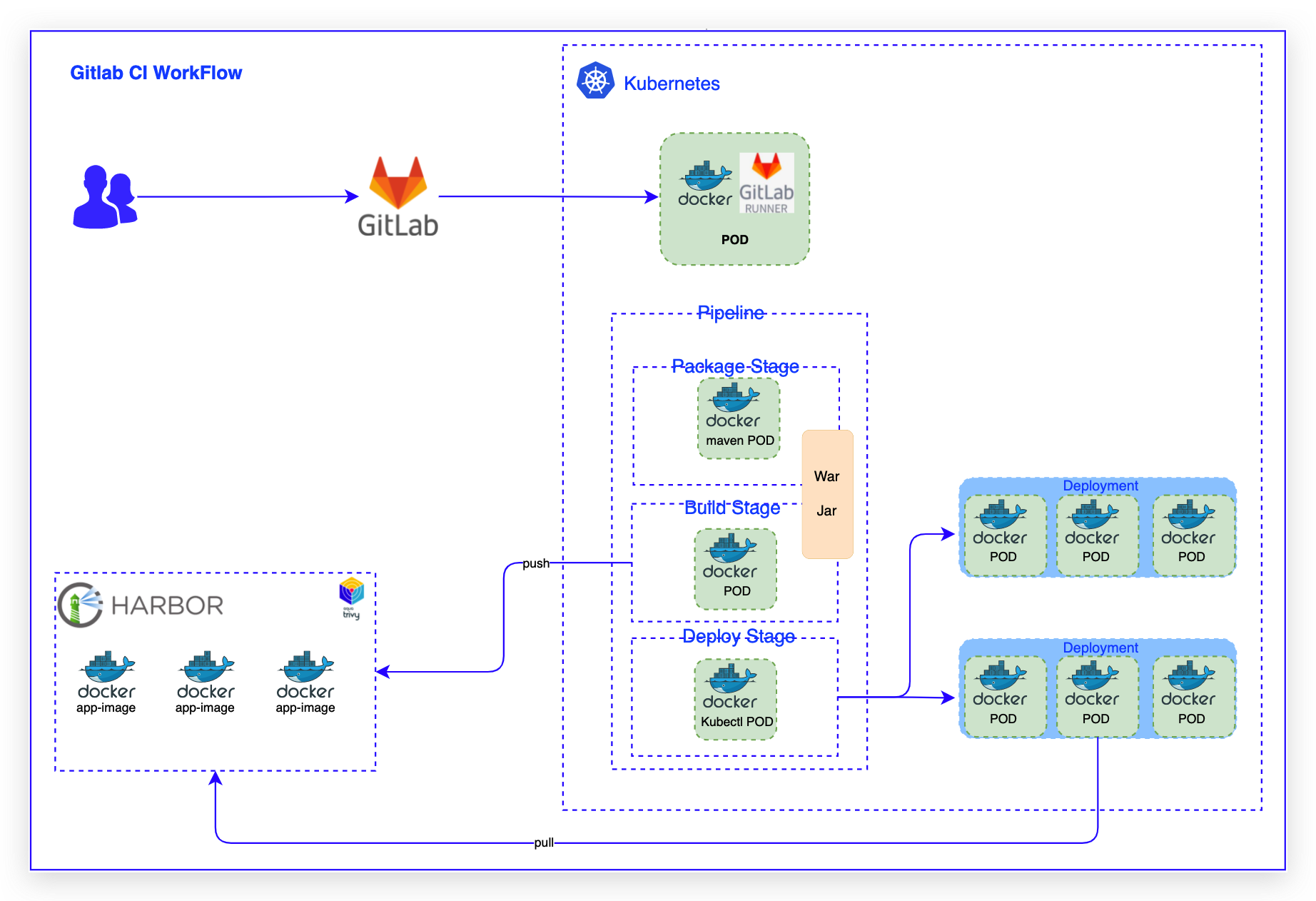- 高可用:当某个节点出现故障时,Kubernetes 会自动创建一个新的 GitLab-Runner 容器,并挂载同样的 Runner 配置,使服务达到高可用。- 弹性伸缩:触发式任务,合理使用资源,每次运行脚本任务时,Gitlab-Runner 会自动创建...
NAS 持久化存储最佳实践
已在文件存储控制台创建一个文件系统和挂载点,若未创建请参见下文步骤一,创建的文件系统需要与您的 Kubernetes 集群在同一可用区。 使用文件系统的 Pod 需运行在同一节点,并且保障节点和您创建的文件存储在同一可... 在弹出的 创建存储卷 页面,完成参数配置。 配置项 说明 创建方式 选择存储卷的创建方式,支持 静态创建,即由管理员创建 PV。 名称 根据系统提示,自定义存储卷的名称。需确保存储卷名称在集群内唯一。 存储卷类型 ...
使用 vePFS 文件存储静态存储卷
文件存储 vePFS 打破传统存储系统存在的 I/O 性能瓶颈,提升 AI 训练场景的小文件读取速度,收敛业务模型的训练迭代周期,同时提供冷热数据的分级存储,为您降低存储成本提供最佳方案。 前提条件确保当前集群已经安装... 使用限制当前通过 CSI 使用 vePFS 文件存储的方案与原有 VKE 接入使用 vePFS 方案不能同时使用。因此,建议创建新集群使用 CSI 方案,若存量资源需要迁移最新 CSI 方案,请 提交工单 获取技术支持。 单个 vePFS 实例...
