减少子查询数量
 社区干货
社区干货
ByConity 0.2.0 版本发布
算子 Spill 等1. RBAC 欢迎大家使用体验,期待听到大家的反馈和建议。 > https://github.com/ByConity/ByConity/releases# 冷读优化由于 ByConity 的存算分离架构,对远端存储的冷读相比本地磁盘有一定的性能差距,在 0.2.0 版本专门针对冷读进行了性能优化,主要手段有:## IOScheduler为了减少单个请求端到端的耗时,提升节点的吞吐,同时降低一定时间范围外的查询的数量。我们引入 IOScheduler 对远端数据进行读...
一口气看完43个关于 ElasticSearch 的使用建议
缓存的是某个 Filter 子查询语句在一个 Segment 上的查询结果。并非所有的 Filter 查询都会被缓存。对于体积较小的 Segment 不会建立 Query Cache,因为他们很快会被合并。Segment 的 Doc 数量需要大于 10000,并且... 随着文档数量增多和分页深度增加,性能会逐渐变差,有深分页问题。因为桶排序需要对所有文档进行整体排序,所以它的时间复杂度是 O(NlogN),其中 N 是文档总数。目前Elasticsearch支持聚合分页(滚动聚合)的目前只有复...
干货| 火山引擎在行为分析场景下的ClickHouse JOIN优化
降低错误率。> > > > ,进行本地JOIN5. Coordinator节点从每个节点拉取3中的结果集,然后做处理返回给client**存在的问题:**1. 子查询数量放大2. 每个节...
Hive SQL 底层执行过程 | 社区征文
Spark 或 Tez 执行查询。我们今天来聊的就是 Hive 底层是怎样将我们写的 SQL 转化为 MapReduce 等计算引擎可识别的程序。了解 Hive SQL 的底层编译过程有利于我们优化Hive SQL,提升我们对Hive的掌控力,同时有能力去定制一些需要的功能。### 二、Hive 底层执行架构我们先来看下 Hive 的底层执行架构图, Hive 的主要组件与 Hadoop 交互的过程: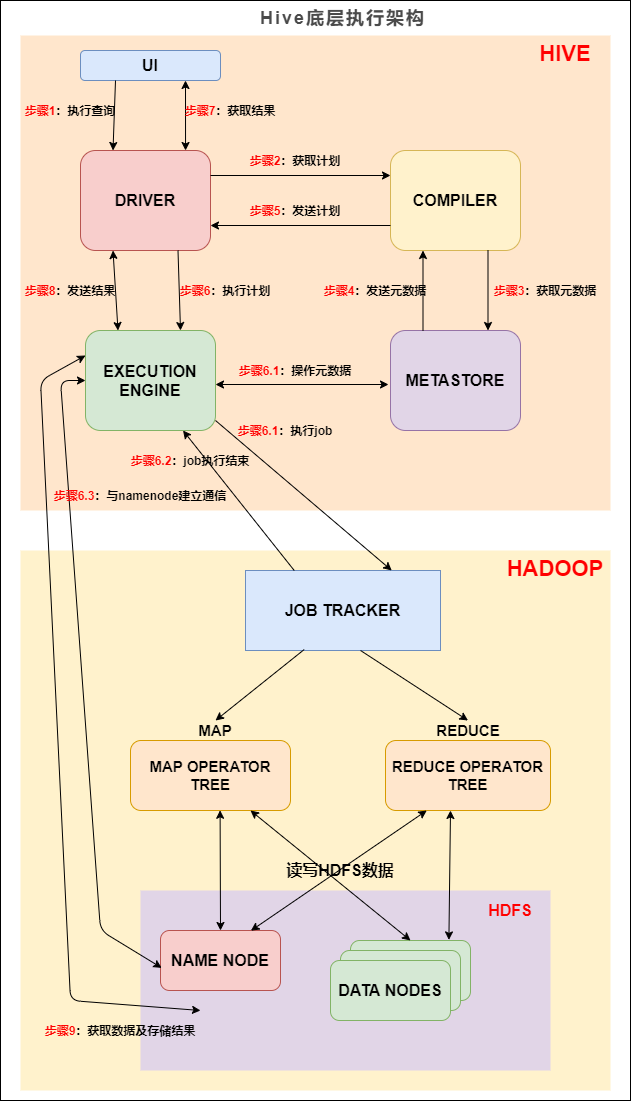...
 特惠活动
特惠活动
 减少子查询数量
-优选内容
减少子查询数量
-优选内容
 减少子查询数量
-相关内容
减少子查询数量
-相关内容
如何修改vke coredns 并发查询数量限制
# 前言coredns 默认最大并发查询数量限制为1000,下面介绍如何修改coredns 查询并发查询数量。# 操作步骤1.[登录到 VKE 容器控制台](https://console.volcengine.com/vke/region:vke+cn-beijing/cluster),找到对应的集群2.进入集群后-配置管理-配置项,选择 kube-system 命名空间,搜索 coredns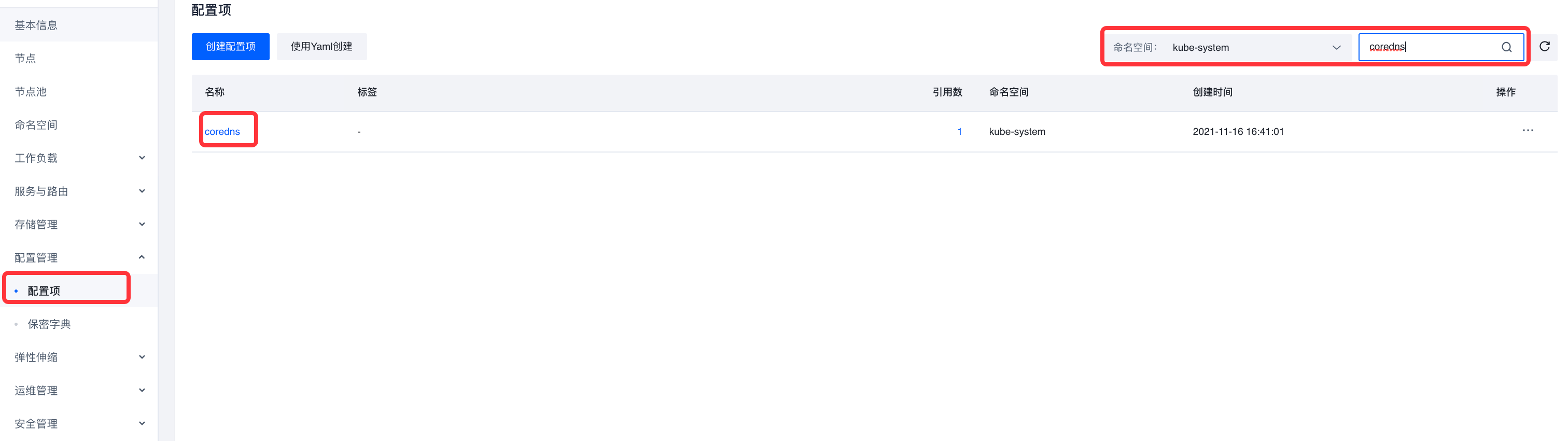3.进入 coredns 配...
基于ClickHouse的复杂查询实现与优化|社区征文
则是关于复杂查询(如多表 Join、嵌套多个子查询、window function 等),ClickHouse对这类需求场景的支持并不是特别友好,** 由于ClickHouse并不能通过Shuffle来分散数据增加执行并行度,并且其生成的Pipeline在一些ca... 减少彼此的依赖与耦合。即使模块发生变动或内部逻辑调整,也不会影响其他模块。其次,对模块采用插件架构,允许模块按照灵活配置支持不同的策略。这样便能够根据不同业务场景实现不同的策略。
通常用于join和in子查询,查询速度比用stat_standard_id更快。 cohort_id 分群id。 说明 在"元数据"标签下,可以查看所有的分群名、分群id以及分群人数。 当前暂不支持查询分群历史版本,因此目前通过分群id查询的... 超出这个范围的数据将不会被查询。 中 将查询时间限定为近365天。 您查询的数据不在过去365天之间。 高 将查询时间限定为近365天。 最多支持 2 条join子句,请检查您的 SQL。 高 降低JOIN子句数量 仅支...
SQL自定义查询(SaaS)
通常用于join和in子查询,查询速度比用stat_standard_id更快。 cohort_id 分群id。 说明 在"元数据"标签下,可以查看所有的分群名、分群id以及分群人数。 当前暂不支持查询分群历史版本,因此目前通过分群id查询的是... 请检查您的 SQL。 高 降低子查询层数。 查询的列名 {column} 不存在,请检查您的 SQL。 高 检查列名 {column} 是否在数据表中。 最多支持对4列进行 GROUP BY,请检查您的 SQL。 高 降低GROUP BY后列的数量。 不支持表...
SQL自定义查询(私有化)
通常用于join和in子查询,查询速度比用stat_standard_id更快。 cohort_id分群id *在"元数据"标签下,可以查看所有的分群名、分群id以及分群人数。*当前暂不支持查询分群历史版本,因此目前通过分群id查询的是最近一... 请检查您的 SQL。 高 降低子查询层数。 查询的列名 {column} 不存在,请检查您的 SQL。 高 检查列名 {column} 是否在数据表中。 最多支持对30列进行 GROUP BY,请检查您的 SQL。 高 降低GROUP BY后列的数量。 不支持...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
[点此查看ByteHouse技术白皮书(上)](https://developer.volcengine.com/articles/7219615010766389306) # ByteHouse 整体架构设计,ClickHouse对这类需求场景的支持并不是特别友好,**由于ClickHouse并不能通过Shuffle来分散数据增加执行并行度,并且其生成的Pipeline在一些ca... 通过并行可以极大降低调度延时。为防止出现大量网络IO线程,可以通过异步化手段控制线程数目。AllAtOnce策略的缺点是容错性没有依赖调度好,每一个Stage的Worker在调度前就已经确定了,调度过程中有一个Worker出现连接...
KubeWharf | 大规模K8S集群管理系统
大大减少了运维的工作量;(2)可伸缩性:Kubernetes支持水平扩展,可以根据需求自动调整应用程序的副本数量,并且能够处理大规模集群中的数千个节点;(3)高可用性:Kubernetes提供了故障恢复和自愈能力,能够在节点出现... 可以有效的降低性能的减弱,所以在大规模集群模式下,是可以选择kubebrain代替ectd的。虽然kubebrain支持社区版api-server,但字节官方推荐使用定制的api-server,会有更好的性能表现。## 2.kubezoo kubernetes...
