EurekaDiscoveryServer未注册客户端
 社区干货
社区干货
2022技术盘点之平台云原生架构演进之道|社区征文
服务通过Kubernetes API-Server获取后端一组Service Pod真实IP,业务POD通过Calico网络进行POD与POD直接流量通讯。## 四 安全管控### 4.1 SmartOps安全全景,Kubernetes 则有 ConfigMap、Secret 等,它本身也有配置能力,但是比较弱。Kubernetes 的优势在于它的组件和整个系统之间的交融度比较... Spring Cloud 的服务发现是基于 Eureka 的(后期也可以基于 Consul 进行),提供了自上报的机制和客户端负载均衡,是一个 AP 系统。Kubernetes 则更像传统的云厂商,可帮助用户创建机器/容器。平台自然知道应用在哪里...
【初探云原生】服务注册中心对比总结 |社区征文
目前对于注册中心,目前开源的主流的方案可以分成服务端模式和客户端模式两种大的类型。服务端模式主要包括:DNS, K8s(CoreDNS);而客户端模式主要包括:Zookeeper, Etcd, Consul, Eureka, Nacos,SofaRegistry。这里... 在服务注册与发现的场景下,主要应用的是Zookeeper的Znode数据模型和Watcher机制。服务注册:服务提供者(Provider)启动时,会向Zookeeper服务端注册服务信息,即会在Zookeeper服务器上创建一个服务节点,并在节点上存...
基于Prometheus的企业级监控体系探索与实践|社区征文
所以我们要尽可能的通过服务发现来管理客户端列表。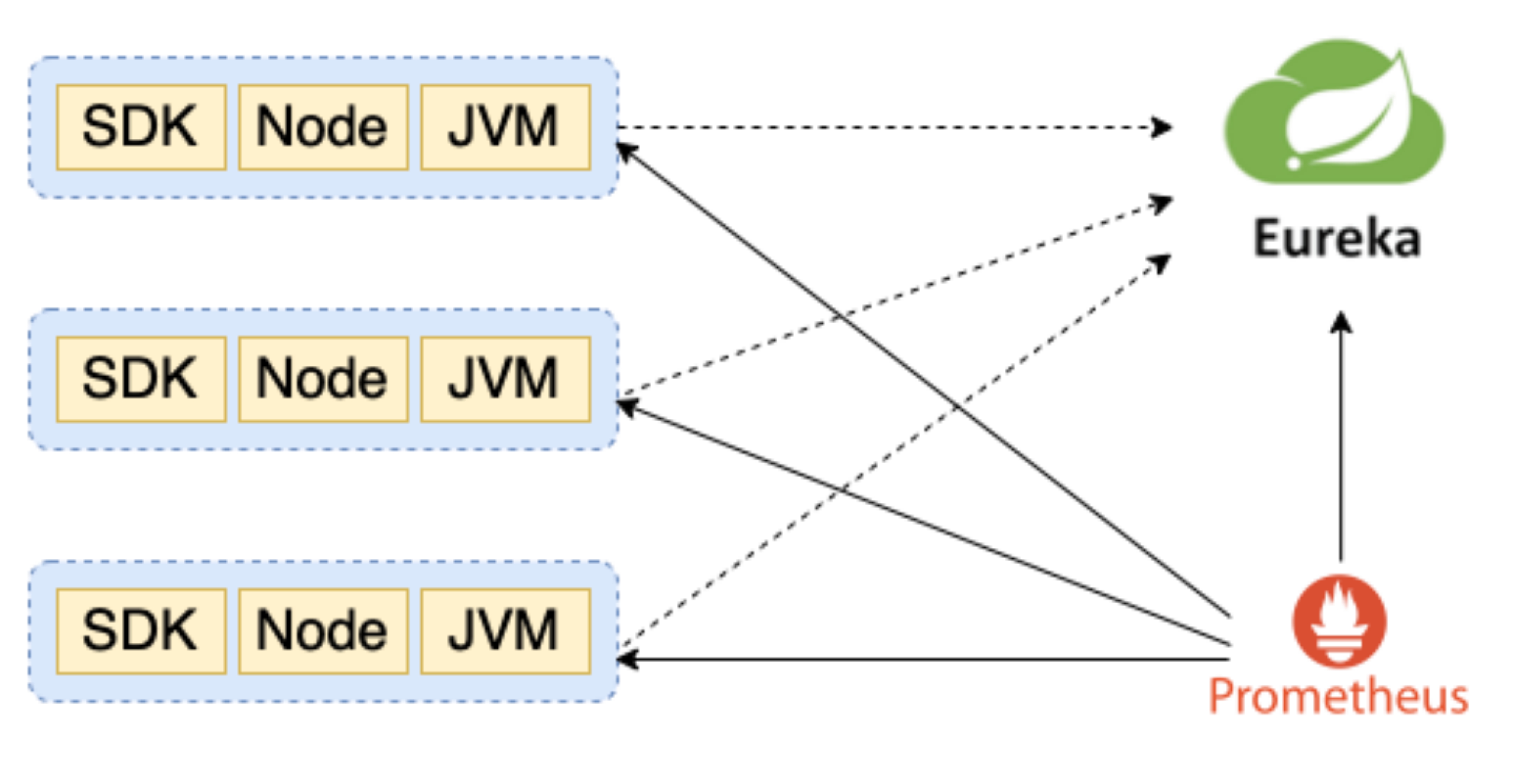借助于架构转型,全行使用统一的springcloud技术栈,注册中心为Eureka,为了兼容Prometheus服务发现,我们对Eureka进行二次开发使其能够模拟Consul的服务注册发现API(2.21.0版本后以支持Eureka SD),简化server端配置。我们监控主要分为资源...
 特惠活动
特惠活动
 EurekaDiscoveryServer未注册客户端
-优选内容
EurekaDiscoveryServer未注册客户端
-优选内容
 EurekaDiscoveryServer未注册客户端
-相关内容
EurekaDiscoveryServer未注册客户端
-相关内容
干货 | 看 SparkSQL 如何支撑企业级数仓
Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以... 用户可以通过如下方式访问服务器:- HA 访问链接:``` ./bin/beeline -u jdbc:hive2://emr-5fqkwudj144d2gc1k8hi-master-1/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=midas/ha;auth=LDAP -n e...
容器编排技术 Kubernetes 学习总结|社区征文
并且这些功能对客户端都是无感知的。1. 密钥与配置管理:Kubernetes 允许你存储和管理敏感信息,例如密码、OAuth 令牌和 ssh 密钥。 你可以在不重建容器镜像的情况下部署和更新密钥和应⽤程序配置,也⽆需 在堆栈配... 供客户端和其它组件调用,相当于“营业厅”;- Etcd:Api server 的后台数据存储,相当于 Kubernetes 集群的数据中⼼;- Scheduler:负责对集群内部的资源进行调度,相当于“调度室”;- Controller-manager:控制...
eBPF 完美搭档:连接云原生网络的 Cilium
Serverless 场景下甚至短至几分钟,几秒钟随着容器密度的增大,以及生命周期的变短,对原生容器网络带来的挑战也越来越大。# **当前** **K** **8s** **Service** **负载均衡** **的实现现状**在 Cilium 出现之前, Service 由 kube-proxy 来实现,实现方式有 `userspace`,`iptables`,`ipvs` 三种模式。## **Userspace**当前模式下,kube-proxy 作为反向代理,监听随机端口,通过 iptables 规则将流量重定向到代理端口,再由 kub...
LAS Spark+云原生:数据分析全新解决方案
Servers:支持多个 KyuubiServer,启动过程中会注册到 ZK/ETCD,方便进行服务发现和负载均衡。多个 Server也实现了冷备的 HA。- Engine Discovery:客户端请求在 KyuubiServer 中会通过 Engine Discovery 找到自... 不需要随着任务数量增加提高服务器配置,方便了水平扩展。通过构建 UIService,我们极大的节省了 Spark UI 相关 event 的存储空间,并有效的提升了 UI 访问延迟性能,在架构上我们也基于 UIService 实现了多租户访问...
LAS Spark+云原生:数据分析全新解决方案
Servers:支持多个 KyuubiServer,启动过程中会注册到 ZK/ETCD,方便进行服务发现和负载均衡。多个 Server 也实现了冷备的 HA。- Engine Discovery:客户端请求在 KyuubiServer 中会通过 Engine Discovery 找到... 不需要随着任务数量增加提高服务器配置,方便了水平扩展。通过构建 UIService,我们极大的节省了 Spark UI 相关 event 的存储空间,并有效的提升了 UI 访问延迟性能,在架构上我们也基于 UIService 实现了多租户访问...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。**本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。**... Hive Server2在FetchResults方法中存在bug。由于Hive Server2没有很好处理hasMoreRows字段,导致Hive JDBC 客户端并未通过hasMoreRows字段去判断是否还有下一页,而是通过返回的List是否为空来判断。因此,相比Mysql ...
在字节跳动,一个更好的企业级 SparkSQL Server 这么做
> SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致难满足日常的业务开发需求。**本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门槛降低。**... Hive Server2在FetchResults方法中存在bug。由于Hive Server2没有很好处理hasMoreRows字段,导致Hive JDBC 客户端并未通过hasMoreRows字段去判断是否还有下一页,而是通过返回的List是否为空来判断。因此,相比Mysql ...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致> 难满足日常的业务开发需求。> **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门... Hive Server2在FetchResults方法中存在bug。由于Hive Server2没有很好处理hasMoreRows字段,导致Hive JDBC 客户端并未通过hasMoreRows字段去判断是否还有下一页,而是通过返回的List是否为空来判断。因此,相比Mysql ...
Go 语言微服务介绍与开发实战|社区征文
RPC Client/Server:基于 RPC 的请求/响应,支持双向流。为同步通信提供了一个抽象层,向一个服务提出的请求将被自动处理、负载均衡、拨号和流化。- 服务发现: 自动服务注册和名称解析。服务发现是微服务开发的... 客户端和服务器将与内容类型一起使用编解码器,为你无缝编码和解码 Go 类型。任何种类的消息都可以被编码并从不同的客户端发送。客户端和服务器默认会处理这个问题。这包括默认的 protobuf 和 json 格式。- 信息...
