基于状态分配的每日记录数量
 社区干货
社区干货
golang pprof
debug=2会展示更详细的信息(例如goroutine状态) || heap | 堆上对象的内存申请情况 || mutex | mutex的竞争状态,默认不开启, 需... 然后运行即可(源仓库没有基于go mod构建,我们这里也就先off掉mod)。```export GO111MODULE=off && go build```我们先来简单看一下`main.go`文件。程序设置可GOMAXPROCS,可以限制P的数量为1,变相的限制了cp...
火山引擎大规模机器学习平台架构设计与应用实践
可根据参数量、计算量自动切分流水线。veGiantModel 的底层是基于 BytePS 做加速的。下面对 BytePS 和 veGiantModel 展开做介绍。#### BytePS 通信优化分布式机器学习领域当中,有两种常见的通信训练架构:一种... BytePS 设计了一套精确的梯度分配方案,将要通信的梯度恰到好处地分配给所有 GPU 和 CPU 机器执行规约操作。从通信流量上看,相当于同时结合了 PS 和 All-Reduce 两种通信模式。BytePS 机内通信的核心优化思路,在于...
关于大数据计算框架 Flink 内存管理的原理与实现总结 | 社区征文
每条记录都会以序列化的形式存在一个或多个MemorySegment中。TaskManager内存模型如下图所示: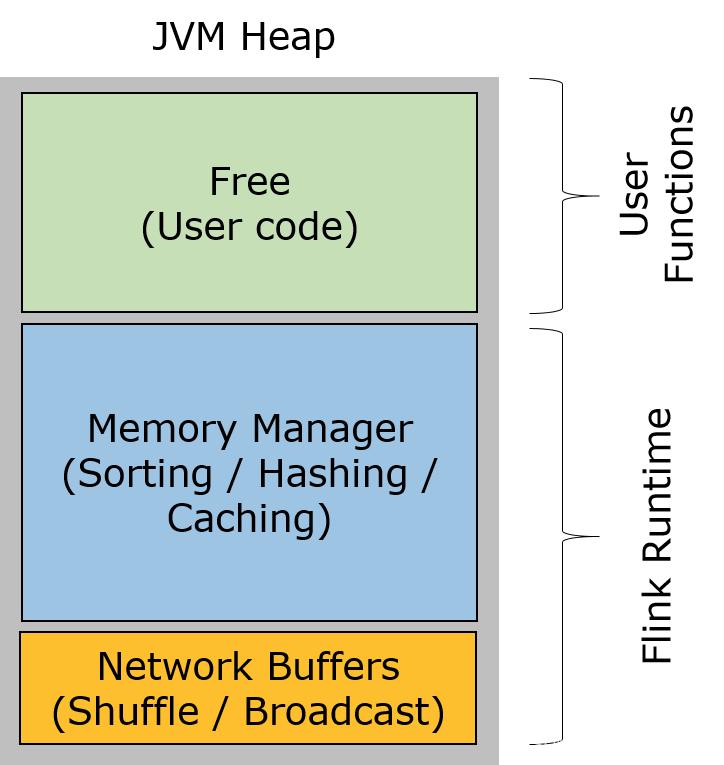Flink 主要的内存管理是TaskManager进行内存管理,主要分为三部分:- Network Buffers:一定数量的32KB大小的Buffer,主要用于网络传输。在TaskManager启动的时候就会分配。默认数量是2048个,可以通...
字节跳动 EB 级 Iceberg 数据湖的机器学习应用与优化
每日还在以 PB 级的速度增长。这些数据被用于支持广告、搜索、推荐等模型的训练,覆盖了多个业务领域;这些数据还支持算法团队的特征调研、特征工程,并为模型的迭代和优化提供基础。目前字节跳动以及整个业界在机器学... GPT-3 的模型参数数量飙升至 1750 亿个。这一巨大的增长引发了广泛的关注,并且使得 GPT-3 在自然语言处理任务中取得了令人瞩目的成就。 然而随着模型参数的增长,模型的大小也成为一个问题。为了解决这个问题...
 特惠活动
特惠活动
 基于状态分配的每日记录数量
-优选内容
基于状态分配的每日记录数量
-优选内容
 基于状态分配的每日记录数量
-相关内容
基于状态分配的每日记录数量
-相关内容
9年演进史:字节跳动 10EB 级大数据存储实战
但当 NameNode 数量也变得非常多了以后,用户请求的统一接入及统一视图的管理也会有很大的问题。为了解决用户接入过于分散,我们需要一个独立的接入层来支持用户请求的统一接入,转发路由;同时也能结合业务提供用户权限和流量控制能力。另外,该接入层也需要提供对外的目录树统一视图。接入层从部署形态上来讲,依赖于一些外部组件如 Redis,MySQL 等,会有一批无状态的 NNProxy 组成,他们提供了请求路由、Quota 限制、Tracing 能力及...
干货|8000字长文,深度介绍Flink在字节跳动数据流的实践
* **业务数量:**在 字节跳动,包括抖音、今日头条、西瓜视频、番茄小说在内的**3000多个**大大小小的APP和服务都接入了数据流。* **数据流峰值流量:**当前,字节跳动埋点数据流 **峰值流量超过1亿每秒**,每天... 这么做的原因主要是因为使用元数据流更新的方式需要开启Checkpoint以保存元数据的状态,而在字节跳动数据流这样的大流量场景下,开启Checkpoint会导致在Failover时产生大量重复数据,下游无法接受。