怎样进一步优化这个程序?
 社区干货
社区干货
Linux RT 进程引发内核频繁卡死的优化方案
由于从 Guest OS 无法进一步探查到有用信息,我们决定**从主机层面进行排查,通过查看主机 CPU 使用率,发现某个 vCPU 长期占用 100%,并且没有释放。**图 2....
CPU调频、线程绑核、优先级控制实践
# 一、背景为了进一步优化App性能,最近针对如何提高应用对CPU的资源使用、以及在多线程环境下如何提高关键线程的执行优先级做了技术调研。本文是对技术调研过程的阶段性总结,将分别介绍普通应用如何调控App频率、... 对于普遍的应用程序,经过调研发现,高通提供了一套针对高通芯片的性能Jon告知SDKPower,利用这个套机制可以实现CPU频率等资源的管理。关于高通这套Framework的具体架构,可以参考最后附录中的参考资料的相关文章,我...
如何调优一个大型 Flink 任务 | 社区征文
可根据业务对延迟的要求决定是否需要优化。- QPS 曲线抖动。正常运行的任务,其 QPS 曲线一般平滑且稳定,有时也会随着输入 QPS 周期性波动。当发生性能问题时,往往会看到 QPS 曲线有明显抖动。有时 QPS 曲线并未抖... 需要进一步定位。3. 如果怀疑延迟是由于磁盘 IO 造成的,那么可以找到某些 Task Manager 查看其单机磁盘监控,是否有磁盘 IO 次数过高,或者数据 size 过大。 如果怀疑延迟是由于网络 IO 造成的,那么可以查...
iOS 优化 - 启动优化 |社区征文
处于后台的应用程序会逐渐从内存移除从而为前台应用程序提供更多的内存,所以当用户正在使用内存密集型的游戏应用,然后重新进入你的 App 程序,这时你的应用程序依赖于启动的框架和守护程序也可能需要重新启动并从磁盘调入。我们在实际测量启动时间时应该是测量**温启动**类型,主要是冷启动状态不好统一,因为不好确定一些系统端服务的运行状态或者一些缓存的使用。## App 启动过程在优化之前,我们需要对 App 的完整启动过程有...
 特惠活动
特惠活动
 怎样进一步优化这个程序?
-优选内容
怎样进一步优化这个程序?
-优选内容
 怎样进一步优化这个程序?
-相关内容
怎样进一步优化这个程序?
-相关内容
用 Istio 解释微服务和服务网格
**微服务**会将应用程序分解为多个较小的服务组件。与传统的一体化(Monolithic)架构相比,**微服务架构将每个微服务视为独立的实体与模块**,从根本上有助于简化代码和相关基础架构的维护。应用程序的每个微服务都可以编写在不同的技术堆栈中,并且可以进一步独立地部署、优化和管理。从理论上讲,微服务体系结构特别有利于复杂的大型应用程序的构建,但实际上,它也被广泛用于小型应用程序的构建。**微服务架构的好处**- 可以...
大数据量、高并发业务优化教程|社区征文
```一般情况下大家都知道第二条优化,但是可能会忽略jdbc参数携带 `rewriteBatchedStatements=true`,这个参数能在第二条的基础上启用批量执行SQL,进一步提升写入性能# 二. 大事务优化,减小影响范围,提升系统处理能力`@Transactional` 大于 `Spring` 提供得事务注解,许多人都知道,但是在高并发下,不建议使用,推荐通过编程式事务来手动控制事务提交或者回滚,减少事务影响范围如下是一段订单超时未支付回滚业务数据得代码,采用...
干货 | 基于ClickHouse的复杂查询实现与优化
在对ClickHouse的应用与优化过程中积累了大量技术经验。本篇将解析ClickHouse的复杂查询问题,分享字节跳动解决ClickHouse复杂查询问题的优化思路与技术细节。> **关注字节跳动数据平台微信公众号,回复【0711】获得... 此时可以通过反压信息来进一步判断。* 当输入和输出队列数目不一样,这可能是出于反压传导的中间状态或者该 stage 就是反压的根源。* 如果一个 stage 的输出队列数目很多,且经常被反压,通常是被下游 stage 所影响...
基于ClickHouse的复杂查询实现与优化|社区征文
近期社区也进行了一些右表并行构建的优化,数据按照Join key进行Split来并行地构建多个Hash Table,但额外的代价是左右表都需要增加一次Split操作。**第三类,则是关于复杂查询(如多表 Join、嵌套多个子查询、windo... 此时可以通过反压信息来进一步判断。- 当输入和输出队列数目不一样,这可能是出于反压传导的中间状态或者该 stage 就是反压的根源。- 如果一个 stage 的输出队列数目很多,且经常被反压,通常是被下游 stage 所...
GPU推理服务性能优化之路
# 一、背景随着CV算法在业务场景中使用越来越多,给我们带来了新的挑战,需要提升Python推理服务的性能以降低生产环境成本。为此我们深入去研究Python GPU推理服务的工作原理,推理模型优化的方法。最终通过两项关键... 经过TensorRT优化后,模型运行时需要的显存大小一般会降低到原来的1/3到1/2。为了充分利用GPU算力,框架进一步优化,支持可以把GPU进程在一个容器内复制多份,这种架构即保证了CPU可以提供充足的请求给GPU,也保证了G...
A/B 测试实战解析:这款APP用火山引擎 DataTester 完成用户体验优化
但如何帮助用户实现这个目标,做好商品侧数据分析及展现只是第一步,更重要的是,慢慢买还要对App功能进行进一步优化,使其能精准匹配用户的需求和喜好。 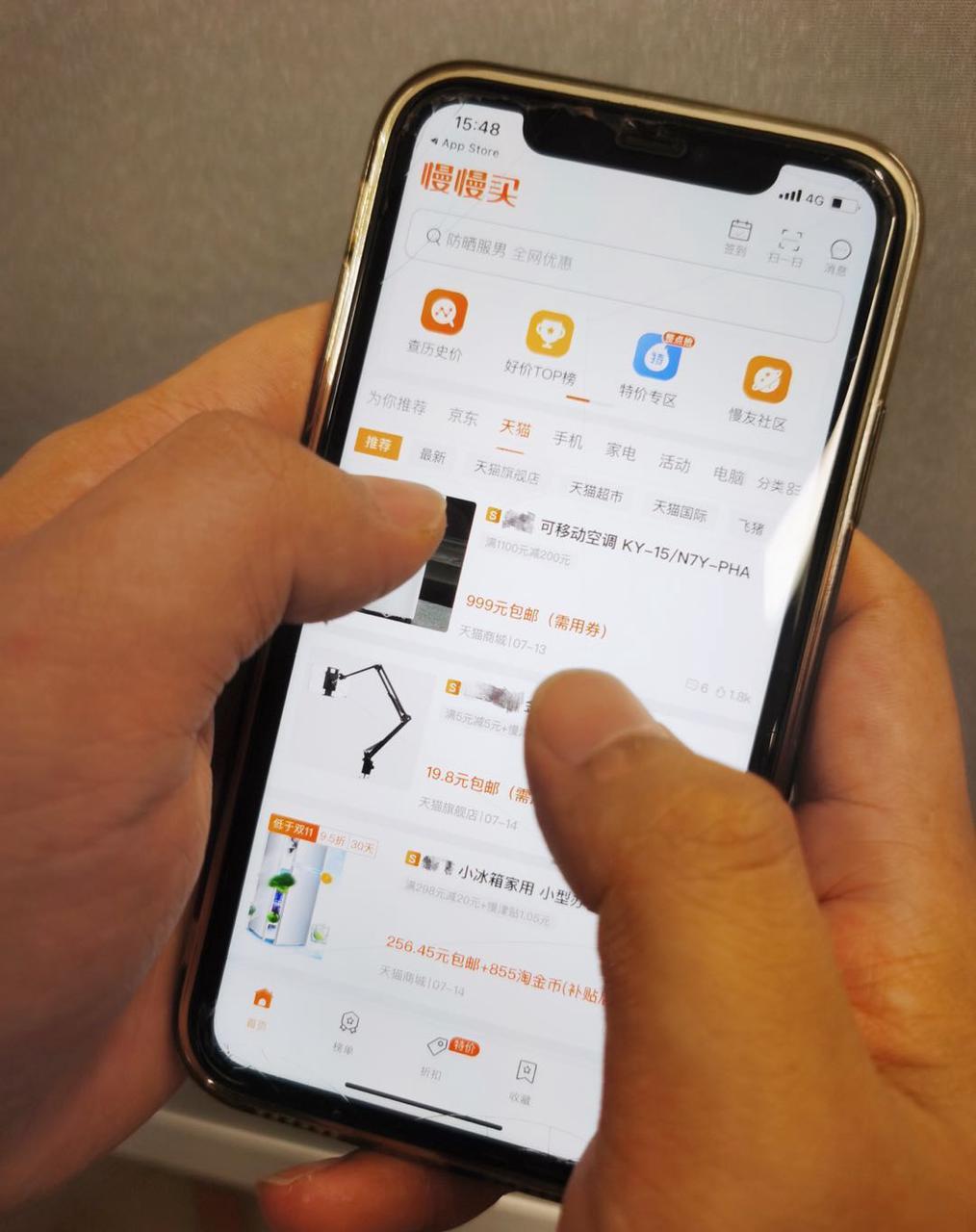 彼时,字节跳动旗下的抖音APP和今日头条APP势头正猛,“是不是能把这两款产品增长的成功经验‘复用’到慢慢买APP上来?”一个想法逐渐从...
提升私域转化率:以广告投放为例
本文详细地描绘了如何利用群体画像优化公司广告投放策略,以提升私域转化率。针对由点击广告、访问小程序到最后的留资行为形成的用户生命周期链路,我们结合业务场景、明确的分析目标、整合的策略思路以及结论性的分... 如果他们点击广告的次数少于2次且还没有访问过小程序的,可进行再次的营销行动。这些用户仍有潜力进一步了解行业或品牌,但可能需要更明确或更吸引人的信息来激发他们的兴趣。 个性化广告内容: 对于已经点击广告但未...
LAS Spark 在 TPC-DS 的优化揭秘
但是当前这个优化规则还不足够,我们在此基础上做了更多的优化:1. 根据统计信息覆盖更多场景当前判断能否把 decimal 转成 Long 是根据 hive schema 里定义的 decimal 类型,但是如果我们已经有了每列的统计信息(最大最小值),我们可以进一步把这个 decimal 的 precision 缩小,进而可以覆盖更多 case。比如,tpc-ds 里 store_returns 的 sr_fee 的schema 定义是 Decimal(7,2),但是通过 analyze table 之后可以知道,这个列的最大...
veImageX演进之路:FPGA HEIF 静图编码服务性能优化
并给出优化解决方案。经过一系列的优化措施,veImageX 整体 CPU 负载从80%降低至30%,相应的服务延时从140ms降低为4ms。**架构** 首先,我们看一下 FPGA HEIF 静图分发链路的整体架构。