Webix如何重新排列列的顺序?
 社区干货
社区干货
[数据库论文研读] HTAP行列混存 & 智能转换
就相当于在一个连续空间的末尾顺序写入所有数据,但是对read-only的workload比较不友好,特别是不需要读所有列的时候,相当于做大量的随机读。### DSM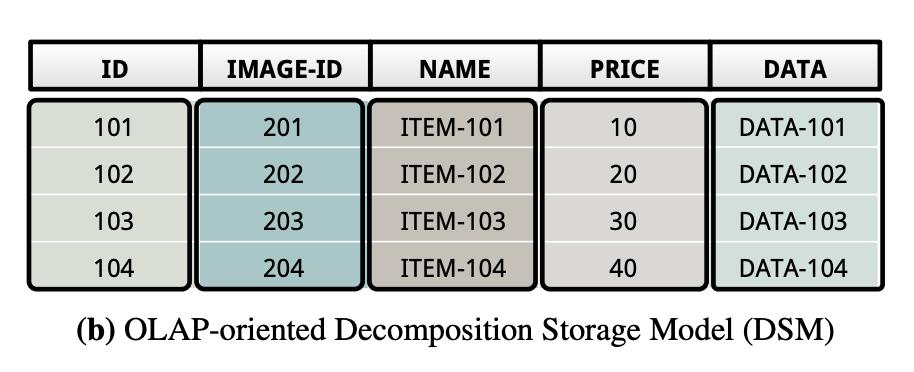全称Decomposition Storage Model,俗称列存,就是将表里面的一列(一个字段)的数据存到一起,一个文件里...
DataLeap 数据资产实战:如何实现存储优化?
聚集索引 B+树排序访问,支持基于 Key 或者 Key-Column 的 Range Query,所有查询都走索引,且避免内存中重排序,效率初步判断可接受。- 中台内的其他系统,最大的 MySQL 单表已经到达亿级别,且 MySQL 有成熟的分库分... 表结构是 4 列(id, g_key, g_column, g_value),除自增 ID 外,对应 key-column-value model 的数据模型,key+column 是一个聚集索引。- Context 中的租户信息,需要在操作某个租户数据之前设置,并在操作之后清除掉...
干货|DataLeap数据资产实战:如何实现存储优化?
聚集索引B+树排序访问,支持基于Key或者Key-Column的Range Query,所有查询都走索引,且避免内存中重排序, **效率初步判断可接受。**===========================================================================... 存在超大table(有8000甚至10000列),这些table的元数据处理非常耗时(10000列的可能需要30分钟),而且在处理过程中有很长一段时间和数据库并没有交互,数据库连接一直空闲。 **解决办法****:****●** 调整...
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
都需要重新加载整个路径,才能对外服务。每个任务在完成后,也需要等待下一轮扫描才能被访问到。当集群任务数量增多,每一轮扫描文件的耗时以及元信息内存占用都会增加,这也要求服务有越来越高的资源配置。如果通过拆... 会序列化成四个片段:类名长度(4 byte long 类型)+ 类名(string 类型)+ 数据长度(4 byte long 类型)+ 序列化的数据(二进制类型)。在读取时顺序读取,每个元素先读取长度信息,再根据长度读取后续相应数据进行反序列化...
 特惠活动
特惠活动
 Webix如何重新排列列的顺序?
-优选内容
Webix如何重新排列列的顺序?
-优选内容
 Webix如何重新排列列的顺序?
-相关内容
Webix如何重新排列列的顺序?
-相关内容
干货|DataLeap数据资产实战:如何实现存储优化?
聚集索引B+树排序访问,支持基于Key或者Key-Column的Range Query,所有查询都走索引,且避免内存中重排序, **效率初步判断可接受。**===========================================================================... 存在超大table(有8000甚至10000列),这些table的元数据处理非常耗时(10000列的可能需要30分钟),而且在处理过程中有很长一段时间和数据库并没有交互,数据库连接一直空闲。 **解决办法****:****●** 调整...
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
都需要重新加载整个路径,才能对外服务。每个任务在完成后,也需要等待下一轮扫描才能被访问到。当集群任务数量增多,每一轮扫描文件的耗时以及元信息内存占用都会增加,这也要求服务有越来越高的资源配置。如果通过拆... 会序列化成四个片段:类名长度(4 byte long 类型)+ 类名(string 类型)+ 数据长度(4 byte long 类型)+ 序列化的数据(二进制类型)。在读取时顺序读取,每个元素先读取长度信息,再根据长度读取后续相应数据进行反序列化...
万字长文带你漫游数据结构世界|社区征文
但是我们还必须知道在计算机中如何表示它。**数据结构在计算机中的表示(又称为映像),称之为数据的物理结构,又称存储结构**。数据元素之前的关系在计算机中有两种不同的表示方法:**顺序映像和非顺序映像**,并且... 排序后的链表,还是只能知道头尾节点,知道中间的范围,但是要找到中间的节点,还是得走遍历的老路。如果我们把中间节点存储起来呢?存起来,确实我们就知道数据在前一半,还是在后一半。比如找`7`,肯定就从中间节点开始找...
字节跳动湖平台在批计算和特征场景的实践
列的最大最小值、是否存在 Null 值等统计信息。* Data File 是存储的数据,数据将以 Parquet、Orc、Avro 等文件格式进行存储。#### **Iceberg 特点*** SchemaEvolution:Iceberg 表结构的更新,本质是内在元... 每个文件按照主键排序;* 读取旧 Data File 时根据用户选择的列,分析具体需要哪些 Update File 和 Data File;* 根据旧 Data File 中 Min-Max 值去选择对应的 Update File。由此可以看出,MOR 的本质是对多个 D...
DescribeCommands
Order String 否 created_at 返回命令的排序方式。取值: created_at:按创建时间倒序排列。 name:按名称列的字母顺序进行排序。 说明 公共命令:默认按照name进行排序。 自定义命令:默认按照created_at排序,可以选择基于名称列(字母顺序)或创建时间列进行排序。 OrderAscending Boolean 否 false 指定返回命令按升序或降序排列。取值: false(默认):降序 true:升序 PageNumber Integer 否 1 当前页码。 起始值:1。...
字节跳动湖平台在批计算和特征场景的实践
Manifestlist 是清单文件列表,用于存储单个快照的清单文件。Manifestfile 是存储的每个数据文件对应的清单文件,用来追踪这个数据文件的位置、分区信息、列的最大最小值、是否存在 Null 值等统计信息。- **Data... 每个文件按照主键排序;- 读取旧 Data File 时根据用户选择的列,分析具体需要哪些 Update File 和 Data File;- 根据旧 Data File 中 Min-Max 值去选择对应的 Update File。由此可以看出,MOR 的本质是对多个...
函数概览
本文档罗列了日志服务所支持的 SQL 函数。 注意 日志服务产品架构升级,支持更丰富的检索分析功能。 如果控制台提示新一代架构正式发布信息,表示您使用的是 2.0 架构,可参考本文档使用相关功能。 如果控制台未提示新... 按照反向顺序返回字符串。 RPAD 函数 RPAD(KEY, length, lpad_string) 在指定字符串的结尾填充字符,填充到指定长度后返回结果字符串。 RTRIM 函数 RTRIM(KEY) 删除字符串结尾的空格。 SPLIT 函数 SPLIT(...
干货 | UniqueMergeTree:支持实时更新删除的ClickHouse表引擎
**常见的列存储实时更新方案** 下面介绍下在列存储里支持实时更新的常见技术方案。**key-based merge on read**第一个方案叫key-based merge on read,它的整个思想比较类似LSMTree。对于写入,数据先根据key排序,然后生成对应的列存文件。每个Batch写入的文件对应一个版本号,版本号能用来表示数据的写入顺序。同一批次的数据不包含重复key,但不同批次的数据包含重复key,这就需要在读的时候...
基于 LoserTree 的 Paimon 多路归并优化
第一步需要将这 5 个待排序列的按照头元素的大小调整为小根堆,调整的顺序为自底向上。1)首先调整 Node4 节点;