c4d中cuda未被选中
 社区干货
社区干货
火山引擎部署ChatGLM-6B实战指导
在实例类型中,选择GPU计算型,可以看到有A30、A10、V100等GPU显卡的ECS云主机,操作系统镜像选择Ubuntu 带GPU驱动的镜像,火山引擎默认提供的GPU驱动版本为CUDA11.3,如果需要升级版本的话可以参考后面的步骤,配置GPU服务器。在模型优化方面,我主要关注神经元剪枝... 模型剪枝的原理是通过剔除模型中 “不重要” 的权重,使得模型减少参数量和计算量,同时尽量保证模型的精度不受影响。我们的主要实现方式是利用OpenVINO工具套件的模型剪枝和量化功能,有选择性地减小模型的规模,去...
得物AI平台-KubeAI推理训练引擎设计和实践
KubeAI的解决方案是把CPU逻辑与GPU逻辑分离在两个不同的进程中: **CPU进程主要负责图片的前处理与后处理,GPU进程则主要负责执行CUDA Kernel 函数,即模型推理** 。为了方便模型开发者更快速地接入我们的优化方案... 训练时相关参数的选择至关重要。总结如下:* batch\_size:根据数据量,以及期望训练时长,用户合理自定义设置* 训练环境(KubeAI Notebook/任务/流水线节点)的CPU配置:建议CPU配置为 GPU卡数*(单GPU卡配置的CPU核数...
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 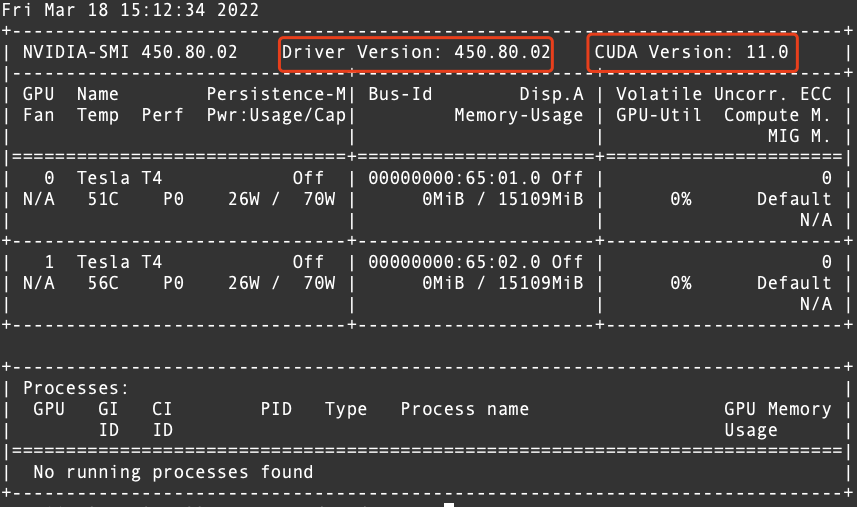 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
 特惠活动
特惠活动
 c4d中cuda未被选中-优选内容
c4d中cuda未被选中-优选内容
 c4d中cuda未被选中-相关内容
c4d中cuda未被选中-相关内容
字节跳动 Spark 支持万卡模型推理实践
c4d~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1715703643&x-signature=b1fYZ0cn5xpBDpGdsJQoDWH%2FhMg%3D)整体架构如图所示, **Arcee Operator 内部包含了六个模块** ,其中 **Arcee CRD** 模... Worker 关系中仔细分析了各种 Executor、Worker 退出的情况。通过在容器环境中实现 Executor 优雅退出,捕获退出信号并自动做 cudaDeviceSync,防止离线退出导致 MPS 处于未定义状态 。* **通过 Quota 解决大量 ...
如何基于火山引擎弹性容器快速部署 MagicAnimate 应用
同时将模型也打包到容器镜像中。可用镜像地址:paas-cn-beijing.cr.volces.com/aigc/magic-animate:v1``` FROM paas-cn-beijing.cr.volces.com/cuda/cuda:11.4.3-devel-ubuntu20.04-torch LABEL org.opencontainers.image.authors="xxx@bytedance.com" RUN apt-get update && apt-get install -y gi...
SoCC 论文解读:字节跳动如何在大规模集群中进行统一资源调度
每个节点只能在一个 Partition 里面。每个 Scheduler 实例对应一个 Partition,一个 Scheduler 实例工作的时候会优先选择自己 Partition 内的节点,没有找到符合要求的节点时才会去找其他 Partition 的节点。如果集群... 优先从该实例所属的 partition 中选择,这样性能更好,但只能保证局部最优;本地 partition 没有合适的节点时,会从其他实例的 partition 中选择节点,但这可能会引起 conflict,即多个 scheduler 实例同时选中同一个节点...
模型的性能评估及优化
存在未结束的评估任务时无法发起新的评估任务。 操作步骤 登录机器学习平台,单击左侧导航栏中的【模型服务】-【模型管理】进入列表页面。 单击待查看模型的名称进入详情页面,并在模型版本列表中选中希望进行性能... 选择的规格越多评估的用时越长。 * 由于在超大的内存和多张 GPU 上的评估对结果没有明显影响,所以仅保留了单张 GPU 及 128GiB 内存以下的计算规格。 以下图中的 InceptionV3 图像分类模型为例。该模型输入是一张图...
GPU-使用Llama.cpp量化Llama2模型
CUDA:使GPU能够解决复杂计算问题的计算平台。本文以CUDA 12.2为例。 CUDNN:深度神经网络库,用于实现高性能GPU加速。本文以8.5.0.96为例。 运行环境: Transformers:一种神经网络架构,用于语言建模、文本生成和... 安装GPU驱动和CUDA。 sh cuda_12.2.1_535.86.10_linux.run输入"accept"确认信息。 按键盘上下键选中【Install】,回车确认,开始安装。 安装完成后,执行以下命令进行验证。 nvidia-smi回显如下,说明驱动安装成功。 ...
弹性容器实例:基于 Argo Workflows 和 Serverless Kubernetes 搭建精细化用云工作流
中的服务,可参考以下文档在容器服务 VKE 中先创建集群:[https://www.volcengine.com/docs/6460/70626](https://www.volcengine.com/docs/6460/70626)。选择容器网络模型为 VPC-CNI(近期也会发布对弹性容器 VCI ... 我们可以在工作流的运行空间中创建相应的 resource policy,通过设置 resource policy 中的 label selector 选定带指定 label 的 Pod 按照预定的资源优先级来运行,实现工作流相关的 Pod 按照业务需求或者资源情况在...
火山引擎DataLeap数据调度实例的 DAG 优化方案 (二):功能设计
对被聚合的节点进行分类,同时新增快捷展开操作。以下图为例,当前实例处于等待上游依赖完成状态,在这种情况下,用户关注的,则是**上游没有开始执行的节点**。在聚合节点中,可以清晰地看到存在一个实例,是在等待执行的... 会在下方出现与选中实例相关信息,包括属性,日志等,协助用户运维任务。 INT8 17 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) INT4 10 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) 软件要求注意 部署Baichuan大语言模型时,需保证CUDA版本 ≥ 1...
GPU-部署ChatGLM-6B模型
中英双语问答的对话语言模型,基于General Language Model(GLM)架构,结合模型量化技术,支持在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。ChatGLM-6B使用了和ChatGLM相同的技术,针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。 软件要求注意 部署ChatGLM-6B语言模型时,需保证CUDA版...
