数据仓库建设方案
 社区干货
社区干货
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持ETL的正常和稳定。建设数据仓库犹如创造一条新的生命,分层架构只是这...
20000字详解大厂实时数仓建设 | 社区征文
数据平台工具对整体实时开发的支持也日渐趋于成熟,开发成本降低。### 2. 实时数仓的应用场景- 实时 OLAP 分析;- 实时数据看板;- 实时业务监控;- 实时数据接口服务。## 三、实时数仓建设方案接下来我们... 实体名称可以根据数据仓库转换整合后做一定的业务抽象的名称,该名称应该准确表述实体所代表的业务含义- 样例:realtime_dwd_trip_trd_order_base---#### 3. DIM 层- 公共维度层,基于维度建模理念思想,建立整...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHous... 先后进行了业务数据的大集中、用户行为数据和 IOT 数据的广泛采集存储,企业和政府单位的数据量每年呈现 30%以上的增长速度。 在过去集中式架构的数据仓库方案中,建设成本与数据总量正相关,成本居高不下;采用...
干货 | 这样做,能快速构建企业级数据湖仓
主要介绍了数据湖仓开源趋势、火山引擎 EMR 的架构及特点,以及如何基于火山引擎 EMR 构建企业级数据湖仓。> > > >  特惠活动
特惠活动
 数据仓库建设方案-优选内容
数据仓库建设方案-优选内容
 数据仓库建设方案-相关内容
数据仓库建设方案-相关内容
DataLeap数据仓库流程最佳实践
# 前言本实验以DataLeap on LAS为例,实际操作火山引擎数据产品,完成数据仓库的构建。# 关于实验* 预计部署时间:50分钟* 级别:初级* 相关产品:大数据开发套件、湖仓一体分析服务LAS* 受众: 通用## 环境说... 经典数据仓库按照大类分为基础数据层、应用数据层。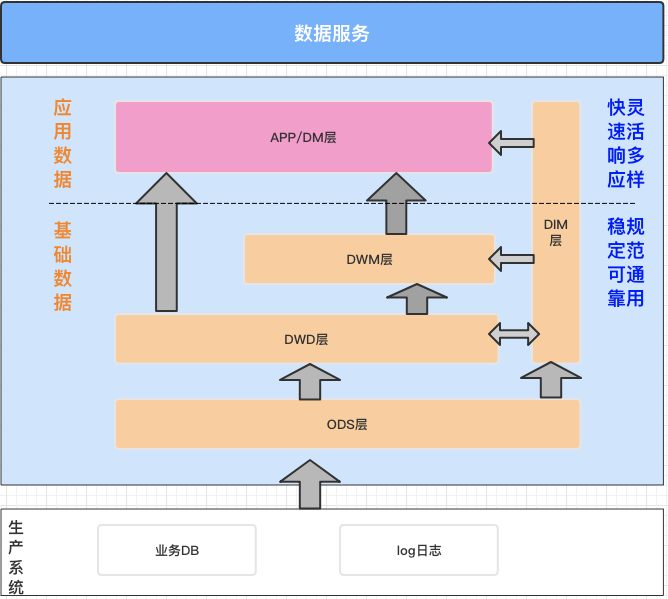本样例中,我们的数据仓库建设思路是:...
基于火山引擎 EMR 构建企业级数据湖仓
数据湖仓开源趋势 **趋势一:数据架构向 LakeHouse 方向发展**什么是 LakeHouse?LakeHouse 简言之是就是在 DataLake 基础上融合了 Data Warehouse 特性的一种数据方案,它既保留了 DataLa... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
观点|SparkSQL在企业级数仓建设的优势
企业在考虑构建自身数仓体系的时候,虽然需要参考现有的行业技术体系,以及可以选择的组件服务,但是不能太过于局限于组件本身,寻找100%开箱即用的产品。太过于局限于寻找完全契合的组件服务必然受限于服务本身的实现,给未来扩展留下巨大的约束。企业数据仓库架构必然不等于一个组件,大部分企业在数仓架构实施的都是都是基于现有的部分方案,进行基于自己业务合适的方向进行部分开发与定制,从而达到一个半自研的稳态,既能跟上业...
SparkSQL 在企业级数仓建设的优势
企业在考虑构建自身数仓体系的时候,虽然需要参考现有的行业技术体系,以及可以选择的组件服务,但是不能太过于局限于组件本身,寻找100%开箱即用的产品。太过于局限于寻找完全契合的组件服务必然受限于服务本身的实现,给未来扩展留下巨大的约束。企业数据仓库架构必然不等于一个组件,大部分企业在数仓架构实施的都是都是基于现有的部分方案,进行基于自己业务合适的方向进行部分开发与定制,从而达到一个半自研的稳态,既能跟上业务变...
基于火山引擎 EMR 构建企业级数据湖仓
构建企业级数据湖仓。## 数据湖仓开源趋势### 趋势一:数据架构向 LakeHouse 方向发展什么是 LakeHouse? LakeHouse 简言之是就是在 DataLake 基础上融合了 Data Warehouse 特性的一种数据方案,它既保留了 Dat... 都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为...
如何快速构建企业级数据湖仓?
构建企业级数据湖仓。# **数据湖** **仓开源趋势**## **趋势一:数据架构向 LakeHouse 方向发展**LakeHouse是什么?简言之,LakeHouse是在 DataLake 基础上融合了 Data Warehouse 特性的一种数据方案,它既保留了... Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 不能将不同粒度的事实建立在同一张事实表中。### 维度表> **维度表是维度建模的灵魂,通常来说,维度表设计得好坏直接决定了维度建模的好坏**维度表包含了 实表所记录的业务过程度量的上下文和环境,它们除了记...
莉莉丝游戏与火山引擎ByteHouse达成合作,为实时数仓建设提速
建设的发展,为广告运营分析等业务领域带来更高效和创新的解决方案。**/ 关于莉莉丝游戏(Lilith **Games** )/**莉莉丝游戏成立于2013年,总部位于中国上海,是一家集游戏研发和全球发行于一体的知名游戏公司。莉莉丝游戏致力于打造优质游戏内容,不断推动游戏行业的创新与发展。目前,莉莉丝游戏在全球范围内拥有众多畅销游戏产品,并积极拓展海外市场。**/ 关于ByteHouse /**ByteHouse是火山引擎旗下的云原生数据仓库,专注...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... Worker 会从最底层的 Cloud Storage 读取数据,并通过建立 Pipeline 的方式进行计算。最终多个 Worker 的计算结果通过 Server 汇聚,并返回给客户端。ByConity 还有两个主要的组件,分别是 Time-stamp Oracle 和 D...
