数据仓库宽表的模型设计
 社区干货
社区干货
浅谈大数据建模的主要技术:维度建模 | 社区征文
怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?> **Ralph Kimball 维度建模理论很好地回答和解决了上述问题。**维度建模理论和技术也是目前在数据仓库领域中使用最为广泛的、也最得到认可和接纳的一项技术。今天我们就来深入探讨 Ralph Kimball 维度建模的各项技术,涵盖其基本理论、一般过程、维度表设计和事实表设计等各个方面,也为我们后面讲Hadoop 数据仓库实战打下基础。## 维度建模关键概念### 度量和环...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化... ByteHouse 定位为一款数据仓库产品,主要用于 OLAP 查询和计算场景。在实时数据接入、大宽表聚合查询、海量数据下复杂分析计算、多表关联查询场景下有非常好的性能。主要的的应用场景如下:、第二范式(2NF)、第三范式(3NF)、Boyce-Codd范式(BCNF)、第四范式(4NF)和第五范式(5NF)。在数据仓库的模型设计中...
DataLeap数据仓库流程最佳实践
我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。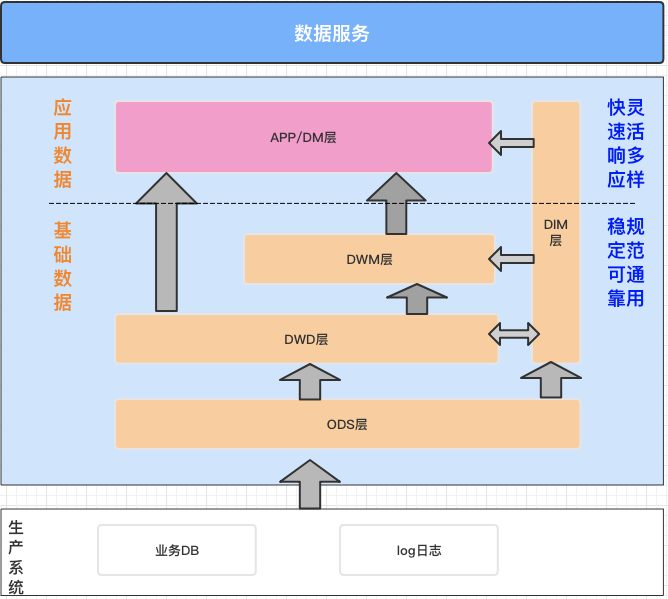本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD...
 特惠活动
特惠活动
 数据仓库宽表的模型设计-优选内容
数据仓库宽表的模型设计-优选内容
 数据仓库宽表的模型设计-相关内容
数据仓库宽表的模型设计-相关内容
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效... 构建最细粒度的明细事实表。可以结合企业的数据使用特点,基于维度建模思想,将明细事实表的某些重要属性字段做适当冗余,也即宽表化处理,构建明细宽表。- DWS:数据仓库汇总层数据(Data Warehouse Summary),基于指...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
数仓多维数据模型详细设计,欢迎一起加入交流探讨,希望能给读者在实际业务场景-OLAP分析演进过程中有些不一样的IDea。 ## 场景目前数据存储的业务类型-**OLTP**,**OLAP......****1、** 其中一种是企业知识库... 兼顾数据仓库,具有实时,批处理,多并发等优点。**Java接入:** ![image.png]...
ELT in ByteHouse 实践与展望
格式各异的数据提取到数据仓库中,并进行处理加工。 传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。... 分别体现在传统大数据方案在及时性上达不到要求以及传统数仓ETL对人员要求高、定位难和链路复杂。但是ByteHouse可以轻松的解决上述问题:将hive数据直接导入到ByteHouse,形成大宽表,后续所有处理都在ByteHouse进行...
ByteHouse技术白皮书正式发布,云数仓核心技术能力首次全面解读
基于云原生架构的数据仓库百花齐放,快速迭代。相比起传统数仓,云原生数据仓库凭借更灵活、更具弹性化的特性,以及有效降低资源、人力成本的能力,在云市场上受到越来越多的关注,逐渐成为企业数字化基础设施中的关键“底座”。 《火山引擎云原生数据仓库 ByteHouse 技术白皮书》简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型...
干货 | 这样做,能快速构建企业级数据湖仓
近几年热门的 ClickHouse 和 Doris 也是 Native 化的表现。### **第二,向量化。**Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 Mone... 大数据最早是批式计算的形式,但理想状态是纯流式方式。分析实时化的表现有(近)实时引擎和流引擎。 * **(近)实时引擎**+ ClickHouse:近实时 OLAP 引擎,宽表查询性能优异+ Doris:近实时全场景 OLAP 引擎+ Dr...
基于 ByteHouse 构建实时数仓实践
灵活支持各类数据分析和保证实时数据高效落盘,实现了热数据按生命周自动冷存,缓解存储空间压力;同时引擎内置了图形化运维界面,可轻松对集群服务状态进行运维;整体架构采用多主对等架构设计,架构安全可靠稳定,可确保单点无故障瓶颈。 ByteHouse 的架构简洁,采用了全面向量化引擎,并配备全新设计的优化器,查询速度有数量级提升(尤其是多表关联查询)。 用户使用 ByteHouse 可以灵活构建包括大宽表、星型模型、雪花模型在...
观点|SparkSQL在企业级数仓建设的优势
数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式... 数仓在构建的时候通常需要ETL处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种ETL处理成为DWD层,再基于DWD层设计上层的数据模型层,形成DM,中间会有DWB/DWS作为部分中间过程数据。从技术选型来...
SparkSQL 在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有... 数仓在构建的时候通常需要ETL处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种ETL处理成为DWD层,再基于DWD层设计上层的数据模型层,形成DM,中间会有DWB/DWS作为部分中间过程数据。从技术选型来说,...
干货 | 看 SparkSQL 如何支撑企业级数仓
本文作者:惊帆 来自于数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDB... 数仓在构建的时候通常需要 ETL 处理和分层设计,基于业务系统采集的结构化和非结构化数据进行各种 ETL 处理成为 DWD 层,再基于 DWD 层设计上层的数据模型层,形成 DM,中间会有 DWB/DWS 作为部分中间过程数据。从技...
