数据仓库与数据挖掘支持度计算
 社区干货
社区干货
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资... 先后进行了业务数据的大集中、用户行为数据和 IOT 数据的广泛采集存储,企业和政府单位的数据量每年呈现 30%以上的增长速度。 在过去集中式架构的数据仓库方案中,建设成本与数据总量正相关,成本居高不下;采用...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、... 负责对计算资源进行统一的管理和调度,能够收集各个计算组的性能数据,为查询、写入和后台任务动态分配资源。同时支持计算资源隔离和共享,资源池化和弹性扩缩等功能。资源管理器是提高集群整体利用率的核心组件。-...
面向智能化BI分析平台建设的初步探索 | 社区征文
### 1、BI的起源与发展 BI又称商业智慧或商务智能,是指用现代数据仓库技术、线上分析处理技术、数据挖掘以及数据展现技术进行数据分析以实现商业价值。 商业智能的概念最早在1996年由加特纳集团提出,加特纳... 首先通过配置标签库,构建相应的业务场景,然后产生相应的报表,如果报表分布出现异常波动变化则会产生预警。针对产生的异常波动预警,BI系统会抽取特征库中的特征构建智能算法,通过智能算法可进行特征贡献度筛选进行归...
ELT in ByteHouse 实践与展望
谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。 传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。现在,以火山引擎ByteHouse为例的云原生数据仓库,凭借其强大的计算能力、可扩展性,开始全面支持Extract-Lo...
 特惠活动
特惠活动
 数据仓库与数据挖掘支持度计算-优选内容
数据仓库与数据挖掘支持度计算-优选内容
 数据仓库与数据挖掘支持度计算-相关内容
数据仓库与数据挖掘支持度计算-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
DataLeap数据仓库流程最佳实践
实验说明 步骤1:创建项目 步骤2:计算资源组设置本案例以湖仓一体Las为例,这里选择已创建的湖仓一体服务完成上述步骤之后,创建好的DataLeap项目如下: 本Demo中以湖仓一体LAS的样例数据为实验数据(TPC-DS中的样例... [维度表] Date_Dim: 时间信息表。 基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况” 经典数据仓库按...
DataLeap数据仓库流程最佳实践
# 前言本实验以DataLeap on LAS为例,实际操作火山引擎数据产品,完成数据仓库的构建。# 关于实验* 预计部署时间:50分钟* 级别:初级* 相关产品:大数据开发套件、湖仓一体分析服务LAS* 受众: 通用## 环境说... ## **步骤2:计算资源组设置**本案例以湖仓一体Las为例,这里选择已创建的湖仓一体服务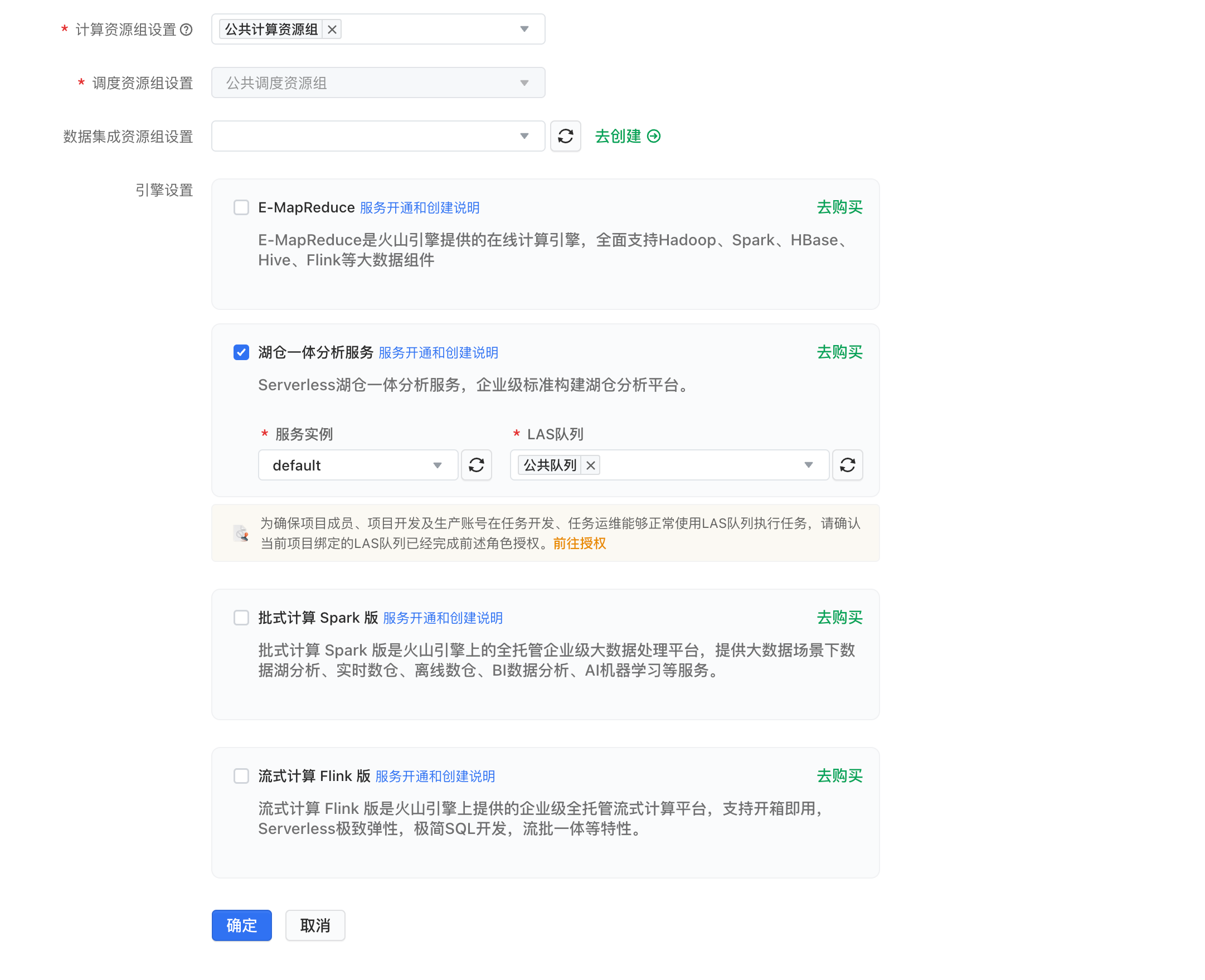完成上...
浅谈数仓建设及数据治理 | 社区征文
而数据仓库只是中间集成化数据管理的一个平台。**源数据**:此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。**数据仓库**:也称为细节层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。**数据应用**:前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据。数据仓库从各数据源...
火山引擎工具技术分享:用AI完成数据挖掘,零门槛完成SQL撰写
经常遇到的问题是:“不会SQL怎么生产加工数据、不会算法可不可以做挖掘分析?” 而专业算法团队在做数据挖掘时,数据分析及可视化也会呈现相对割裂的现象。流程化完成算法建模和数据分析工作,也是一个提效的好... 相同主题的数据内容面临“重复建设,使用和管理时相对分散”的问题——究竟有没有办法在一个任务里同时生产,同主题不同内容的数据集?生产的数据集可不可以作为输入重新参与数据建设? ## **DataWind** **可视化...
以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路
随着数据“爆炸式”的增长,越来越多的数据被产生、收集和存储。而挖掘海量数据中的真实价值,从其中提取商机并洞见未来,则成了现代企业和组织不可忽视的命题。 随着数据量级和复杂度的增大,数据分析处理的技术... ByteHouse 作为云原生的数据平台,从架构层面入手,通过存储和计算分离的云原生架构完美适配云上基础设施。在字节跳动内部,ByteHouse 已经支持 80% 的分析应用场景,包括用户增长业务、广告、A/B 测试等。除了极致的分...
ELT in ByteHouse 实践与展望
谈到数据仓库, 一定离不开使用 Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用 Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的 ETL 系统,因而维护成本较高。现在,以火山引擎 ByteHouse 为例的云原生数据仓库,凭借其强大的计算能力、可扩展性,开始全面支持Extrac...
干货|火山引擎技术工具分享:用AI完成数据挖掘,零门槛完成SQL撰写
不会算法可不可以做挖掘分析?”> > > > > 而专业算法团队在做数据挖掘时,数据分析及可视化也会呈现相对割裂的现象。流程化完成算法建模和数据分析工作,也是一个提效的好办法。> > > > > 同时,对于专业数仓团队来说,相同主题的数据内容面临“重复建设,使用和管理时相对分散”的问题——究竟有没有办法在一个任务里同时生产,同主题不同内容的数据集?生产的数据集可不可以作为输入重新参与数据建设?> > > > ...
