怎么做数据仓库维度表例子
 社区干货
社区干货
浅谈大数据建模的主要技术:维度建模 | 社区征文
维度建模理论和技术也是目前在数据仓库领域中使用最为广泛的、也最得到认可和接纳的一项技术。今天我们就来深入探讨 Ralph Kimball 维度建模的各项技术,涵盖其基本理论、一般过程、维度表设计和事实表设计等各个方... 半加性事实是指仅仅某些维度可加,例如库存,可以把各个地方仓库的库存加起来,或者把一个仓库不同的商品加起来,但是很明显不能把一个仓库同一商品在不同时期的库存加起来。银行的账户余额也是半可加事实的例子,可以...
如何快速从 ETL 到 ELT?火山引擎 ByteHouse 做了这三件事
来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的 ETL 系统,因而维护成本较高。但随着云计算时代的到来,云数据仓库具备更强扩展性和计算能力,也要求改变传统的 ELT 流程。 火山引擎 ByteH... 以及如何通过 3 大能力建设实现完备的 ELT 能力。 # 痛点以及挑战我们先从一个简单的 SSB(start-schema-benchmark)场景出发, 其中包含:- 1 个事实表: lineorder- 4 个维度表:customer, part, suppl...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效... 以上是数据仓库的广泛定义,随着企业数字化转型的大浪潮中,我们需要把数据上升一个维度来看,适合当下这个万物互联的时代,我们可以总结成一句话数据是物理世界的**镜像**,而数据仓库是**有序**还原物理世界的一种*...
浅谈数仓建设及数据治理 | 社区征文
维度表来构建数据仓库、数据集市。目前在互联网公司最常用的建模方法就是维度建模。**维度建模怎么建:**在实际业务中,给了我们一堆数据,我们怎么拿这些数据进行数仓建设呢,数仓工具箱作者根据自身60多年的实际业务经验,给我们总结了如下四步。数仓工具箱中的维度建模四步走: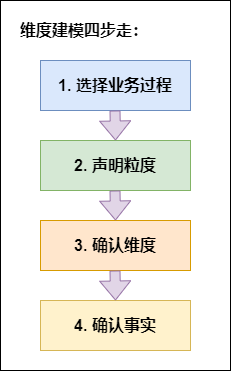这四步是环环相扣,步步相连。下面详细拆解下每个步骤怎么做**1...
 特惠活动
特惠活动
 怎么做数据仓库维度表例子-优选内容
怎么做数据仓库维度表例子-优选内容
 怎么做数据仓库维度表例子-相关内容
怎么做数据仓库维度表例子-相关内容
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... ClickHouse 在复杂查询上例如多表 Join 等操作的性能支持并不是很好。基于这些痛点,字节在 ClickHouse 架构基础上进行了升级,于 2020 年在内部启动了 ByConity 项目,并于 2023 年 1 月发布 Beta 版本,5月底正式...
干货 | 这样做,能快速构建企业级数据湖仓
近几年热门的 ClickHouse 和 Doris 也是 Native 化的表现。### **第二,向量化。**Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走了 Codegen 的道路,因为 Java 做 Codegen 比做向量化要更容易一些。但现在,向量化是一个更好的选择,因为向量化可以一次处理...
字节跳动基于数据湖技术的近实时场景实践
数据湖采用了一种 schema on read 的模式,即不会事先对它的 schema 做过多的定义,而是在使用的时候才去决定 schema,从而支持上游更丰富、更灵活的应用。2. ## **字节**数据湖Apache Hudi有下面非常重要的特性:- Hudi不仅仅是数据湖的一种存储格式(Table Format),而是提供了Streaming 流式原语的、具备数据库、 数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Fl...
观点 | 数据分析引擎百花齐放,为什么要大力投入ClickHouse?
随着云计算等技术发展以及海量数据应用场景等出现,对数据仓库提出全新要求,高性能、实时性、云原生等成为数据仓库发展关键词,也因此演变出不同的数仓发展路径。> > > > > **在字节跳动十年发展历程中,各类业务... ClickHouse扩缩容时需要创建新表重新导数据,十分不方便。ClickHouse集群不能自动感知集群拓扑变化,也不能自动balance数据。当集群数据量较大,复制表和分布式表过多时、想做到表维度、或者集群之间的数据平衡会导致...
20000字详解大厂实时数仓建设 | 社区征文
{自定义表命名标签缩写}:实体名称可以根据数据仓库转换整合后做一定的业务抽象的名称,该名称应该准确表述实体所代表的业务含义- 样例:realtime_dwd_trip_trd_order_base---#### 3. DIM 层- 公共维度层,基... 介绍一下我们是怎么做的: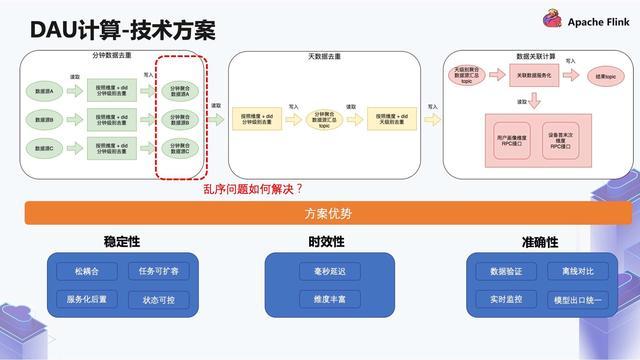如上图的例子,第一步是对 A B C 这三个数据源,先按照维度和 DID 做分钟级别去重,分别去重之后得到三个分钟级别去重的数据...
基于 ByteHouse 构建实时数仓实践
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 **随着数据的应用场景越来越丰富,企业对数据价值反馈到业务中的时效性要求也越来越高,很早就有人提出过一个概念:**... 高可用企业级分析性数据库,支持用户交互式分析 PB 级别数据。其自研的表引擎,灵活支持各类数据分析和保证实时数据高效落盘,实现了热数据按生命周自动冷存,缓解存储空间压力;同时引擎内置了图形化运维界面,可轻松对...
干货 | 看 SparkSQL 如何支撑企业级数仓
安全这几个纬度思考。本文作者:惊帆 来自于数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种... 数仓架构通常是一个企业数据分析的起点,在数仓之下会再有一层数据湖,用来做异构数据的存储以及数据的冷备份。但是也有很多企业,特别是几乎完全以结构化数据为主的企业在实施上会把数据湖和企业数仓库合并,基于某个...
一文读懂火山引擎云数据库产品及选型
数据条件下更复杂,所以图 NoSQL 数据库主要是针对这类场景做了专门的设计与优化,用于进行“关系”数据的存储与查询。从技术角度出发,数据库可以分为关系型数据库与 NoSQL 数据库。**从场景角度出发,数据库又可以分为 OLTP 数据库与 OLAP 数据库**。OLTP(Online trancaction processing),是关系型数据库的主要应用,侧重于交互式的事务处理,例如银行交易、在线订单处理等。OLAP(Online analytical processing) 是数据仓库系统的主...
基于火山引擎 EMR 构建企业级数据湖仓
Presto:现在在做 Velox 的 native 引擎。 Velox 引擎现在还不太成熟,但是根据 Presto 社区的宣称,它可以达到原来 1/3 的成本。所以我们可以猜测,等价情况下可以获得 3X 的性能提升。除了以上两者,近几年火起来的 ClickHouse 和 Doris 也是 Native 化的一个表现。另外一个趋势是向量化。说到这里要提一句,Codegen 跟向量化,都是从数据仓库而不是 Hadoop 体系的产品中长出来的:Codegen 是 Hyper 提出的技术,而向量化则是 M...
