数据仓库的层次不包括
 社区干货
社区干货
浅谈数仓建设及数据治理 | 社区征文
**丰富**:数据涵盖的业务足够广泛。4. **透明**:数据构成体系足够透明。## 二、数仓设计 数仓设计的3个维度:- **功能架构**:结构层次清晰。- **数据架构**:数据质量有保障。- **技术架构**:易扩展、易用。### 1. 数仓架构按照数据流入流出的过程,数据仓库架构可分为:**源数据**、**数据仓库**、**数据应用**。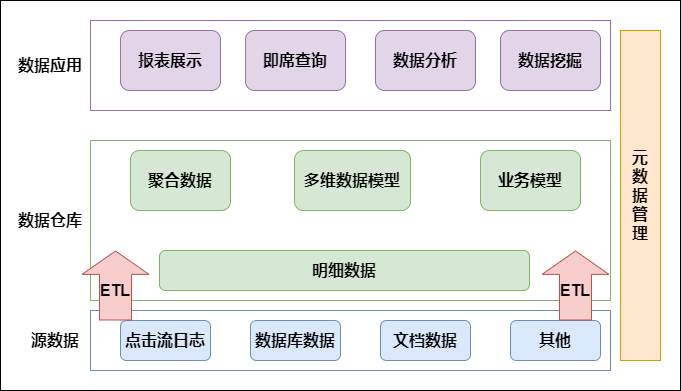数据仓库的数据来源于不同...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
也是数据仓库的**价值所在**,那如何判断有序是关键,我们可以反过来想,有序的反面是无序,那我们判断无序程度,来反向证明有序度。那如何判断无序程序,不能绕过去的一个概念“熵”,它代表一个系统的混乱程度,熵增越大,代表无序程度越高。如何对抗熵增,是数据仓库的一个重要命题,**耗散结构**是最好的方式首先来看下耗散结构的定义所谓耗散结构就是包含多基元 多组 分多层次 的开放系统处于远 离平衡态时在涨落的触发下从无...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、... 每个虚拟集群里包含 0 到多台计算节点,可按照实际资源需求量动态的扩缩容。 一个租户内可以创建 1 个或多个计算组,计算资源扩缩容的方式有两种,一种是调整计算组的 CPU 核数和内存大小实现快速的纵向扩缩容,...
观点 | 数仓领域的未来趋势解读
字节跳动数据平台> > > 数据仓库发展历程很久,随着云计算等技术发展以及海量数据应用场景等出现,对数据仓库提出全新要求,高性能、实时性、云原生等成为数据仓库发展关键词,也因此演变出不同的数仓发展路径。> > > > > **在字节跳动十年发展历程中,各类业务数据量膨胀,不断挑战数据能力边界,也让字节跳动在数据链路优化处理、提升分析效率、数据仓库选型、数据引擎架构搭建等层面积累丰富经验。**> > > > ...
 特惠活动
特惠活动
 数据仓库的层次不包括-优选内容
数据仓库的层次不包括-优选内容
 数据仓库的层次不包括-相关内容
数据仓库的层次不包括-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
观点 | 数据分析引擎百花齐放,为什么要大力投入ClickHouse?
随着云计算等技术发展以及海量数据应用场景等出现,对数据仓库提出全新要求,高性能、实时性、云原生等成为数据仓库发展关键词,也因此演变出不同的数仓发展路径。> > > > > **在字节跳动十年发展历程中,各类业务数据量膨胀,不断挑战数据能力边界,也让字节跳动在数据链路优化处理、提升分析效率、数据仓库选型、数据引擎架构搭建等层面积累丰富经验。**> > > > > 
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
干货 | 看 SparkSQL 如何支撑企业级数仓
本文作者:惊帆 来自于数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDB... 一个典型的数据仓库架构需要包含不同层次的模型构建。由于数据量大,数据结构异构等多种原因,大数据架构下的企业数仓构建抛弃了基于关系型数据库下的 Cube 设计,直接采用基于分布式任务进行处理来构建多层数据模型。...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 读写之间没有不一致;* **高性能** :采用了主流的 OLAP 引擎优化,例如列存、向量化执行、MPP 执行、查询优化等提供优异的读写性能。技术架构----### 整体架构ByConity 的架构分为三层,包括**服务接入层,...
观点|SparkSQL在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台EMR团队EMR 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技... 一个典型的数据仓库架构需要包含不同层次的模型构建。由于数据量大,数据结构异构等多种原因,大数据架构下的企业数仓构建抛弃了基于关系型数据库下的Cube设计,直接采用基于分布式任务进行处理来构建多层数据模型。因...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
