数据仓库常用的工具有哪些
 社区干货
社区干货
干货 | 看 SparkSQL 如何支撑企业级数仓
> 企业级数仓架构设计与选型的时候需要从开发的便利性、生态、解耦程度、性能、 安全这几个纬度思考。本文作者:惊帆 来自于数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效... 都逃脱不了以下的常用分层架构- ODS:操作型数据(Operational Data Store),指结构与源系统基本保持一致的增量或者全量数据。作为DW数据的一个数据准备区,同时又承担基础数据记录历史变化,之所以保留原始数据和线...
SparkSQL 在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心...
观点|SparkSQL在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台EMR团队EMR 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式...
 特惠活动
特惠活动
 数据仓库常用的工具有哪些-优选内容
数据仓库常用的工具有哪些-优选内容
 数据仓库常用的工具有哪些-相关内容
数据仓库常用的工具有哪些-相关内容
观点|SparkSQL在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台EMR团队EMR 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式...
浅谈大数据建模的主要技术:维度建模 | 社区征文
维度建模理论和技术也是目前在数据仓库领域中使用最为广泛的、也最得到认可和接纳的一项技术。今天我们就来深入探讨 Ralph Kimball 维度建模的各项技术,涵盖其基本理论、一般过程、维度表设计和事实表设计等各个方... 有用的和最常见的事就是将它们加起来,而且是从各个角度和维度加起来。> **但事实表中的度量并不都是可加的,有些是半可加性质的,另一些则是非可加性质的**半加性事实是指仅仅某些维度可加,例如库存,可以把各个地...
Hive SQL 底层执行过程 | 社区征文
Hive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行查询。我们今天来聊的就是 Hive 底层是怎样将我们写的 SQL 转化为 MapReduce 等计算引擎可识别的程序。了解 Hive SQL 的底层编译过程有利于我们优化Hive SQL,提升我们对Hive的掌控力,同时有能力去定制一...
浅谈数仓建设及数据治理 | 社区征文
维度表来构建数据仓库、数据集市。目前在互联网公司最常用的建模方法就是维度建模。**维度建模怎么建:**在实际业务中,给了我们一堆数据,我们怎么拿这些数据进行数仓建设呢,数仓工具箱作者根据自身60多年的实际业务经验,给我们总结了如下四步。数仓工具箱中的维度建模四步走: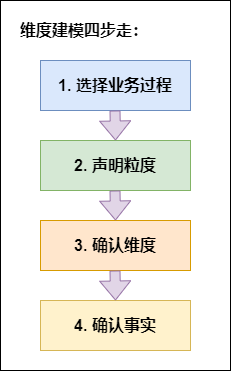这四步是环环相扣,步步相连。下面详细拆解下每个步骤怎么做**1...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 分布式运算符拆分等常见的启发式优化能力。* CBO:基于成本的优化能力。支持:Join Reorder、Outer-Join Reorder、Join/Agg Reorder、CTE、Materialized View、Dynamic Filter Push-Down、Magic Set 等基于成本的优...
ByteHouse:基于ClickHouse的实时数仓能力升级解读
ByteHouse是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。全篇将从两个版块讲解ByteHouse的技术业务场景及实践经验。第一版块将核心介绍ByteHouse于字节内部的业务应用场景,以及使用ClickHouse打造实时数仓的经验。第二板块将集中讲解字节基于ByteHouse对金融行业实时数仓的现状的理解与思考。...
ByConity 技术详解之 Hive 外表和数据湖
初步实现对 Hive 外表及数据湖格式的接入。# 支持 Hive 外表随着企业数据决策的要求越来越高,Hive 数据仓库已成为了许多组织的首选工具之一。通过在查询场景中结合 Hive, ByConity 可以提供更全面的企业决策支... worker 负责从远端文件系统读取数据,整体的执行流程与 CnchMergeTree 基本一致。,需要耐心等待。或者把模型文件托管到共享存储上(如 vePFS、TOS)。 Q:提交任务能否忽略掉一些文件不上传A:支持在上传目录下配置 .gitignore,volc 工具会根据配置...
