数据仓库是多维的数据集对吗
 社区干货
社区干货
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资源利用率方面都有巨大的提升。 截至 2022 年 2 月,ByteHouse 在字节跳动内部部署规模超过 1 万 8000 台,单集群超过 2400 台。经过内部数百个应用场景和数万用户锤炼,并在多个外部企业客户中得到推广应用。##...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎... insert values 可能包含大量数据集,为避免网络传输开销直接由服务节点本地执行 insert 而无需转发给写入节点来执行。 
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
 特惠活动
特惠活动
 数据仓库是多维的数据集对吗-优选内容
数据仓库是多维的数据集对吗-优选内容
 数据仓库是多维的数据集对吗-相关内容
数据仓库是多维的数据集对吗-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
浅谈数仓建设及数据治理 | 社区征文
通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一个白盒,每一层的处理逻辑都相对简单和容易理解,这样我们比较容易保证每一个步骤的正确性,当数据发生错误的时候,往往我们只需要局部调整某个步骤即可。数据仓库之父 Bill Inmon对数据仓库做了定义——面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。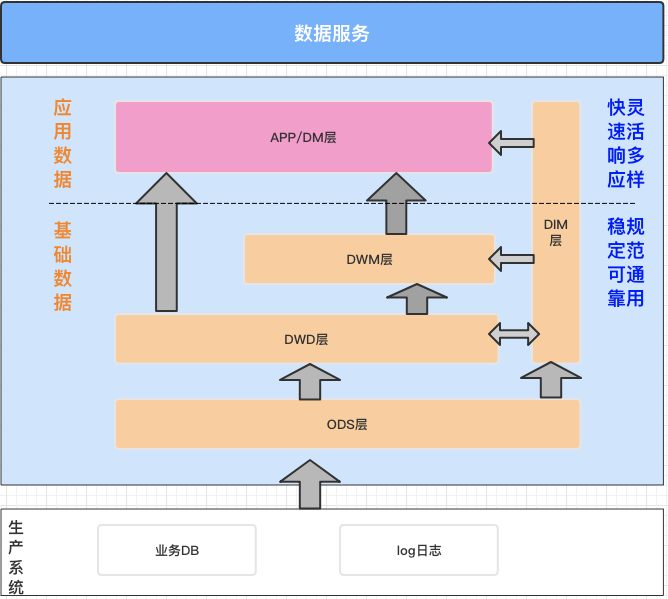本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
勇于迎对,不断的攻克技术难关是技术人的一种追求!数仓多维数据模型详细设计,欢迎一起加入交流探讨,希望能给读者在实际业务场景-OLAP分析演进过程中有些不一样的IDea。 ## 场景目前数据存储的业务类型-**OLTP**,**OLAP......****1、** 其中一种是企业知识库,权限系统,数据由本系统产生,数据量不是很大,但是数据增删改较多; **2、** 另一种是统计分析类型,数据不由本系统产生,来自医院各生产系统,数据集规模极其庞大...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 业务活动有可能并不是那么简单直接 ,此时昕取用户的意见通常是这一环节最为高效的方式。但需要注意的是,这里谈到的业务过程并不是指业务部门或者职能。模型设计中,应将注意力集中放在业务过程而不是业务部门,如果...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
揭秘字节跳动对 Apache Doris 数据湖联邦分析的升级和优化
第一个阶段是数据仓库,第二个阶段是数据湖,第三个阶段是湖仓一体。 ### 1.1 数据仓库阶段数据仓库是在上个世纪80年代兴起的一项技术。随着企业业务发展和大规模计算技术的发展,越来越多的企业使用数据仓库来处... 但非结构化数据在数仓中处理中相对麻烦,于是数据湖技术出现了。 数据湖可以被定义为一种存储各类原始数据的存储库,原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市中,...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
数据聚合到数据仓库中,利用 MPP 等大规模并发技术对企业的数据进行分析,支撑上层的商业分析和决策。## 数据湖阶段数仓的主要特点是只能处理结构化数据。随着数据科学和人工智能的发展,产生了越来越多的非结构化数据,但非结构化数据在数仓中处理中相对麻烦,于是数据湖技术出现了。 数据湖可以被定义为一种存储各类原始数据的存储库,原始数据包含结构化、半结构化以及非结构化数据。一部分原始数据会经过 ETL 同步到数据集市...
