数据仓库存储过程修改代码
 社区干货
社区干货
mysql事物存储过程
MySQL 数据库中的事务和存储过程是两个不同的概念,我将会分别解释这两个概念,然后提供一个简单的存储过程示例。1. **事务(Transaction)**:数据库事务是指一个或一组SQL语句的逻辑单元,这个逻辑单元中的操作要么全部执行,要么全部不执行。如果在执行过程中出现错误,那么事务将会回滚(Rollback),即撤销已经执行的操作;如果所有操作都成功执行,那么事务就会被提交(Commit),数据会被永久保存在数据库中。事务的主要特点是可以保证在...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资... 制造业设备上云和云化改造能够实现制造业企业的数据互通和业务互联,支撑形成以数据驱动的智能化制造、实现供应链和上下游业务的网络化协同,以及实现对业务和设备的数字化管理等制造业发展新模式,引领制造业数字化转...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、... 一种是调整计算组的 CPU 核数和内存大小实现快速的纵向扩缩容,另一种方式是增减计算组的数量实现水平扩容,在存储计算分离的架构下,计算资源与存储资源是解耦的且无状态的,扩缩容过程不需要迁移和平衡数据,因而可以...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
 特惠活动
特惠活动
 数据仓库存储过程修改代码-优选内容
数据仓库存储过程修改代码-优选内容
 数据仓库存储过程修改代码-相关内容
数据仓库存储过程修改代码-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
过程中有些不一样的IDea。 ## 场景目前数据存储的业务类型-**OLTP**,**OLAP......****1、** 其中一种是企业知识库,权限系统,数据由本系统产生,数据量不是很大,但是数据增删改较多; **2、** 另一种是... 兼顾数据仓库,具有实时,批处理,多并发等优点。**Java接入:** ![image.png]...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 数据规模变得越来越巨大。由于 ClickHouse 是 Shared-Nothing 的架构,每个节点是独立的,不会共享存储资源等,因而计算资源和存储资源是紧耦合的,这使得 ClickHouse 在使用过程中会遇到以下情况:* 首先,这导致扩缩...
浅谈大数据建模的主要技术:维度建模 | 社区征文
维度建模理论和技术也是目前在数据仓库领域中使用最为广泛的、也最得到认可和接纳的一项技术。今天我们就来深入探讨 Ralph Kimball 维度建模的各项技术,涵盖其基本理论、一般过程、维度表设计和事实表设计等各个方... 事实表还存储了引用的维度。事实表通常和一个 **企业的业务过程** 紧密相关,由于一个企业的业务过程数据构成了其所有数据的绝大部分,因此事实表也通常占用了数据仓库存储的绝大部分。比如对于某个超市来说,其 ...
使用 Hive 访问 CloudFS 中的数据
Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载。本文介绍如何配置 Hive 服务来访问 CloudFS 中的数据。 前提条件在使用 Hive 服务访问大数据文件存储服务 CloudFS 前,确保您已经完成以下准... 请确认/user/hive/目录中的数据已完成全量迁移。详细操作请参考迁移 Hadoop 文件系统数据至 CloudFS。 步骤一:配置 CloudFS 服务说明 集群所有节点都要修改如下配置。 下载 CloudFS SDK 并解压。下载地址:inf.hd...
浅谈数仓建设及数据治理 | 社区征文
按照数据流入流出的过程,数据仓库架构可分为:**源数据**、**数据仓库**、**数据应用**。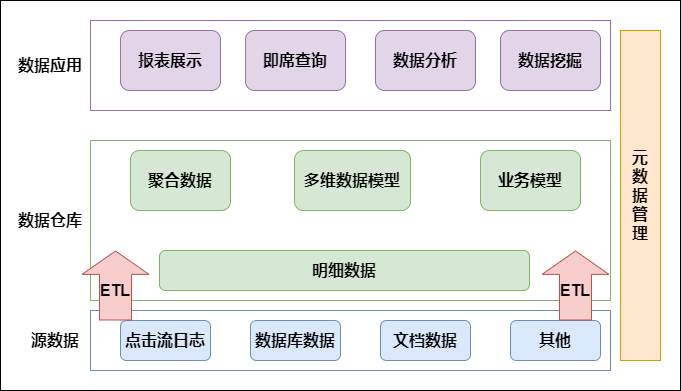数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。**源数据**:此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储...
干货 | 看 SparkSQL 如何支撑企业级数仓
企业数据仓库架构必然不等于一个组件,大部分企业在数仓架构实施的都是都是基于现有的部分方案,进行基于自己业务合适的方向进行部分开发与定制,从而达到一个半自研的稳态,既能跟上业务变化的速度,又不过于依赖和受限于组件自身的发展。一般来说企业级数仓架构设计与选型的时候需要从以下几个纬度思考:- 开发的便利性:所选择的数仓架构是否具有很好的开发生态,可以提供不同类型的开发态接口,不限于 SQL 编辑器,代码提交,以及...
