数据仓库中的事实表
 社区干货
社区干货
浅谈大数据建模的主要技术:维度建模 | 社区征文
怎么组织数据仓库中的数据?- 怎么组织才能使得数据的使用最为方便和便捷?- 怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?> **Ralph Kimball 维度建模理论很好地回答和解决了上述问题。**维度建模理论和技术也是目前在数据仓库领域中使用最为广泛的、也最得到认可和接纳的一项技术。今天我们就来深入探讨 Ralph Kimball 维度建模的各项技术,涵盖其基本理论、一般过程、维度表设计和事实表设计等各个方面,也为我...
DataLeap数据仓库流程最佳实践
样例中的四张表分别代表:* **[事实表] Store_Sales**: 销售记录表。* **[维度表] Customers**: 客户信息表。* **[维度表] Stores**: 商店信息表。* **[维度表] Date_Dim**: 时间信息表。基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。,包含DWD、DWS、DIM层。- DWD:数据仓库明细层数据(Data Warehouse Detail)。对ODS层数据进行清洗转化,以业务过程作为建模驱动,基于每个具体的业务过程特点,构建最细粒度的明细事实表。...
浅谈数仓建设及数据治理 | 社区征文
是数据仓库工程领域最流行的数仓建模经典。维度建模以分析决策的需求出发构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。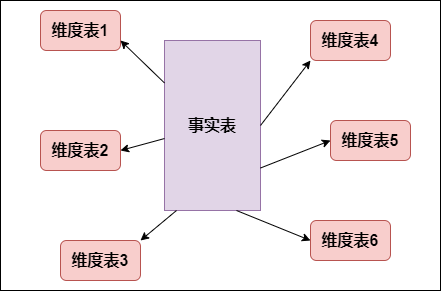典型的代表是我们比较熟知的星形模型(Star-schema),以及在一些特殊场景下适用的雪花模型(Snow-schema)。维度建模中比较重要的概念就是 事实表(Fact t...
 特惠活动
特惠活动
 数据仓库中的事实表-优选内容
数据仓库中的事实表-优选内容
 数据仓库中的事实表-相关内容
数据仓库中的事实表-相关内容
如何快速从 ETL 到 ELT?火山引擎 ByteHouse 做了这三件事
来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的 ETL 系统,因而维护成本较高。但随着云计算时代的到来,云数据仓库具备更强扩展性和计算能力,也要求改变传统的 ELT 流程。 火山引擎 ByteH... 在本文中,我们将重点介绍 ByteHouse 遇到的挑战,以及如何通过 3 大能力建设实现完备的 ELT 能力。 # 痛点以及挑战我们先从一个简单的 SSB(start-schema-benchmark)场景出发, 其中包含:- 1 个事实表: l...
LAS Spark 在 TPC-DS 的优化揭秘
文章主要介绍了火山引擎湖仓一体分析服务 LAS Spark(下文以 LAS Spark 指代)在 TPC-DS 上的性能突破与优化策略。TPC-DS 是一个模拟复杂数据仓库环境的测试基准,LAS Spark 通过采用规则优化、缓存优化和运行时优化三... 性能表现- 自研优化策略- 总结## 1. TPC-DS 简介针对数据库不同的使用场景 TPC 组织发布了多项测试标准。TPC-DS 采用星型、雪花型等多维数据模式。它包含 7 张事实表,17 张纬度表,平均每张表含有...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHous... (Java UDF/UDAF 已在开发中)- 自研优化器:自研 Cost-Based Optimizer,优化多表 JOIN 等复杂查询性能,性能提升若干倍。 **产品能力上,在引擎外提供更加丰富的企业级功能和可视化管理界面:**- 库表资产...
LAS Spark 在 TPC-DS 的优化揭秘
欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群文章主要介绍了火山引擎湖仓一体分析服务 LAS Spark(下文以 LAS Spark 指代)在 TPC-DS 上的性能突破与优化策略。TPC-DS 是一个模拟复杂数据仓库环境... 性能表现- 自研优化策略- 总结 ## TPC-DS 简介针对数据库不同的使用场景 TPC 组织发布了多项测试标准。TPC-DS 采用星型、雪花型等多维数据模式。它包含 7 张事实表,17 张纬度表,平均每张表含有 18...
ByConity 技术详解之 ELT
谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用Extract-Transform-Load ... **数据预计算流派**:如Kylin等。如果Hadoop系统中出报表较慢或聚合能力较差,可以去做一个数据的预计算,提前将配的指标的cube或一些视图算好。实际SQL查询时,可以直接用里面的cube或视图做替换,之后直接返回。...
干货 | 看 SparkSQL 如何支撑企业级数仓
本文作者:惊帆 来自于数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心,...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎... Part 的元数据信息记录表所对应的所有 data file 的元数据,主要包括文件名,文件路径,partition, schema,statistics,数据的索引等信息。元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
SparkSQL 在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心...
