数据仓库有哪些系统
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
数据集合,用于支持管理决策。随着数字化浪潮到来仅仅支撑管理决策暴露出了局限性,**应在管理决策基础上扩展到产品决策、运营决策、服务决策等等** 1、面向主题【微服务、业务过程、数据域】 操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织的。 2、集成的【大一统、全链路】 数据仓库中的数据是在对原有分散的数据库[数据抽取](https://wiki.mbal...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 它们一般都有相应的源头业务系统支持。对于一个超市来说,其最基本的业务活动就是用户收银台付款;对于一个保险公司来说,最基本的业务活动是理赔和保单等 。当然在实际操作中,业务活动有可能并不是那么简单直接 ,此...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
海量数据下复杂分析计算、多表关联查询场景下有非常好的性能。主要的的应用场景如下:# 2.技术趋势和挑战## 业务需求企业级数据仓库场景中,需要融合来自多个业务系统数据库的业务...
浅谈数仓建设及数据治理 | 社区征文
反映历史变化的数据集合,用于支持管理决策。从定义上来看,数据仓库的关键词为面向主题、集成、稳定、反映历史变化、支持管理决策,而这些关键词的实现就体现在分层架构内。一个好的分层架构,有以下好处:1. **清晰数据结构**:每一个数据分层都有对应的作用域,在使用数据的时候能更方便的定位和理解。2. **数据血缘追踪**:提供给业务人员或下游系统的数据服务时都是目标数据,目标数据的数据来源一般都来自于多张表数据。若出现...
 特惠活动
特惠活动
 数据仓库有哪些系统-优选内容
数据仓库有哪些系统-优选内容
 数据仓库有哪些系统-相关内容
数据仓库有哪些系统-相关内容
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。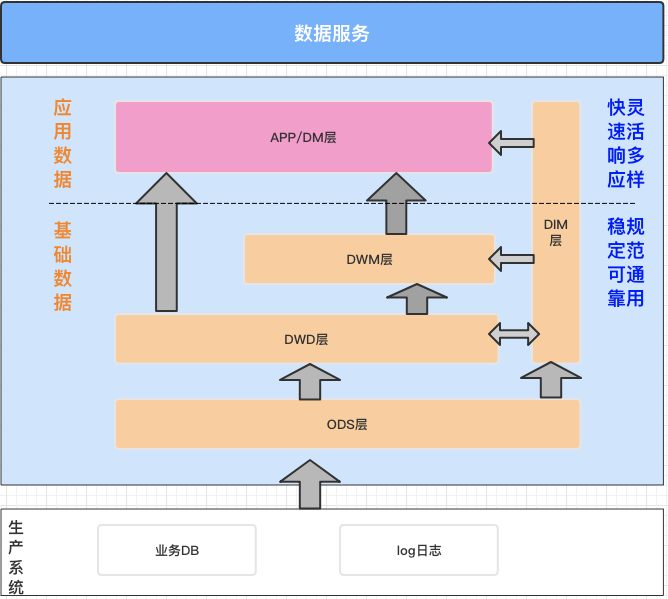本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
使用 Hive 访问 CloudFS 中的数据
Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载。本文介绍如何配置 Hive 服务来访问 CloudFS 中的数据。 前提条件在使用 Hive 服务访问大数据文件存储服务 CloudFS 前,确保您已经完成以下准备工作: 开通大数据文件存储服务 CloudFS 并创建文件存储,获取挂载信息。详细操作请参考创建文件存储系统。 开通 E-MapReduce 服务并创建集群。详细操作请参考E-MapReduce 集群创建。 在配置 Hive 服务之前,请确认/u...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 数据存储层。** 服务接入层负责客户端数据和服务的接入,也就是 ByConity Server;ByConity 的计算资源层,由一个或者多个计算组构成,每个 Virtual Warehouse(VW)是一个计算组;数据存储层由分布式文件系统,如 HDFS、S...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
ByConity 技术详解之 Hive 外表和数据湖
随着大数据处理需求的不断增加,更低成本的存储和更统一的分析视角变得愈发重要。数据仓库作为企业核心决策支持系统,如何接入外部数据存储已经是一个技术选型必须考虑的问题。也出于同样的考虑,ByConity 0.2.0 中发布了一系列对接外部存储的能力,初步实现对 Hive 外表及数据湖格式的接入。# 支持 Hive 外表随着企业数据决策的要求越来越高,Hive 数据仓库已成为了许多组织的首选工具之一。通过在查询场景中结合 Hive, ByConity...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
