数据仓库的4种存储结构
 社区干货
社区干货
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、身份验证、查询优化器,事务管理、安全管理、元数据管理,以及运维监控、数据查询等可视化操作功能。 **服务层主要包括如下组件:**- **资源管理器**资源管理器(Resource Manager)负责对计算资源进行统一的...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 以下为 ByteHouse 技术白皮书前两个版块摘录。# 1.ByteHouse 简介ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资源利用率方...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的 OLAP 引擎优化,如列存储、向量化执行、MPP 执行、查询优化等,ByConity 可以提供优异的读写性能。项目背景----ByConity 的背景可以追溯到 2018 年,当时字节跳动开始在内部使用 ClickHouse,因为业务的发展,要...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
 特惠活动
特惠活动
 数据仓库的4种存储结构-优选内容
数据仓库的4种存储结构-优选内容
 数据仓库的4种存储结构-相关内容
数据仓库的4种存储结构-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
干货|从MySQL到ByteHouse,抖音精准推荐存储架构重构解读
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/c920cf14da69409f906a3ec908908ed3~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1715962835&x-signature=aqK1DXLeSpT4kned56F2wJxPECg%3D) 底层存储架构从MySQL到ByteHouse的重构,将抖音精准推荐的查询效率平均提升了近百倍。**点击阅读原文可下载《云原生数据仓库ByteHouse技术白皮书》。** ![picture.image]...
火山引擎ByteHouse:分析型数据库如何设计列式存储
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 列式存储通过支持按列存储数据,提供高性能的数据分析和查询。作为云原生数据仓库的 ByteHouse,也采用列式存储设计,保证读写性能、支持事务一致性,又适用大规模的数据计算,为用户提供极速分析体验和海量数据处理能力,提升企业数字化转型能力。# 列式存储介绍分析型数据库中的列式存储,是一种数据库的物理存储结构,它是根据数据的列...
DataLeap数据仓库流程最佳实践
经典数据仓库按照大类分为基础数据层、应用数据层。 本样例中,我们的数据仓库建设思路是: ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表) DWD(对ODS冗余表数据进行轻度过滤处理) DWM (基于DWD表与业务需求,轻度聚合最近三天的数据) APP (基于DWD或DWM,输出具体报表信息) 在“数据地图”中创建数据仓库中要使用到的表:本案例中库信息为:demo_tpc_ds_2022_11_07_59(请结合具体情况修改) 步骤4: 数据仓库分层建表ODS(...
[数据库系统] 业界列式存储浅析
行存的实现一般是将一行数据完整的从头到尾连续存储(超长的字段一般会单独存储,行内记录逻辑地址),连续多行构成一个页,页的尾部通常会存储索引来解决record不定长时的快速查找问题,数据排列结构如下图所示: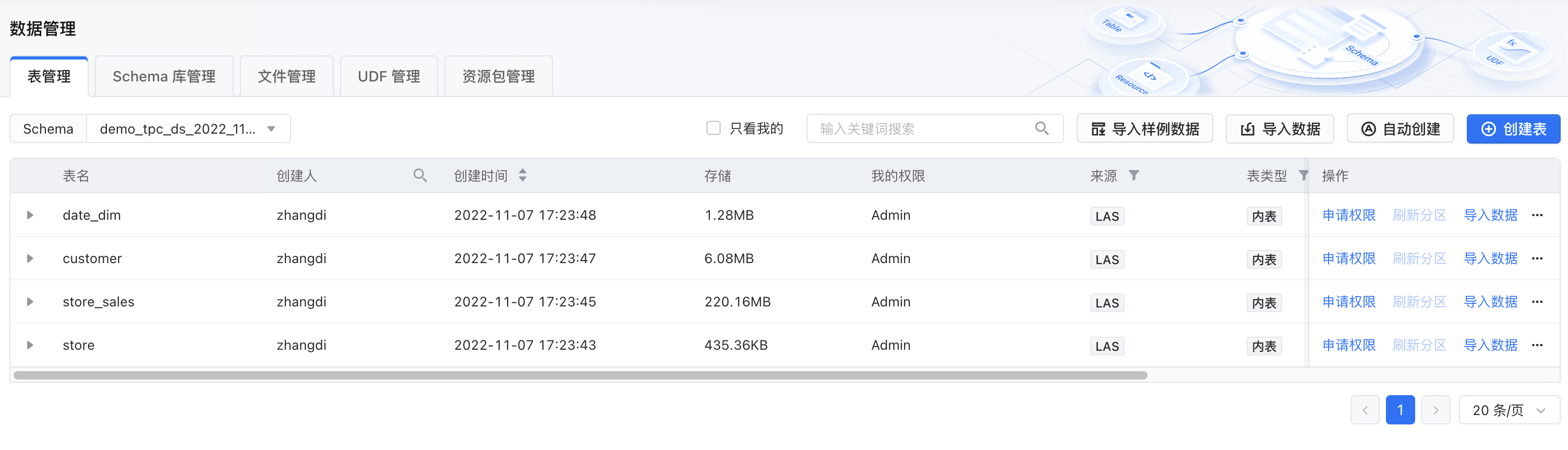样例中的四张表分别代表:* **[事实表] Store_Sales**: 销售记录表。*...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 事实表还存储了引用的维度。事实表通常和一个 **企业的业务过程** 紧密相关,由于一个企业的业务过程数据构成了其所有数据的绝大部分,因此事实表也通常占用了数据仓库存储的绝大部分。比如对于某个超市来说,其 ...
