数据仓库分层dm层
 社区干货
社区干货
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... **数据轻度汇总层DM**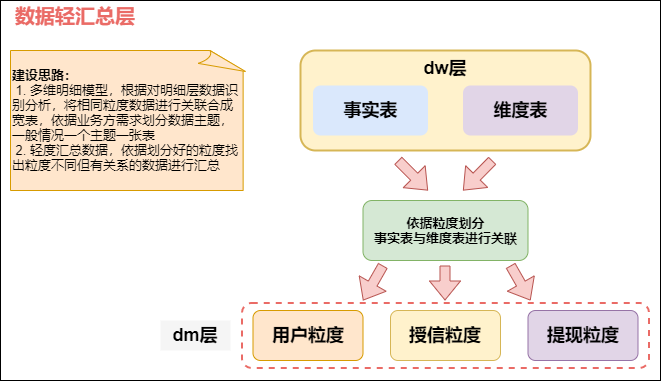此层命名为轻汇总层,就代表这一层已经开始对数据进行汇总,但是不是完全汇总,只是对相同粒度的数据进行关联...
观点|SparkSQL在企业级数仓建设的优势
通常运行在DM层上的任务时间在分钟作为单位。基于如上的分层设计的架构图可以发现,虽然目前有非常多的组件,像Presto、Doris、ClickHouse等等,但是这些组件各自工作在不同的场景下,像数仓构建和交互式分析就是两个典型的场景。**交互式分析强调的是时效性**,一个查询可以快速出结果,像Presto、Doris、ClickHouse虽然也可以处理海量数据,甚至达到PB及以上,但是主要还是是用在交互式分析上,也就是基于数据仓库的DM层,给...
SparkSQL 在企业级数仓建设的优势
通常运行在DM层上的任务时间在分钟作为单位。基于如上的分层设计的架构图可以发现,虽然目前有非常多的组件,像Presto、Doris、ClickHouse等等,但是这些组件各自工作在不同的场景下,像数仓构建和交互式分析就是两个典型的场景。**交互式分析强调的是时效性**,一个查询可以快速出结果,像Presto、Doris、ClickHouse虽然也可以处理海量数据,甚至达到PB及以上,但是主要还是是用在交互式分析上,也就是基于数据仓库的DM层,给用户提供...
DataLeap数据仓库流程最佳实践
轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表: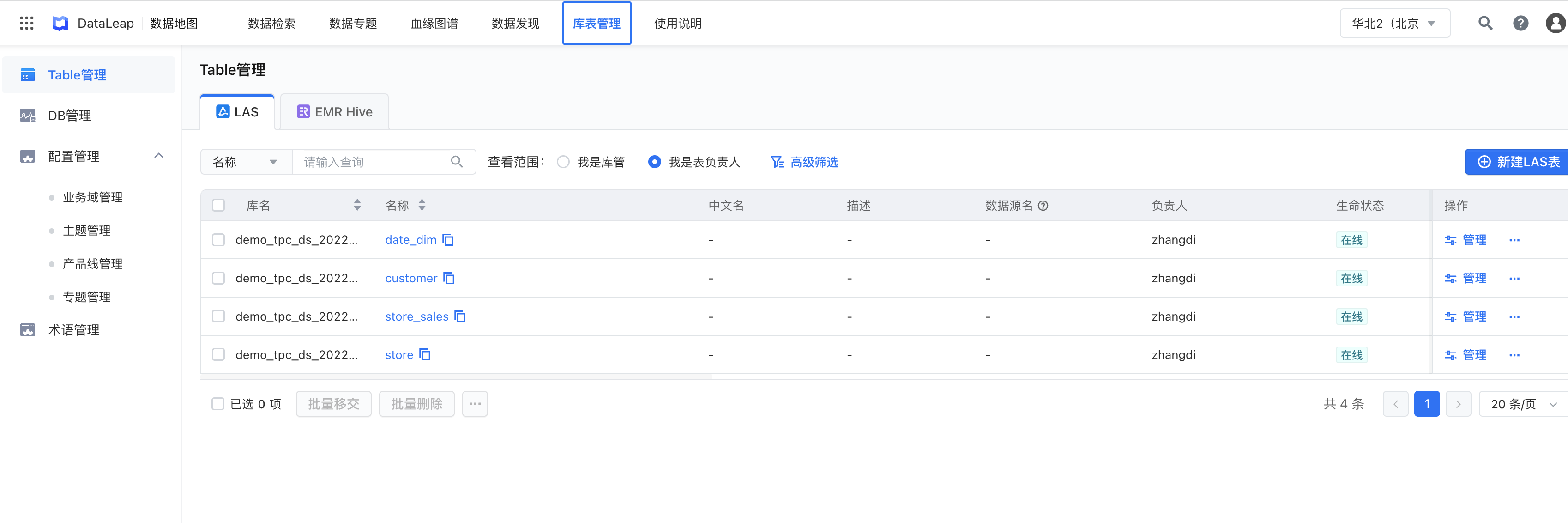本案例中库信息为:demo_tpc_ds_2022_11_07_59(请结合具体情况修改)## **步骤4:** **数据仓库分层建表**### ODS(数据聚合宽表)```sqlCREATE TABLE demo_tpc_ds_2022_11_07_59.ods_demo_cus...
 特惠活动
特惠活动
 数据仓库分层dm层-优选内容
数据仓库分层dm层-优选内容
 数据仓库分层dm层-相关内容
数据仓库分层dm层-相关内容
干货 | 看 SparkSQL 如何支撑企业级数仓
通常运行在 DM 层上的任务时间在分钟作为单位。基于如上的分层设计的架构图可以发现,虽然目前有非常多的组件,像 Presto,Doris,ClickHouse,Hive 等等,但是这些组件各自工作在不同的场景下,像数仓构建和交互式分析就是两个典型的场景。交互式分析强调的是时效性,一个查询可以快速出结果,像 Presto,Doris,ClickHouse 虽然也可以处理海量数据,甚至达到 PB 及以上,但是主要还是是用在交互式分析上,也就是基于数据仓库的 DM 层,给用...
观点 | 数仓领域的未来趋势解读
DM%2Bto%3D)扫码进入官方交流群群内定期进行干货分享技术交流、福利放送 字节跳动数据平台> > > 数据仓库发展历程很久,随着云计算等技术发展以及海量数据应用场... 各类业务数据量膨胀,不断挑战数据能力边界,也让字节跳动在数据链路优化处理、提升分析效率、数据仓库选型、数据引擎架构搭建等层面积累丰富经验。**> > > > > > 
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
ByteHouse:基于ClickHouse的实时数仓能力升级解读
ByteHouse是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。全篇将从两个版块讲解... 就可以应用到实时数仓的存储层面。从上图来看,各种各样的数据源都可以通过Kafka或者Flink写入到ByteHouse里面,然后来对接上层的应用。按照数仓分层角度,Kafka、Flink可以理解为ODS层,那ByteHouse就可以理解为DWD...
ELT in ByteHouse 实践与展望
谈到数据仓库, 一定离不开使用 Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用 Extract-Transform-L... 而这种查询分析底层对接了 ByteHouse 的大数据引擎,最后实现秒级甚至是亚秒级分析的决策。整个过程包括智能诊断、智能规划以及策略到投放效果评估闭环,最终实现智能营销和精细化运营。**ETL 场景**ELT 与 E...
干货 | ELT in ByteHouse 实践与展望
=&rk3s=8031ce6d&x-expires=1715876451&x-signature=CR7BN4TgQOTQLY%2Bj0qBf%2FdYdMuc%3D) 谈到数据仓库, 一定离不开使用 **Extract-Transform-Load (ETL)**或 **Extract-Load-Transform (ELT)**。将来... 而这种查询分析底层对接了**ByteHouse**的大数据引擎,最后实现秒级甚至是亚秒级分析的决策。整个过程包括智能诊断、智能规划以及策略到投放效果评估闭环,最终实现智能营销和精细化运营。### **5. ETL 场景**...
干货|ByteHouse:百万级TPS!看字节跳动如何基于ClickHouse落地高性能实时数仓
> yteHouse 是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。> > > > > **全... =&rk3s=8031ce6d&x-expires=1716049248&x-signature=5BfwuGY8QTCd3j1rzrurMww54DM%3D)面对这些需求,ByteHouse团队选择了ClickHouse作为实时数仓的承载。**时效性、数据准确、开发运维成本低,这些跟Click...
干货 | 这样做,能快速构建企业级数据湖仓
Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走... 冷数据可以存储在对象存储 TOS 上。CloudFS 则构建在 TOS 层之上,提供兼容 HDFS 语义存储,提供缓存加速功能,可以把温数据放在 CloudFS 。在引擎内部内置一些本地缓存,用于缓存热数据。分层缓存能够弥补企业上云之后...
