数据仓库中常用的工具有
 社区干货
社区干货
干货 | 看 SparkSQL 如何支撑企业级数仓
目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN 上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心,这一系列组合让 Hive 完整的具备了构建一个企业级数据仓库的所有特性,并且 Hive...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资源利用率方面都有巨大的提升。 截至 2022 年 2 月,ByteHouse 在字节跳动内部部署规模超过 1 万 8000 台,单集群超过 2400 台。经过内部数百个应用场景和数万用户锤炼,并在多个外部企业客户中得到推广应用。##...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
DataLeap数据仓库流程最佳实践
这里选择已创建的湖仓一体服务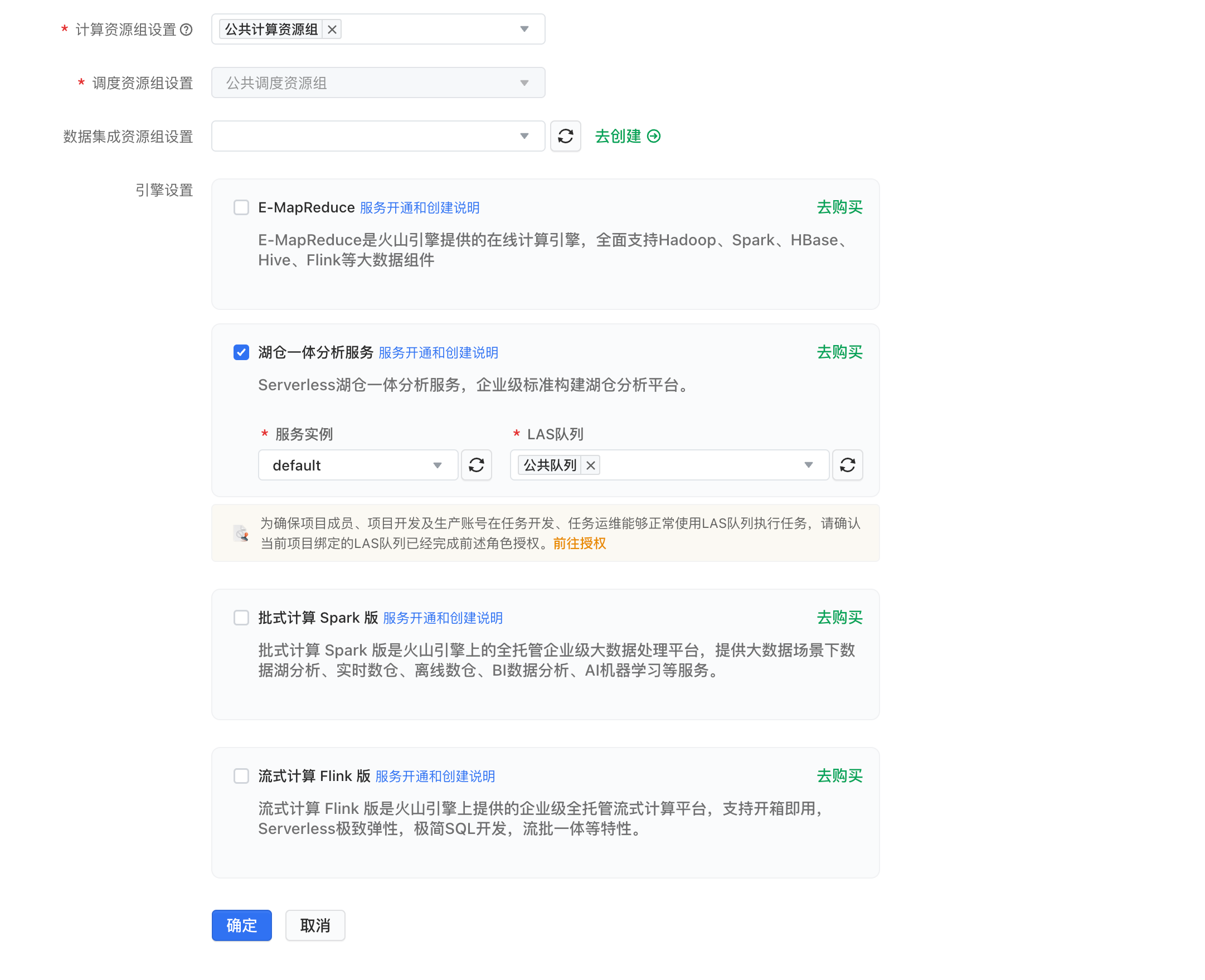完成上述步骤之后,创建好的DataLeap项目如下:* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表...
 特惠活动
特惠活动
 数据仓库中常用的工具有-优选内容
数据仓库中常用的工具有-优选内容
 数据仓库中常用的工具有-相关内容
数据仓库中常用的工具有-相关内容
DataLeap数据仓库流程最佳实践
这里选择已创建的湖仓一体服务完成上述步骤之后,创建好的DataLeap项目如下:* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表...
SparkSQL 在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有 JDBC 客户端,支持标准 JDBC 接口访问的 HiveServer2 服务器,管理元数据服务的 Hive Metastore,以及任务以 MapReduce 分布式任务运行在 YARN上。标准的 JDBC 接口,标准的 SQL 服务器,分布式任务执行,以及元数据中心...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎... Part 的元数据信息记录表所对应的所有 data file 的元数据,主要包括文件名,文件路径,partition, schema,statistics,数据的索引等信息。元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对...
浅谈大数据建模的主要技术:维度建模 | 社区征文
怎么组织数据仓库中的数据?- 怎么组织才能使得数据的使用最为方便和便捷?- 怎么组织才能使得数据仓库具有良好的可扩展性和可维护性?> **Ralph Kimball 维度建模理论很好地回答和解决了上述问题。**维度建模... 有用的和最常见的事就是将它们加起来,而且是从各个角度和维度加起来。> **但事实表中的度量并不都是可加的,有些是半可加性质的,另一些则是非可加性质的**半加性事实是指仅仅某些维度可加,例如库存,可以把各个地...
观点|SparkSQL在企业级数仓建设的优势
数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技术组件,而是一种设计理念。Hive有JDBC客户端,支持标准JDBC接口访问的HiveServer2服务器,管理元数据服务的Hive Metastore,以及任务以MapReduce分布式任务运行在YARN上。标准的JDBC接口,标准的SQL服务器,分布式任务执行,以及元数据中心,这一系列组合让Hive完整的具备了构建一个企业级数据仓库的所有特性,并且Hive的SQL服务器是目前使用最广泛的标准服务器。...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研... 提供更流畅的数据分析体验。通过智能优化算法和先进的执行技术,ByteHouse 能够更好地应对各种复杂的查询场景。 点击这里,即刻获取完整白皮书。
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上)(中)精彩回顾: ## ByteHou...
浅谈数仓建设及数据治理 | 社区征文
建设数据仓库犹如创造一条新的生命,分层架构只是这条生命的逻辑骨架而已。想要在骨架上长出血肉,就必须进行合适的数据建模,数据仓库的强壮还是孱弱,健美还是丑陋,就取决于建模的结果。### 2. 数仓建模方法数据仓库的建模方法有很多种,*每一种建模方法代表了哲学上的一个观点*,代表了一种归纳、概括世界的一种方法。常见的有 **范式建模法、维度建模法、实体建模法**等,*每种方法从本质上将是从不同的角度看待业务中的问题*。...
