数据仓库指标管理系统
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
数据仓库广泛定义:数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策。随着数字化浪潮到来仅仅支撑管理决策暴露出了局限性,**应在管理决策基础上扩展到产品决策、运营决策、服务决策等等** 1、面向主题【微服务、业务过程、数据域】 操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、... 用来存储实际数据、索引等内容。 数据表的数据文件存储在远端的统一分布式存储系统中,与计算节点分离开来。底层存储系统可能会对应不同类型的分布式系统。例如 HDFS,Amazon S3, Google cloud storage,Azure ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资... 企业级数据仓库场景中,需要融合来自多个业务系统数据库的业务数据,主要是交易记录,例如银行存取记录、用户订单记录等,通常是数千万至数亿条规模;用户行为日志是数据量最大的数据源,包括用户访问日志、用户操作记录...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
 特惠活动
特惠活动
 数据仓库指标管理系统-优选内容
数据仓库指标管理系统-优选内容
 数据仓库指标管理系统-相关内容
数据仓库指标管理系统-相关内容
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。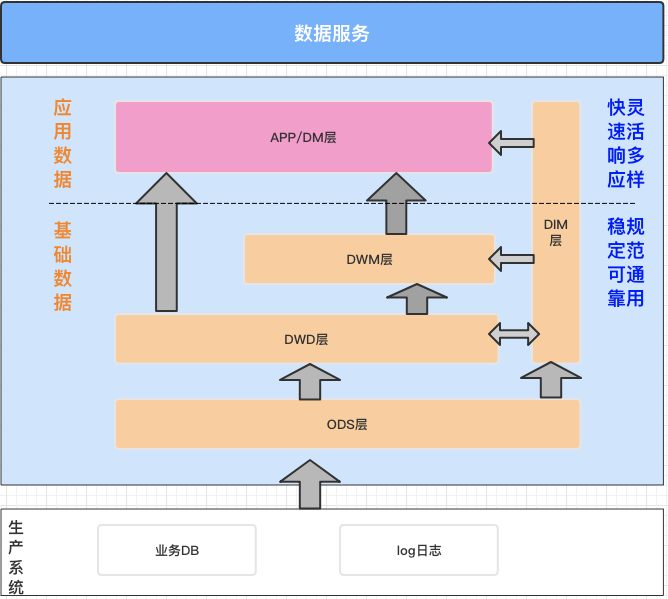本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。2. 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,相当于把一个复杂的工作拆成了多个简单的工作,把一个大的黑盒变成了一...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上...
字节跳动开源其云原生数据仓库 ByConity
项目简介-----ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的... 数据平台团队决定独立开源,并跟 ClickHouse 社区消息同步。** 功能特性ByConity 计算与存储分离的架构,将原本计算和存储分别在每个节点本地管理的架构,转换为在分布式存储上统一管理整个集群内所有...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
干货|3步打造“指标管理”体系,幸福里数据中心是这么做的
**●** 通过DataLeap 实现指标建设流程线上化、规范化,完成指标命名、指标新增与变更流程;**●** DataLeap功能上更加全面和丰富,支持指标拆解、维度管理、词根管理等操作;**●** 对业务侧使用更加友好,指标提需、口径变更进行流程化管理,可以串联起数据BP、分析师和业务共同维护指标。 LOOK是幸福里内部效率管理系统,除作业功能模块外,销售人员作业数据分析也是LOOK重要功能,通过数据及时监控内部员工作业...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。文章来源|ByConity 开源社区GitHub |h... 未来我们将推动 ByConity 数据湖方案的测试与落地。另外,我们会将数据指标管理与数仓理论相结合,将 80%的查询落到数仓上。欢迎大家一起加入体验。GitHub |https://github.com/ByConity/ByConity