数据仓库的两类用户
 社区干货
社区干货
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
两个版块摘录。# 1.ByteHouse 简介ByteHouse 是字节跳动自主研发的云原生数据仓库产品,在开源 ClickHouse 引擎之上做了技术架构重构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等功能。在可扩展性、稳定性、可运维性、性能以及资源利用率方面都有巨大的提升。 截至 2022 年 2 月,ByteHouse 在字节跳动内部部署规模超过 1 万 8000 台,单集群超过 2400 台。经过内部数百个应用场景和数万用户锤炼,并在...
DataLeap数据仓库流程最佳实践
基于上述表数据,我们的数据分析需求如下:1)“查看最近三天商店销售额情况(未促销)TOP3”2)“查看最近三天消费最多的用户与金额TOP3”3)“获取商店地域分布情况”经典数据仓库按照大类分为基础数据层、应用数据层。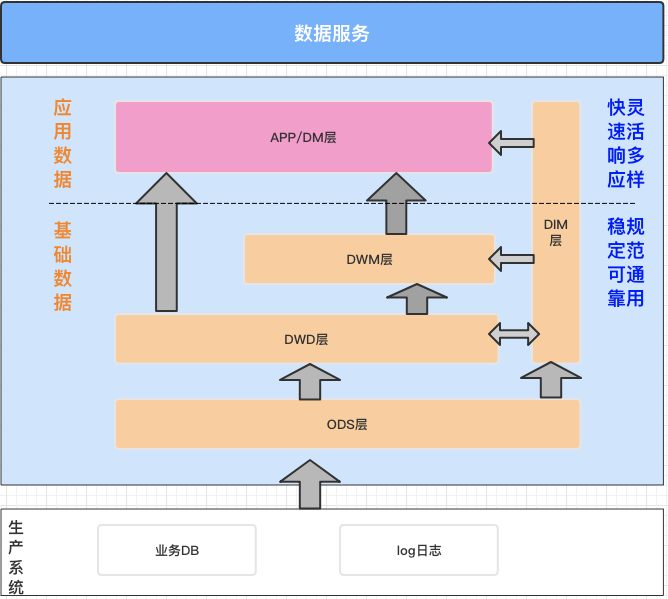本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成...
ByConity 技术详解之 ELT
来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。ByConity 作为云原生数据仓库,从0.2.0版本开始逐步支持 Extract-Load-Transform (ELT),使用户免于维护多套异构数据... 两套不同的ETL逻辑。当数据量变大,计算冗余以及存储冗余所带来的成本压力也会愈发变大,同时,存储空间的膨胀也会让弹性扩容变得不便利。### 业界解决思路在业界中,为了解决以上问题,有以下几类流派:- **数...
浅谈数仓建设及数据治理 | 社区征文
## 一、前言在谈数仓之前,先来看下面几个问题:### 1. 数仓为什么要分层?1. 用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业... 数据仓库模型的建设方法和业务系统的企业数据模型类似。在业务系统中,企业数据模型决定了数据的来源,而企业数据模型也分为两个层次,即主题域模型和逻辑模型。同样,主题域模型可以看成是业务模型的概念模型,而逻辑模...
 特惠活动
特惠活动
 数据仓库的两类用户-优选内容
数据仓库的两类用户-优选内容
 数据仓库的两类用户-相关内容
数据仓库的两类用户-相关内容
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅳ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群**近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。技术白皮书(Ⅰ)(Ⅱ...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅲ)
为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。以下为 ByteHouse 技术白皮书**作业执行流程版块**摘录。技术白皮书(上)(中)精彩回顾: ## ByteHouse 作业执行流程ByteHouse 中的作业按照响应优先级分为 3 大类:Read query、Write query 和 Background 的作业。不同类型的作业,按照前面所述,可以运行同一个工作节点上,也可以分离开来。### 数据查询流程服务节点负责响应和接受用户查询请求,并...
云原生数据仓库ByteHouse性能白皮书(企业版)|火山引擎
白皮书下载 下载《云原生数据仓库ByteHouse性能白皮书(企业版)》 白皮书简介 在选择OLAP引擎时,性能是一个重要的因素。高性能,意味着:更短响应时间、更快处理能力、更好用户体验...... ByteHouse 是火山引擎自主研发的云原生数据仓库产品,它全面继承了开源 ClickHouse 的高性能和强大的分析能力,并在架构上遵循新一代云原生理念进行全面重构,实现了容器化、存储计算分离、多租户管理和读写分离等功能。在可扩展性、稳定性、可运维...
浅谈大数据建模的主要技术:维度建模 | 社区征文
## 前言我们不管是基于 Hadoop 的数据仓库(如 Hive ),还是基于传统 MPP 架构的数据仓库(如Teradata ),抑或是基于传统 Oracle 、MySQL 、MS SQL Server 关系型数据库的数据仓库,其实都面临如下问题:- 怎么组织数... 以方便下游用户使用。维度属性是查询约柬条件( SQL where 条件)、分组( SQL group 语句)与报表标签生成的基本来源在查询与报表需求中, 属性用 by (按)这个单词进行标识。> **维度属性在数据仓库中承担着一个重...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅴ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【多租户管理、运维监控管理】版块摘...
字节跳动开源其云原生数据仓库 ByConity
ByConity 是字节跳动开源的云原生数据仓库,它采用计算-存储分离的架构,支持多个关键功能特性,如计算存储分离、弹性扩缩容、租户资源隔离和数据读写的强一致性等。通过利用主流的 OLAP 引擎优化,如列存储、向量化执行、MPP 执行、查询优化等,ByConity 可以提供优异的读写性能。项目背景----ByConity 的背景可以追溯到 2018 年,当时字节跳动开始在内部使用 ClickHouse,因为业务的发展,要服务于大量的用户,数据规模变得越来越...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
ByConity 替换 ClickHouse 构建 OLAP 数据平台,资源成本大幅降低
作者|程伟,MetaAPP 大数据研发工程师【项目地址】GitHub |https://github.com/ByConity/ByConity> ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致... 最后通过 OLAP 查询平台获取数据进行查询。## ByConity 和 ClickHouse 功能对比**ByConity** ****是基于 ClickHouse 内核研发的开源云原生数据仓库,采用存算分离的架构。两者都具有以下特点:- 写入速度非常...
字节跳动基于数据湖技术的近实时场景实践
数据仓库核心功能(高效upsert/deletes、索引、压缩优化)的数据湖平台。 - Hudi 支持各类计算、查询引擎(Flink、Spark、Presto、Hive),底层存储兼容各类文件系统 (HDFS、Amazon S3、GCS、OSS) - Hudi 使用 Timeline Service机制对数据版本进行管理,实现了数据近实时增量读、写。 - Hudi 支持 Merge on Read / Copy on Write 两种表类型,以及Read Optimized / Real Time 两种Query模式,用户可以在海量的低加工的数据之上,根...
