数据仓库是一个面向什么的集合
 社区干货
社区干货
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
降本是技术的使命,即让数据高效复用,减少重复开发2、增效是技术的价值,即降低数据使用门槛,让数据服务无处不在3、清晰明了是数据GPS,即清晰的管理、追踪、定位数据把为什么想清楚了,接下来就是探讨数据仓库是什么,是否能满足以上的诉求# 二、是什么,数据仓库定义数据仓库广泛定义:数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用...
浅谈数仓建设及数据治理 | 社区征文
反映历史变化的数据集合,用于支持管理决策。从定义上来看,数据仓库的关键词为面向主题、集成、稳定、反映历史变化、支持管理决策,而这些关键词的实现就体现在分层架构内。一个好的分层架构,有以下好处:1. **清晰数据结构**:每一个数据分层都有对应的作用域,在使用数据的时候能更方便的定位和理解。2. **数据血缘追踪**:提供给业务人员或下游系统的数据服务时都是目标数据,目标数据的数据来源一般都来自于多张表数据。若出现...
观点 | 数仓领域的未来趋势解读
字节跳动数据平台> > > 数据仓库发展历程很久,随着云计算等技术发展以及海量数据应用场景等出现,对数据仓库提出全新要求,高性能、实时性、云原生等成为数据仓库发展关键词,也因此演变出不同的数仓发... 数据库引擎百花齐放,为什么要大力投入ClickHouse?* **落地方案篇:**如何构建面向海量数据、高实时要求的一个企业级OLAP数据引擎?* **最佳实践篇:**深入产业实践,剖析最佳实践  特惠活动
特惠活动
 数据仓库是一个面向什么的集合-优选内容
数据仓库是一个面向什么的集合-优选内容
 数据仓库是一个面向什么的集合-相关内容
数据仓库是一个面向什么的集合-相关内容
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.03
安全等全套数据中台建设,提升数据研发效率、降低管理成本。搭配 EMR/LAS 大数据存储计算引擎,加速企业数据中台及湖仓一体平台建设,为企业数字化转型提供数据支撑。**火山引擎云原生数据仓库** **ByteHouse**云原生数据仓库,为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。**火山引擎湖仓一体分析服务 LAS**面向湖仓一体架构...
「火山引擎」数据中台产品双月刊 VOL.03
安全等全套数据中台建设,提升数据研发效率、降低管理成本。搭配 EMR/LAS 大数据存储计算引擎,加速企业数据中台及湖仓一体平台建设,为企业数字化转型提供数据支撑。### **火山引擎云原生数据仓库** **ByteHouse**云原生数据仓库,为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。### **火山引擎湖仓一体分析服务 LAS**面向湖仓...
SparkSQL 在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台 EMR 团队# 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive 已经不单单是一个技术组件,而是一种设计理念。Hive 有... 通常工作在企业的DM层直接面向业务,处理业务需求。- Hive、Spark:更注重任务的稳定性,对网络,IO要求比较高,有着完善的中间临时文件落盘,节点任务失败的重试恢复,更加合适小时及以上的长时任务运行,工作在企业的...
「火山引擎数据中台产品双月刊」 VOL.06
提升数据研发效率、降低管理成本。搭配 EMR/LAS 大数据存储计算引擎,加速企业数据中台及湖仓一体平台建设,为企业数字化转型提供数据支撑。**火山引擎** **云原生** **数据仓库** **ByteHouse**云原生数据仓库,为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。**火山引擎** **湖仓一体分析服务 LAS**面向湖仓一体架构的 Serve...
从思考到实践,企业级大数据平台的构建之路
点击上方👆蓝字关注我们! 伴随着移动互联网、5G、AI、IoT 的飞速发展,企业数据建设正处于更大规模和更多样的变化趋势中。传统自建数据仓库,在企业数据体量持续增长、业务时效性持续提升的... 火山引擎湖仓一体分析服务 LAS 是面向湖仓一体架构的 Serverless 数据处理分析服务,提供一站式的海量数据存储计算和交互分析能力,完全兼容 Spark、Presto、Flink 生态,在字节跳动内部有着广泛的应用。本次演讲将介...
观点|SparkSQL在企业级数仓建设的优势
**惊帆** 来自 字节跳动数据平台EMR团队EMR 前言Apache Hive 经过多年的发展,目前基本已经成了业界构建超大规模数据仓库的事实标准和数据处理工具,Hive已经不单单是一个技... 通常工作在企业的DM层直接面向业务,处理业务需求。* Hive、Spark:更注重任务的稳定性,对网络,IO要求比较高,有着完善的中间临时文件落盘,节点任务失败的重试恢复,更加合适小时及以上的长时任务运行,工作在企业的的...
「火山引擎」数智平台 VeDI 数据中台产品双月刊 VOL.06
为企业数字化转型提供数据支撑。(**公众号后台回复数字“2”了解更多产品信息。** )**火山引擎** **云原生** **数据仓库** **ByteHouse**云原生数据仓库,为用户提供极速分析体验,能够支撑实时数据分析和海量数据离线分析。便捷的弹性扩缩容能力,极致分析性能和丰富的企业级特性,助力客户数字化转型。(**公众号后台回复数字“6”了解更多产品信息。** )**火山引擎** **湖仓一体分析服务 LAS**面向湖仓一体架构的 Serverle...
数仓进阶篇@记一次BigData-OLAP分析引擎演进思考过程 | 社区征文
面向列开源数据库,不同于一般的关系型数据库,HBase基于列的而不是基于行的模式。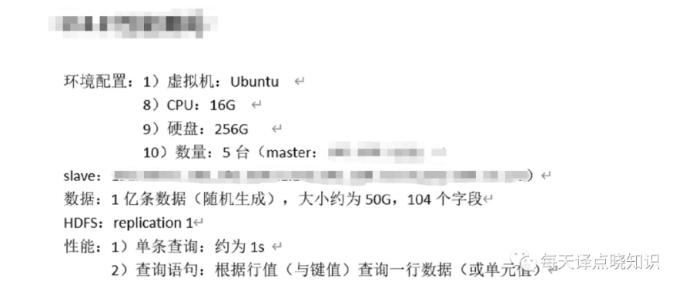... 兼顾数据仓库,具有实时,批处理,多并发等优点。**Java接入:** ![image.png]...
搞流式计算,大厂也没有什么神话
这不是一个挽狂澜于既倒的英雄故事,没有什么跌宕起伏的情节,也没有耀眼的鲜花与掌声。而是千千万万个普通开发者中的一小群人,一边在业务中被动接受成长,一边在开源中主动寻求突破的一段记录。**01 代码要写,... 已经完全就不用担心数据的实时性、业务分析的复杂性。至于 Flink 的未来,方勇已经有了设想。他希望能够集合社区的研发能力,一起完善整个 Flink 的计算生态,将 Flink 打造成统一流、批和 OLAP 的 Streaming W...
