使用过滤组对用户对象进行注释
 社区干货
社区干货
阿里巴巴的 Java 开发手册(黄山版)来了
如果不允许外部直接通过 new 来创建对象,那么构造方法必须是 private。- 工具类不允许有 public 或 default 构造方法。- 类非 static 成员变量并且与子类共享,必须是 protected。 - 类非 static 成员变量并且... 如果我们赋予这样一个逻辑表达式一个很好理解的名字(我觉得比注释更简洁易懂方便),则是一件令人赏心悦目的事情。我们来看一个对比的例子:```正例: // 伪代码如下 final boolean existed = (file.open(fileNa...
golang pprof
各个app一般都会有自己的用户画像,用户画像会包含年龄、性别、视频偏好等多项特征,从而更方便的为用户去推荐用户可能会感兴趣的内容。而计算机领域的profile指的就是进程的运行时特征,一般会包括CPU、内存、锁等多... 输出所有profile的注释 || disasm | 选择或过滤程序中的汇编调用并输出展示 || dot | 以dot格式输出图,do...
干货 | 提速 10 倍!源自字节跳动的新型云原生 Spark History Server正式发布
当用户访问 UI,会从列表中查找请求所需的任务,如果存在,就完整读取对应的 event log 文件,进行解析。解析的过程就是一个回放过程(replay)。Event log 文件中的每一行是一个序列化的 event,将它们逐行反序列化,并使... 前端会从`KVStore`查询所需的对象,实现页面的渲染。## 1.2 痛点- #### **存储空间开销大**Spark 的事件体系非常详细,导致 event log 记录的事件数量非常大,对于 UI 显示来说,大部分 event 是无用的。并且 ...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
> > > SparkSQL是Spark生态系统中非常重要的组件。面向企业级服务时,SparkSQL存在易用性较差的问题,导致> 难满足日常的业务开发需求。> **本文将详细解读,如何通过构建SparkSQL服务器实现使用效率提升和使用门... //用户与是否需要spark-submit的关联关系均在这里实现。 //同时需要生成THandleIdentifier对象,并且和用户身份进行关联,后续其他方法调用均需要使用这个对象关联出用户的信息。 ...
 特惠活动
特惠活动
 使用过滤组对用户对象进行注释-优选内容
使用过滤组对用户对象进行注释-优选内容
 使用过滤组对用户对象进行注释-相关内容
使用过滤组对用户对象进行注释-相关内容
SaaS-发版日志(2024年前)
功能价值: 针对多触点/多应用的客户,在Finder目前单应用层级只能看到单端的数据。升级后可在单一项目中接入多个应用,实现多应用之间的汇总统计,统一用户ID标识和埋点方案,获得全局视角的数据分析和管理体验。(注:功能仅面向云原生版本,且默认关闭,如需要可联系管理员修改配置开启)。功能详细说明&配图: 分析工具:分析模式从应用粒度切换为项目+主体粒度,同项目同主体下的多个应用可以联合进行分析,同时,支持在筛选器中切换过滤应...
新功能发布记录
2024-05-14 组件页面支持快捷查看组件底层资源状态 安装组件后,支持一键查看组件对应的底层资源对象列表,便于用户了解组件及其对应的资源对象列表之间的关系与运行状态。 华北 2 (北京) 2024-05-13 安装组件 华南... 支持根据调度状态和 节点 IP 信息过滤搜索。方便用户查询和筛选节点,提升了用户体验。 华北 2 (北京) 2024-05-13 无 华南 1 (广州) 2024-05-13 华东 2 (上海) 2024-05-14 抢占式实例类型的节点池底层使用弹性伸缩 ...
SaaS-发版日志(2024年前)
功能价值: 针对多触点/多应用的客户,在Finder目前单应用层级只能看到单端的数据。升级后可在单一项目中接入多个应用,实现多应用之间的汇总统计,统一用户ID标识和埋点方案,获得全局视角的数据分析和管理体验。(注:功能仅面向云原生版本,且默认关闭,如需要可联系管理员修改配置开启)。功能详细说明&配图: 分析工具:分析模式从应用粒度切换为项目+主体粒度,同项目同主体下的多个应用可以联合进行分析,同时,支持在筛选器中切换过滤应...
轻量级 Kubernetes 多租户方案的探索与实践
也就是说它的用户体验是有损的。其次,Cluster 或 Control plane 的隔离方案引入了过多的额外开销,比如每个租户需要建立独立的控制面组件,这样就降低了资源利用率;同时大量租户集群的建立,也会带来运维方面的负担... 不同租户之间的请求被映射到了后端集群的不同 Namespace 或者不同的 Cluster scope 的对象上,租户之间相互不干扰。 - 同时它又能够提供比较完整的 Kubernetes API,租户既能使用 Namespace 级别的资源,又能使...
干货 | 在字节跳动,一个更好的企业级SparkSQL Server这么做
这个作业需要和用户进行绑定,而不是随着Spark的组件启动进行绑定,也就是作业的提交,以及接收哪个用户的请求,均来自于用户的行为触发。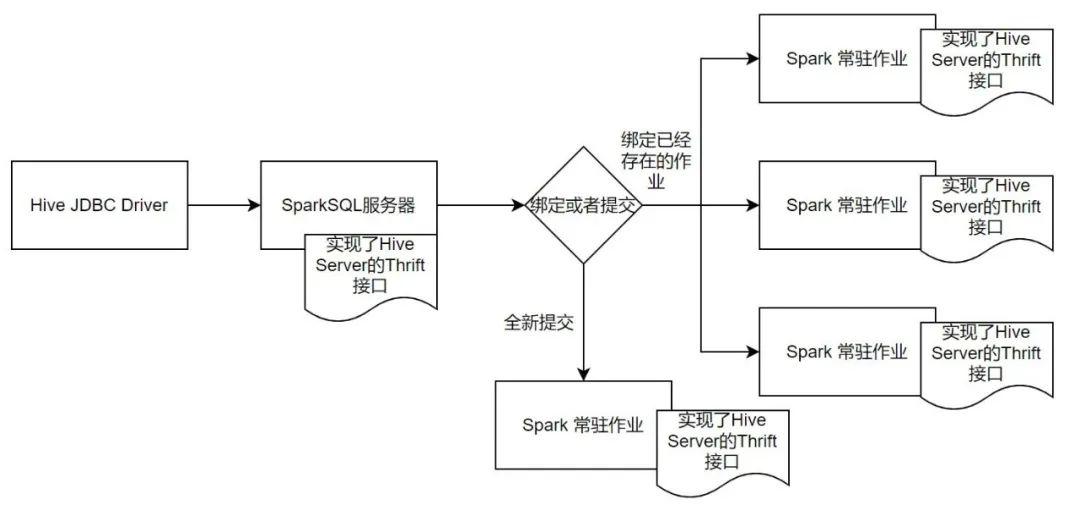有了这样几个大的方向后,便可以开始开发这个SparkSQL服务器了,首先需要实现TCLIService.Iface下的所有接口,下面用代码+注释的方式来讲述这些Thrift接口的含义,...
云原生环境下的日志采集、存储、分析实践
给我们的实际使用带来了很多不便。### 自建日志采集系统的困境与挑战云原生场景下日志种类多、数量多、动态非永久,开源系统在采集云原生日志时面临诸多困难,主要包括以下问题:一、采集难- 配置复杂:系统规模越来越大,节点数越来越多,每个节点的配置都不一样,手工配置很容易出错,系统的变更变得非常困难。- 需求不满足:开源系统无法完全满足实际场景的用户需求,例如不具备多行日志采集、完整正则匹配、过滤、时间解析等功...
火山引擎云存储选型指南 x 自动驾驶场景最佳实践
在大部分业务场景中做云存储大类的选型是相对容易的,比如要为云服务器配置系统盘或数据盘会使用块存储,存放视频、图片、游戏安装包等文件优选对象存储,但在某些业务场景(AI、HPC、大数据等)用户往往面临多样化的选择,需要综合考虑协议兼容性、功能、性能、易用性、扩展性等因素。本文将为您提供一个选型指南,如果您有计划将业务应用部署或迁移到火山引擎,可以参考文章内容选择最合适的云存储产品或者产品组合,为上层业务打造坚...
数据结构
*Test**** AccountProgressItem任务中用户迁移进度。被以下接口引用: TaskProgress 参数 类型 描述 示例值 Account String 账号名称。 test**** StartTime Integer 用户迁移的开始时间,毫秒时间戳。 0 FinishTime... RegionSetting FullExtraCondition全量过滤信息。被以下结构体引用: FullTransmissionSettings 参数 类型 是否必选 描述 示例值 Db String 否 需要过滤的数据库名称。 TestName Table String 否 需要过滤的表格名...
同步至火山引擎版 ElasticSearch
已创建云搜索服务实例和设置默认用户名 admin 的密码。详细信息,请参见创建 ElasticSearch 实例。 源端的数据库实例的接入方式选择的是公网自建时,且数据库实例开启了访问限制,那么在创建数据库传输任务前,您需要将 DTS 服务器 IP 地址添加至数据库实例的白名单或安全组中。DTS 服务器 IP 地址是(221.194.189.0/27,157.148.90.32/27,180.184.132.64/27,61.129.54.64/27,220.196.172.32/27,117.135.143.32/27,220.196.168.32/2...
