火山方舟
火山方舟






- 文档首页
 火山方舟下线文档归档SDK 参考高代码智能体 SDK智能体 SDK 使用说明
火山方舟下线文档归档SDK 参考高代码智能体 SDK智能体 SDK 使用说明

注意
以下功能是Beta版本, 如遇到问题, 请联系 PDSA, 谢谢合作;
下载tos命令行工具
下载tosutil
- linux环境为例:
wget https://tos-tools.tos-cn-beijing.volces.com/linux/tosutil && chmod a+x tosutil
配置tosutil
- 通过aksk完成命令行工具的初始化配置
tosutil config -i {AK} -k {SK} -e tos-cn-beijing.volces.com -re cn-beijing
查看sdk版本号
- 查看最新版本sdk
tosutil ls tos://ark-sdk-cn-beijing/python_sdk
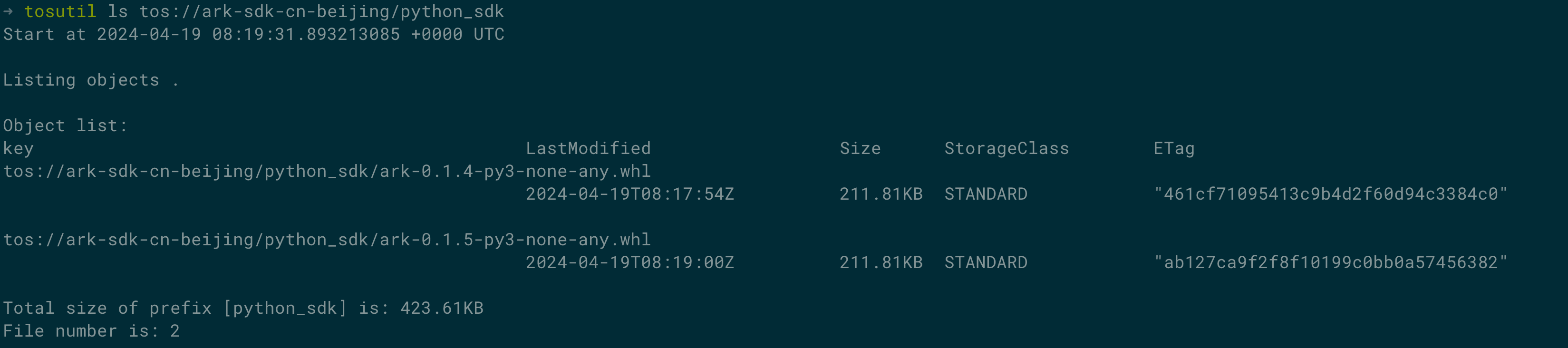
下载sdk
- 下载whl包到本地
tosutil cp tos://ark-sdk-cn-beijing/python_sdk/ark-{version}-py3-none-any.whl ./ark-{version}-py3-none-any.whl
下载后pip install
pip install ark-{version}-py3-none-any.whl
鉴权方式:SDK鉴权
联网检索相关
SearchIntention 类
识别用户 query 是否需要联网检索
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
__init__ |
注:
|
| 初始化 SearchIntention 类的实例 |
run | / |
注:
| 执行意图识别 |
联网检索意图识别示例
@task() def intention_check(request: MaasChatRequest) -> Tuple[bool, MaasChatResponse]: """ 检查用户的意图 参数: request (MaasChatRequest): 包含用户请求的信息 返回: Tuple[bool, MaasChatResponse]: 一个元组,第一个元素表示用户是否需要进行搜索,第二个元素是搜索结果的响应 """ try: # 创建一个 SearchIntention 实例来检查用户的意图 intention_check = SearchIntention( endpoint_id="", options={ "keywords": request.messages, "result_mapping": {"需要": True, "不需要": False}, }, parameters={"temperature": 1, "top_k": 1, "top_p": 0.7}, messages=format_maas_prompts( BrowsingIntentionChatPromptTemplate(), request.messages ), ) except ValueError as e: # 如果发生值错误,抛出一个 InvalidParameter 异常 raise InvalidParameter(str(e)) except TypeError as e: # 如果发生类型错误,抛出一个 InvalidParameter 异常 raise InvalidParameter(str(e)) # 运行意图检查 intention_resp = intention_check.run() # 如果意图检查的结果是不需要,返回 False 和意图检查的响应 if ( not intention_resp.choices or len(intention_resp.choices) == 0 or intention_resp.choices[0].message.content == "不需要" ): return False, intention_resp # 如果意图检查的结果是需要,返回 True 和意图检查的响应 else: return True, intention_resp
KeywordsGenerator 类
提取 query 的关键词
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
__init__ |
|
| 初始化 KeywordsGenerator 实例 |
run | / |
注:
| 执行关键词生成 |
生成关键词示例
@task() def generate_keywords(request: MaasChatRequest) -> List[str]: """ 生成关键词 参数: request (MaasChatRequest): 包含用户请求的信息 返回: List[str]: 关键词列表 """ keywords_generator = KeywordsGenerator( endpoint_id="", messages=request.messages ) location_info = None if ( request.tools and len(request.tools) > 0 and request.tools[0].options and "user_info" in request.tools[0].options ): try: user_info = json.loads( request.tools[0].options.get("user_info", "")) location_info = (user_info.get("city", ""), user_info.get("district", "")) except ValueError as e: raise InvalidParameter(f"Invalid user_info: {e}") try: keywords_resp = keywords_generator.run(location_info=location_info) except ValueError as e: raise InvalidParameter(str(e)) return keywords_generator.parse_output(keywords_resp.choices[0].message.content)
SearchSummary 类
生成检索结果总结
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
__init__ |
|
| 初始化 SearchSummary 类 |
run | / |
|
检索结果生成 summary 示例
def gen_summary(request: MaasChatRequest) -> Iterable[MaasChatResponse]: """ 生成搜索摘要的函数 参数: request (MaasChatRequest): 包含请求信息的对象 返回: Iterable[MaasChatResponse]: 生成的搜索摘要的响应 """ # 创建 SearchSummary 实例 search_summary = SearchSummary( endpoint_id="", # 配置选项 options={ "source_type": "text", "keywords": keywords, }, # 配置参数 parameters={"temperature": 0.7, "top_p": 0.9}, # 复制请求中的消息 messages=request.messages, # 复制请求中的额外信息 extra=request.extra, ) # 如果请求是流模式 if request.stream: # 对 search_summary.stream() 进行迭代,生成响应 for resp in search_summary.stream(): yield resp else: # 运行 search_summary 并生成响应 yield search_summary.run()
RAG 相关
VikingDB 类
一个基于 VikingDB 的知识库存储
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
get |
|
| 需要提供 sid |
初始化 VikingDB 示例
def get_viking_db(sid: str, kn_schema: VikingDBSchema) -> VikingDB: """ 从知识库中获取特定架构的知识库实例 参数: sid (str): 知识库的会话 ID kn_schema (VikingDBSchema): 知识库的架构 返回: VikingDB: 特定架构的知识库实例 异常: Exception: 当无法获取知识库时,抛出异常 """ try: kb = VikingDB.get(sid, kn_schema) return kb except Exception: error_string = traceback.format_exc() LOGGER.error("知识库获取失败, 错误信息: %s", error_string) return None LOGGER.info("知识库获取成功, id: %s", kb.sid)
VikingDBSchema 类
VikingDBSchema 向量定义
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
__init__ |
|
| 初始化 VikingDBSchema 类 |
初始化 VikingDBSchema 示例
kn_schema = VikingDBSchema( primary_key={ "name": "id", "type": "string", "default_val": "", }, vector={ "name": "encode_text", "type": "vector", "dim": 1024, "model": "mse-20231114152400-l7rb8", "embedding_type": "llm", }, scalars=[ { "name": "doc_id", "type": "string", "default_val": "", }, { "name": "file_name", "type": "string", "default_val": "", }, { "name": "text", "type": "text", "default_val": "", }, { "name": "chunk_id", "type": "int64", "default_val": -1, }, { "name": "chunk_type", "type": "string", "default_val": "raw_chunk" }, { "name": "chunk_len", "type": "int64", "default_val": 0, }, { "name": "full_text_len", "type": "int64", "default_val": 0, }, ], vector_text_len_limit=600, )
KnowledgeIntention 类
判断用户 query 是否需要进行知识库检索
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
__init__ |
|
| 知识意图类,继承自 RagIntention 类, 判断用户 query 是否需要进入知识库检索 |
arun | / |
| 执行知识意图识别 |
使用示例
async def knowledge_intention_check(request: MaasChatRequest) -> bool: """ 检查是否需要检索知识 参数: request (MaasChatRequest): 包含请求信息的对象 返回: bool: 如果需要检索知识,则为 True;否则为 False 异常: Exception: 当意图检查失败时,抛出异常 用法: >>> await knowledge_intention_check(request) """ try: rag_intention = KnowledgeIntention( endpoint_id="mse-20240219180336-5dw6w", # pro-4K 1.2 parameters={"temperature": 0.3, "top_p": 0.3}, messages=request.messages, ) need_retrieve = await rag_intention.arun() except Exception as e: LOGGER.error("Intention Failed, fallback, exception %s", str(e)) need_retrieve = True return need_retrieve
QueryRewriteGenerator 类
query 改写类, 继承自 RewriteGenerator 类; 在从vdb中 retrieve 之前, 先将用户的 query 改写, 比如将"指示代词"替换成清晰的主语, 将历史聊天记录中和query相关的关键词放入query中等;
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
__init__ |
|
| 生成 query 改写类, 基于 prompt 进行 query 改写 |
使用示例
async def query_rewrite(request: MaasChatRequest) -> str: """ 改写query的异步函数 参数: request (MaasChatRequest): 包含请求信息的对象 返回: str: 重写后的查询语句 异常: ValueError: 如果重写查询失败,将抛出此异常 用法: >>> await query_rewrite(request) """ template = QueryRewritePromptTemplate(template=CONDENSE_QUESTION_PROMPT_TEMPLATE) parser = RagRewriteMessageChunkOutputParser() query_rewrite_generator = QueryRewriteGenerator( endpoint_id="mse-20240219180336-5dw6w", # pro-4K 1.2 parameters={"temperature": 0.3, "top_p": 0.3}, messages=request.messages, template=template, output_parser=parser, ) try: rewrited_query = await query_rewrite_generator.arun() except ValueError as e: LOGGER.error("Query Rewrite Failed, fallback, exception %s", str(e)) rewrited_query = request.messages[-1].content return rewrited_query
VikingDBRetriever 类
从 VikingDB 召回检索
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
__init__ |
|
| VikingDBRetriever 类,继承自 BaseRetriever 和 ABC 类, 用于从 VikingDB 中检索数据 |
retrieve |
|
| 从 vikingDB 中异步检索数据 |
chunk_diffusion |
|
| 异步执行块扩散查询 |
使用示例
async def retrieve_knowledge( query: str, schema: VikingDBSchema, kb: VikingDB, cnt=3 ) -> List[str]: """ 异步检索知识库中的知识 参数: query (str): 查询语句 schema (VikingDBSchema): 知识库的架构 kb (VikingDB): 知识库实例 cnt (int, optional): 每个查询的检索数量. Defaults to 3. 返回: List[str]: 包含检索到的知识的字符串列表 异常: ValueError: 如果检索知识失败,将抛出此异常 """ retriever = VikingDBRetriever(schema, kb) # 直接召回 Top K dsl_filter = {"op": "must", "field": "chunk_type", "conds": ["raw_chunk"]} topk_chunks = await retriever.retrieve( query=query, retrieve_count=cnt, dsl_filter=dsl_filter ) dup_ids = set() dedup_chunks = [] for chunk in topk_chunks: dup_id = "#".join( [str(chunk.scalars["doc_id"]), str(chunk.scalars["chunk_id"])] ) if dup_id in dup_ids: continue dup_ids.add(dup_id) dedup_chunks.append(chunk) # 对 chunk 做上下文 diffusion async def chunk_diffusion(origin_chunk: KnowledgeChunk) -> KnowledgeChunk: text_tuple = [] diffusion_chunks = await retriever.chunk_diffusion( query=query, chunk=origin_chunk, forward_diffusion=1, backward_diffusion=1 ) for chunk in diffusion_chunks: text = chunk.scalars["text"] chunk_id = chunk.scalars["chunk_id"] text_tuple.append((text, chunk_id)) text_tuple.sort(key=lambda x: x[1]) merged_text = "".join([t[0] for t in text_tuple]) # inplace update origin_chunk.scalars.update({"text": merged_text}) return origin_chunk tasks = [chunk_diffusion(chunk) for chunk in dedup_chunks] dedup_chunks_diffusion = await asyncio.gather(*tasks) # Format Reference refs = [] for chunk in dedup_chunks_diffusion: text = chunk.scalars["text"] file_name = chunk.scalars["file_name"] chunk_id = chunk.scalars["chunk_id"] refs.append(f"文件名:{file_name}\n片段编号:{chunk_id}\n正文:\n{text}\n") return refs
RagSummary 类
Rag 检索后, 执行 summary 摘要生成
| 方法名 | 入参 | 出参 | 说明 |
|---|---|---|---|
__init__ |
|
| 用于生成文本摘要的语言模型, 继承自 BaseChatLanguageModel 类 |
示例代码
async def gen_summary(request: MaasChatRequest, reference: str, query: str) -> AsyncIterable[MaasChatResponse]: """ 异步生成摘要 参数: request (MaasChatRequest): 包含请求信息的对象 reference (str): 引用的文本 query (str): 要生成摘要的问题 返回: AsyncIterable[MaasChatResponse]: 生成的摘要的异步迭代器 用法: >>> async for resp in gen_summary(request, reference, query): >>> yield resp """ async for resp in summary_generation( request, reference=reference, question=query ): yield resp