客户数据平台(私有化)
客户数据平台(私有化)






- 文档首页
 客户数据平台(私有化)用户指南数据集成与整合可视化建模创建任务实时任务
客户数据平台(私有化)用户指南数据集成与整合可视化建模创建任务实时任务

任务创建,是指可视化建模任务的创建环节,通常包含新建任务、数据连接等步骤。可视化建模任务支持抽取数据源中的数据,通过拖拽形式添加数据处理节点,将处理完成的数据输出到目标源中。
说明
- 任务类型:实时任务、离线任务(任务创建后不可切换任务类型)
- 实时任务,指的是任务跟随实时更新的数据源可被实时执行,输出为实时更新的数据。实时任务支持输入的数据源为:Kafka、Pulsar;
- 离线任务,指的是任务跟随离线更新的数据源可被设置为手动和周期执行,输出为定期更新的数据或模型文件。离线任务支持输入的数据源为:Hive, MySQL, ClickHouse, Kafka, HttpAPI, 飞书, CSV/Excel, Oracle, Impala, PostgreSQL, Hbase, SQLServer, MaxCompute, ADB, MongoDB, Hana, Teradata, Db2, Vertica, GreenPlum等20余种主流的数据源;
本文将结合产品实操界面介绍 实时任务 的创建步骤。
- 用户需具备 项目编辑 权限或者 可视化建模模块的新建任务 权限,才能使用该功能。
- 可视化建模中部分功能为 付费能力,如有需要,请联系您的商务经理
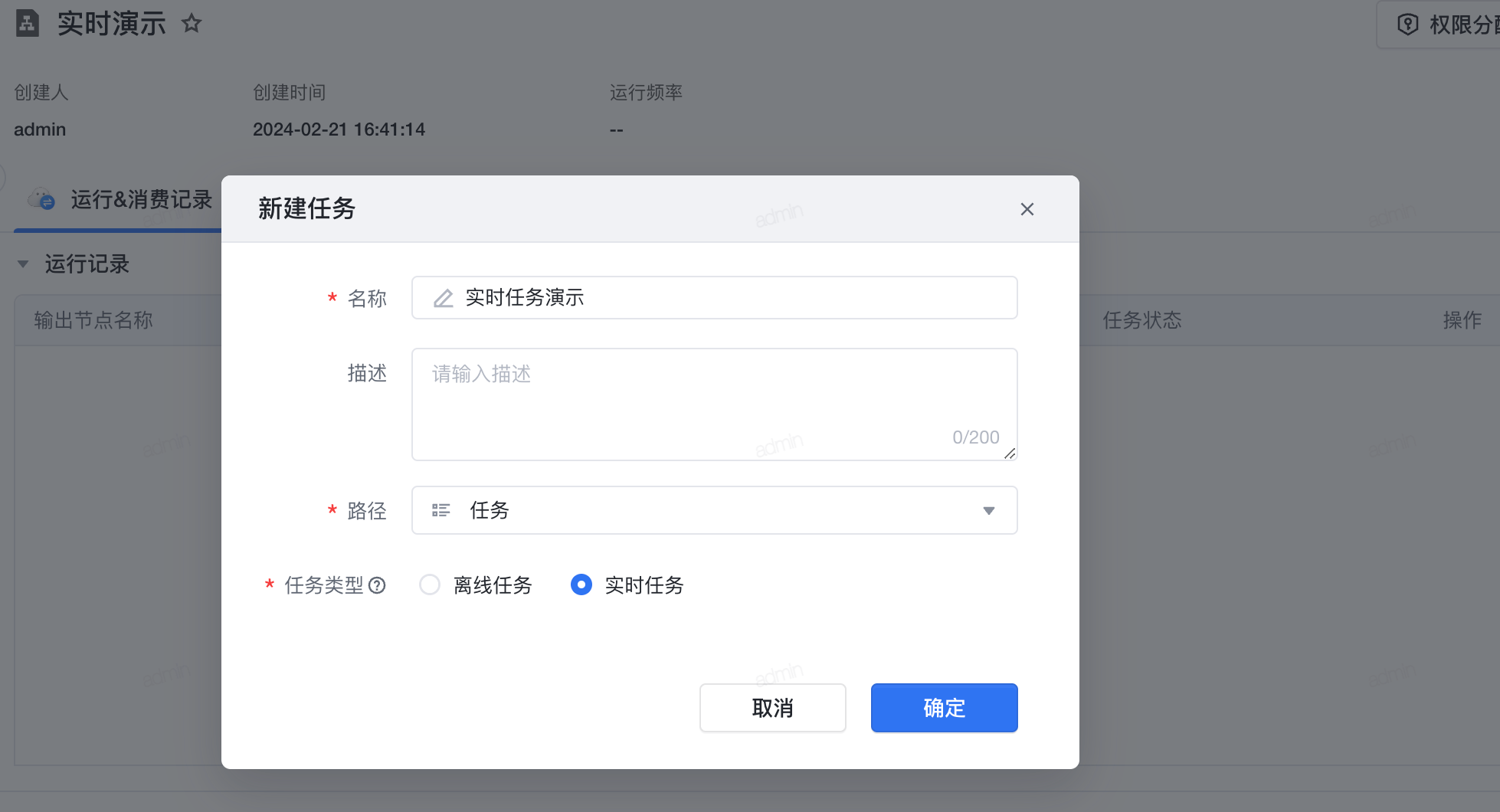
3.1 新建任务
- 点击 数据管理>可视化建模 。
- 点击左上角 新建任务 。
- 选择 路径 ,将当前任务存放在左侧某个可视化建模任务文件夹下。
- 选择创建 实时任务 。
3.2 数据连接
新建数据连接。 新建任务页面,点击左上方的加号,添加数据连接;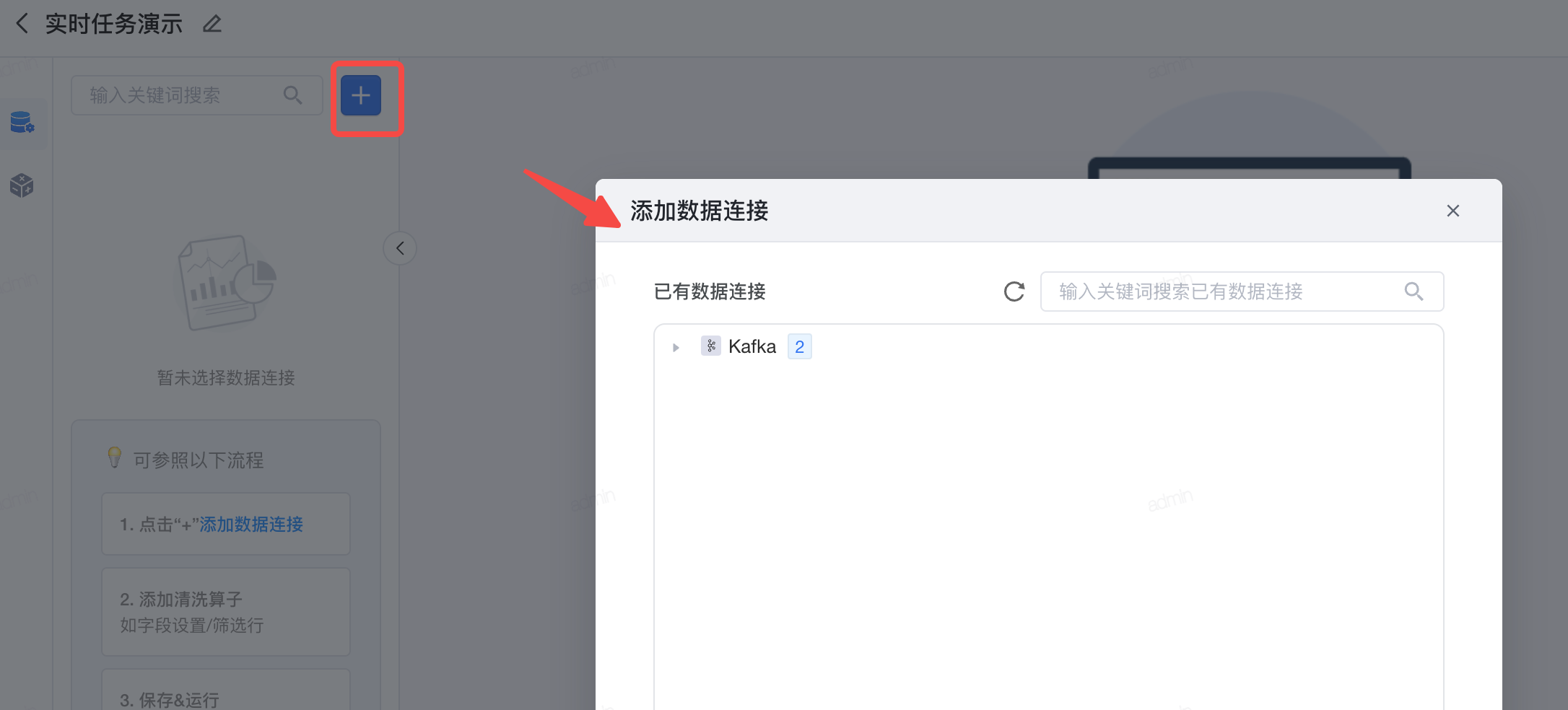
注意
- 实时任务仅支持 Kafka,默认不开启,如需使用请联系您的客户经理,并需完成以下前置操作:
- SaaS 环境:购买火山引擎 Kafka,并在数据连接对接好该火山引擎Kafka数据源
- 私有化部署:拥有自己的开源Kafka、Pulsar,并在数据连接对接好该Kafka数据源
移除数据连接。 可视化建模任务创建页面的数据连接列表中,点击具体某个数据连接右侧的删除按钮,即可移除数据连接。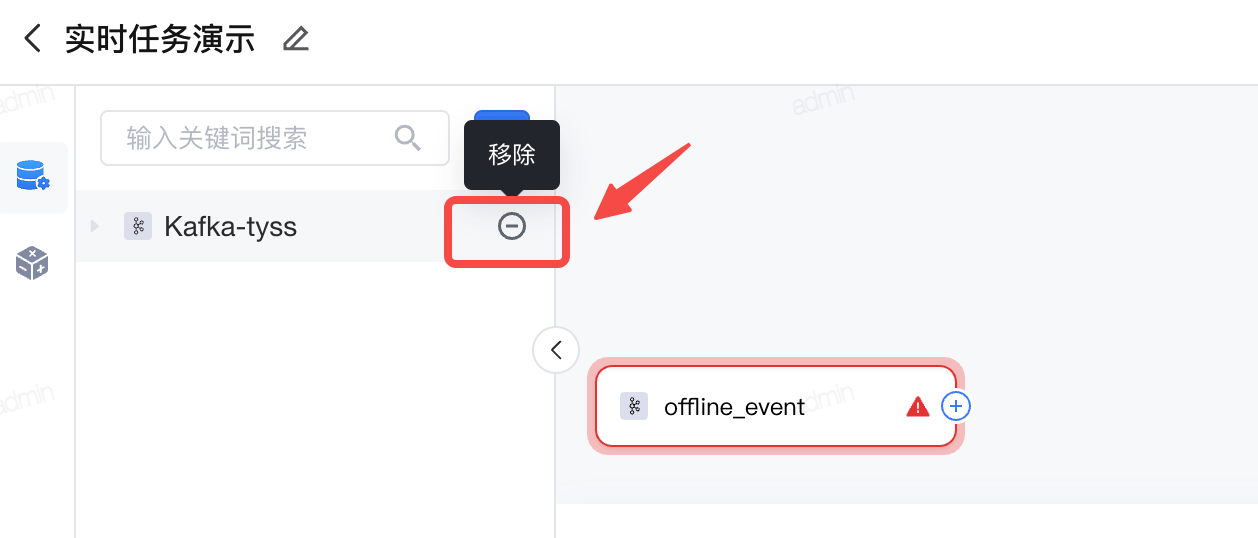
3.3 处理节点
通过点击节点右侧加号添加并配置处理节点,拖拽上一节点右侧加号和下一节点左侧原点连线,配置节点流转关系。点击“应用”后可展开处理后的数据结果预览。
如下图所示,点击输入数据算子块的输出+号,展开操作节点:输出、数据清洗,点击其中一类,则可看到可以使用的算子。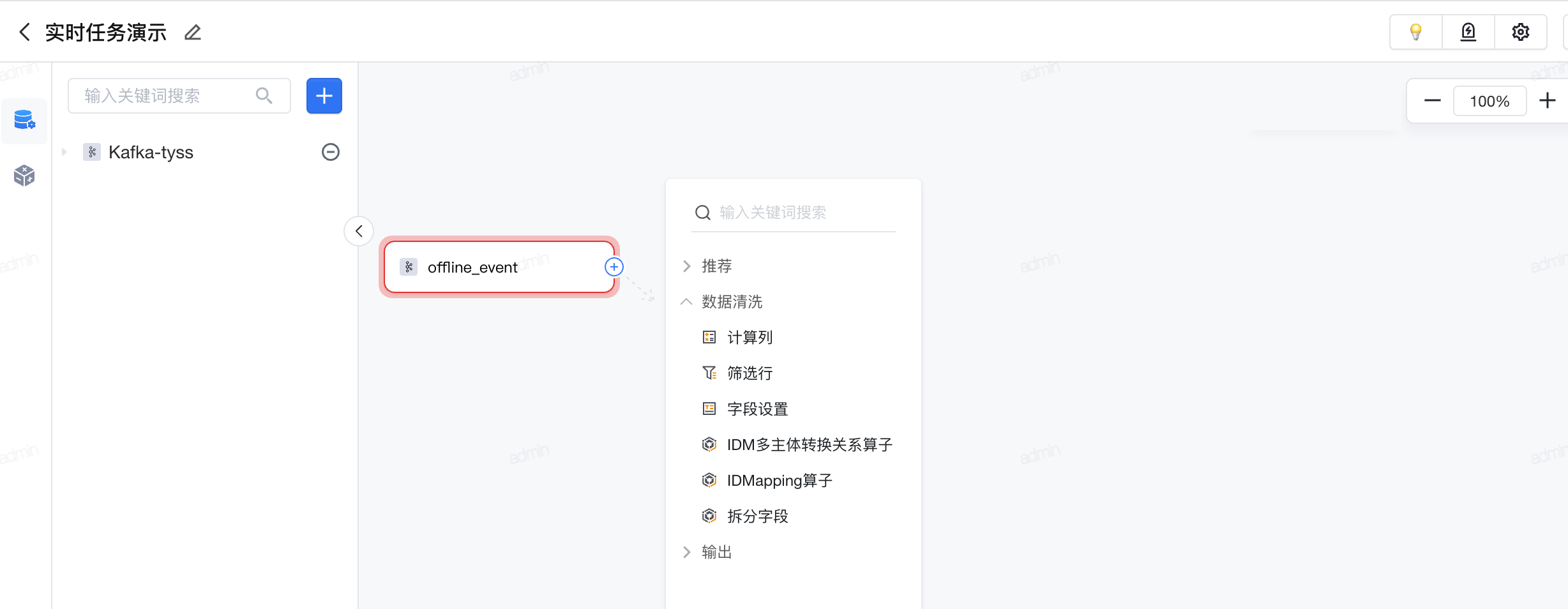
常用算子说明
- 输出: 表示画布流程执行完数据输出到指定位置并配置任务执行逻辑,包含输出实时数据集、输出实时标签、分流输出。
- 数据清洗: 支持计算列、筛选行、字段设置、IDM多主体转换关系算子、ID Mapping算子、拆分字段。
3.4 节点执行
配置中可以选中某节点并运行节点,进行运行检查。需注意的是,当上游节点更改后,必须重新执行上游节点后才能执行当前及下游节点。
- 执行该节点:运行当前节点,需要上游节点均执行完成
- 执行到此处:依次运行上游未执行的节点和当前节点
- 从此处开始执行:依次运行当前节点和后续节点,需要上游节点均执行完成,一般在当前节点更改后使用
3.5 输出数据集
添加输出节点,选择输出到已有数据集或新建数据集。
已支持输出数据集:以ClickHouse存储的数据集
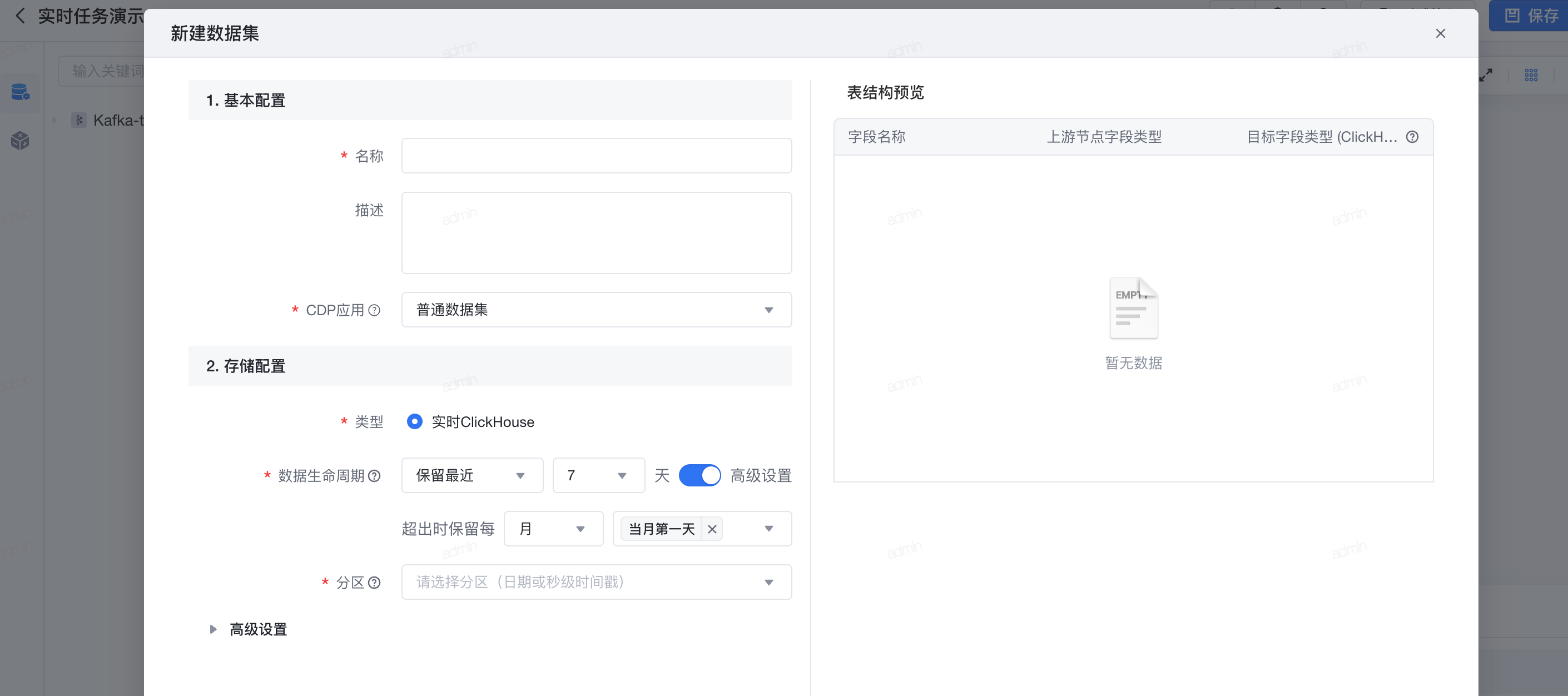
支持配置数据生命周期, 即抽取至系统存储中数据的有效保留天数,非分区表根据数据更新时间保留数据,日期分区则根据分区日期保留数据,生命周期外的数据每天0点会自动清除。
数据生命周期的高级设置: 即在保留天数的基础上,可以对历史数据选择性的保留。
- 示例1:如选择最近7天,则保留最近7天的数据,超出7天的数据将根据数据更新时间定时滑动清空
- 示例2:(高级功能):如选择最近7天 + 超出时保留每月最后一天的数据,则除了最近7天数据外,历史数据里每月的最后一天数据也会保留下来
注意
季度为自然季度(如1-3月为一季度)
建议:
保留周期越久占用的系统存储资源越多,请根据需要选择合理的生命周期范围
完成配置后点击右上角 保存 按钮即可。
3.6 实时告警能力
可视化建模实时任务支持对消费端、任务输出端进行任务监控。
- 消费端监控规则
(1)消费延迟监控:消费延迟是指Kafka的消费者(Consumer)读取消息的进度落后于生产者(Producer)生产消息进度,过高的消费延迟可能会导致数据处理的延时,影响实时性,并可能导致内存溢出或其他资源问题,因此及时监控和管理消费延迟是保证Kafka稳定运作的重要环节。
延迟条数= 生产者的偏移量-消费者的偏移量 。可配置告警规则“当连续XX分钟,延迟数大于XX进行告警”。
(2)写入断流监控:写入断流指的是上游kafka在一段时间内,无数据写入,是对上游数据产出稳定性的监控。可配置告警规则“一个时间区间内,kafka topic连续XX分钟,没有数据写入时告警”
(3)写入上涨监控:写入上涨指的是上游数据输入不稳定,在某个时间段,QPS突然升高,上游数据质量可能出现问题。
可配置的告警规则“是数据连续在XX分钟内,QPS一直大于某个值时进行告警”。
- 输出端监控规则
(1)任务运行状态监控:当任务运行中变为暂停时发送告警(不包含人工手动停止任务运行的情况)。
(2)脏数据数量监控:脏数据指的是一段时间内因不符合数据规则未成功写入的数据(数据丢失),目前丢失的环节包含(1)输入节点的推送数据与topic表结构有差异;(2)处理阶段:OneID未关联上;
可配置的告警规则:“连续XX分钟,脏数据大于多少条时进行告警”。