DataLeap私有化V2.1.2
DataLeap私有化V2.1.2



文档指南

请输入


- 文档首页
 DataLeap私有化V2.1.23 数据开发3.1 批开发3.1.6 Python任务
DataLeap私有化V2.1.23 数据开发3.1 批开发3.1.6 Python任务

3.1.6 Python任务
使用场景
- 数据分析:数据分析师使用python进行数据分析,图表制作;
在大量数据的基础上,对数据进行清洗、去重、规格化和针对性的分析。 - 机器学习:ML/DL 工程师使用python任务进行模型训练或者推理;
Python在人工智能大范畴领域内的机器学习、神经网络、深度学习等方面都是主流的编程语言,得到广泛的支持和应用。 - 在数据分析处理领域,python任务目前适用于处理的数据量较少且数据处理逻辑复杂的场景,不属于此类的请优先使用 hive 任务和 spark 任务。
注意事项
- 默认 python 版本为3.7,其他版本需手动选择;
- 使用 python2.7 时,请在代码顶行加上 # -*- coding: utf-8 -*-以表示文件编码;
- 当需要依赖非 python 自带的包时,请在下方配置依赖包,python 自带无须设置(若需预置python lib,请联系系统运维管理员进行操作);
- 使用 python2.7 时,依赖包务必指定版本,python3.7 建议指定版本,以保障每次运行环境的一致性;
- 请尽量不要配置代码中没有依赖的包;
- 设置系统环境变量时,避免直接覆盖系统环境变量,请按照追加方式指定,例如PATH=$PATH:/home/xxx/apps/bin/;
任务配置
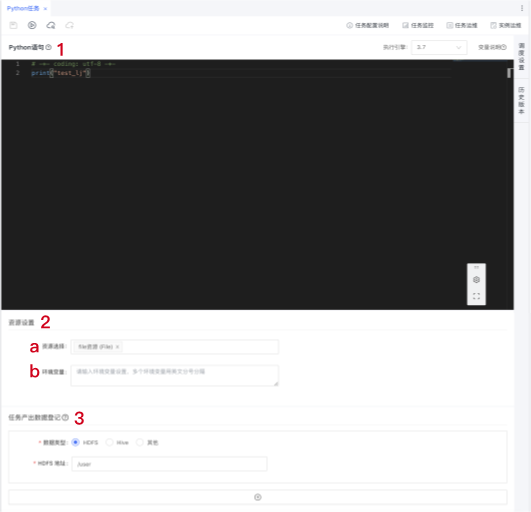
- python语句:python数据处理逻辑
- 资源设置:可根据实际需要添加
a) 资源选择:支持资源类型有:zip、jar、file
b) 环境变量:支持自定义环境变量,多个环境变量用英文分号分隔。 - 任务产出数据登记
详见“任务产出数据登记”
最近更新时间:2022.09.05 11:25:30
这个页面对您有帮助吗?
有用
有用
无用
无用