全站加速
全站加速






- 文档首页
 全站加速AI 加速网关控制台操作指南 创建 AI 加速网关实例
全站加速AI 加速网关控制台操作指南 创建 AI 加速网关实例

AI 加速网关实例是统一管理和加速大模型 API 调用的入口。本文介绍如何在全站加速(DCDN)控制台创建 AI 加速网关实例。
使用场景
在以下场景中,您可以创建并使用 AI 加速网关实例:
- 统一多模型入口:应用需要调用不同供应商(如火山方舟、第三方平台、自部署模型)的多个大模型时,通过实例提供统一的 API 调用地址。
- 简化客户端开发:客户端使用统一的 OpenAI 协议与所有后端模型交互,无需单独编写适配逻辑。
- 提升稳定性:通过负载均衡或主备容灾策略分配流量,保障服务高可用。
- 降低成本与延迟:通过启用缓存,直接从边缘节点返回相似请求的结果,减少对后端模型的调用,降低成本和响应时间。
背景信息
创建 AI 加速网关实例时需要配置您的后端模型。实例创建成功后,您可以通过以下两种方式调用后端模型:
- OpenAI 兼容协议:使用网关生成的 API Key,以统一的 OpenAI 协议格式发送请求和接收响应。
- 该方式支持网关的全部能力,包括请求加速、模型路由(负载均衡 / 主备容灾)、语义缓存和限速等。
- 适用于希望统一管理多厂商调用协议的场景。
- 协议透传:使用模型厂商自身的 API Key 和原生协议。网关原样转发请求和响应,不做协议转换。
- 您只需将厂商域名(BaseUrl)替换为网关实例的 BaseUrl(包含加速域名),即可获得请求加速能力(不支持模型路由、语义缓存和限速等其他能力)。
- 适用于需要保留厂商原生接口行为的场景。
一个加速网关实例(对应一个 BaseUrl —— 含加速域名)可同时关联多种调用类型 / 用途(如文本生成、图像生成、语音合成等)的模型,网关会根据请求路径自动路由到对应类型的模型,无需为不同模型类型创建多个实例。
使用限制
- 网关实例支持关联的模型包括火山方舟模型、第三方模型服务商模型(国内、海外)、自部署模型。具体模型来源请参见 功能特性。
说明
- 火山方舟模型、第三方模型服务商模型支持以 OpenAI 兼容协议和协议透传方式调用。
- 自部署模型仅支持以 OpenAI 兼容协议方式调用。
- 每个实例最多允许关联 50 个模型。
前提条件
创建实例前,请确保:
- 已开通全站加速服务。
- 已准备好要接入的模型。
准备模型配置所需信息:- 火山方舟模型:在 火山方舟控制台 创建 API Key,并获取模型的推理接入点(Endpoint)。
- 第三方模型服务商模型(国内、海外):获取对应平台的 API Key。详情请参见从模型提供商平台获取模型调用密钥。
- 自部署模型:准备服务的 API Key 和地址(BaseUrl)。
注意
自部署文本生成模型必须兼容 OpenAI Chat Completions API 格式;自部署语音识别和语音合成模型必须满足 AI 加速网关的协议规范。更多信息,请参见自部署模型接入 AI 加速网关接口协议规范。
操作步骤
- 登录 全站加速控制台。
- 在左侧导航栏,选择 AI 加速网关 > 实例管理。
- 单击 新增实例。
- 在 创建实例 页面完成以下配置。参数详情请参见 配置说明。
- 基础配置:填写实例名称并选择类型。
- 模型配置:选择路由策略,添加并配置至少一个模型。
- 高级配置:设置加速区域、缓存、限流和预算管理策略。
- 单击 确定。
创建成功后,页面自动返回 实例管理 列表。单击实例名称进入 实例详情 页面。您可以在 请求方式 区域获取 BaseUrl、API Key,以及 Curl 和 Python 的调用示例。
说明
控制台默认展示 OpenAI 兼容协议的调用示例。如需查看协议透传的调用示例,请参见模型调用示例代码。
多模型选择
如果网关绑定了多个模型,选择不同模型会影响调用示例中的 model 字段。建议根据模型路由策略选择相应模型。
路由策略 | 模型选择 |
|---|---|
主备容灾 | 选择您最希望优先访问的模型名称。网关将按配置的主备顺序调度,主模型失败或超时后自动切换到备用模型。 说明 路由策略仅在同一调用类型(如文本生成、图像生成、语音识别等)的模型之间生效。不同调用类型的模型独立调度,不互相容灾或均衡。 |
负载均衡 | 选择任一模型,则 注意 要使负载均衡生效(网关按权重在同一调用类型模型之间分配请求), |
配置说明
实例创建页面的配置项说明如下。
配置分组 | 配置项 | 说明 |
|---|---|---|
基本信息 | 实例名称 | 实例的标识名称。 |
实例类型 | 指定实例用途。目前仅支持 MaaS API 加速,用于统一管理和加速大模型 API 调用。 | |
模型配置 | 模型路由策略 | 请求分发规则。可选项:
|
模型/智能体 | 单击 添加模型 接入后端模型。具体配置项因模型类型而异,请参见下方各模型类型的配置说明。最多支持添加 50 个。 | |
加速配置 | 加速区域 | 选择您的用户主要所在的地理区域,以便网关能够就近接入,优化网络延迟。可选项:中国大陆、全球、全球(除中国大陆)。 |
精品公网 | (仅当加速区域为中国大陆且实例配置了第三方模型服务商(海外)模型时出现)开启后,将通过精品公网通道加速第三方模型服务商(海外)模型(Anthropic、OpenAI、Google)的访问,降低跨境网络延迟,提升访问稳定性。精品公网将产生额外费用,详情请参见 AI 加速网关计费说明。 | |
加速域名 | 设置实例的公开访问地址前缀。完整的加速域名将作为客户端调用的
| |
HTTPS 配置 | (仅自定义加速域名时可见)开启后,网关使用 HTTPS 提供安全的加速服务。开启 HTTPS 时需选择证书。 | |
证书来源 | (仅开启 HTTPS 时)证书的来源方式。可选项: | |
服务授权 | (仅开启 HTTPS 时)AI 加速网关需要通过跨服务访问授权获取读写火山引擎证书中心的权限,以管理用于 HTTPS 的证书。授权状态显示为 已授权 表示授权已完成。如未授权,请按页面提示完成授权。 | |
证书名称(新上传证书) | (仅证书来源为新上传证书时)新上传证书的自定义名称,用于在证书中心中标识该证书。 | |
证书内容(新上传证书) | (仅证书来源为新上传证书时)PEM 格式的证书内容,需以 | |
私钥内容(新上传证书) | (仅证书来源为新上传证书时)PEM 格式的私钥内容。支持 RSA 和 ECC 等密钥算法:
请确保上传的私钥与证书匹配。 | |
选择证书(已有托管证书) | (仅证书来源为已有托管证书时)从下拉列表中选择已托管在火山引擎证书中心的证书。 | |
缓存配置 | 缓存启用状态 | 开启后,网关会缓存模型的成功响应。当后续收到相似的请求时,将直接从缓存中返回结果,提升性能并降低成本。 |
缓存时长 | (仅开启缓存时)缓存的有效时间。超过此时长,缓存将被视为过期并自动清除。可选项:1 分钟、5 分钟、30 分钟、1 小时、1 天、1 周。 | |
限流配置 | 限流配置 | 开启后,可设置请求速率限制,保护后端服务免受流量冲击。 |
HTTP 协议 | (仅开启限流时)限制每分钟的请求数(RPM)。 | |
WebSocket 协议 | (仅开启限流时)限制并发连接数。 | |
预算管理配置 | 预算管理 | 开启后,可为网关实例或模型供应商设置用量限额。当用量达到限额后,网关将按 模型路由策略 把请求重新分发到同一调用类型的其他模型,从而控制成本。 |
预算维度 | 限额的统计口径。可选项:
| |
用量管理 | 限额的计量方式。可选项:
| |
费用上限 | (仅 预算维度 为 加速网关实例 且 用量管理 为 费用开销 时)实例的费用总上限,单位为 RMB,最小值为 1。 | |
Tokens 用量上限 | (仅 预算维度 为 加速网关实例 且 用量管理 为 Tokens 用量 时)实例的 Tokens 用量总上限,单位为 Tokens,最小值为 100。 | |
模型预算 | 为单个模型设置预算。模型下拉项与实例已配置的模型联动,支持 添加模型预算 和 删除。表格列因 预算维度 和 用量管理 的组合而异:
说明 输入单价、输出单价为您填写的协商价或估算价,仅用于预算费用的测算口径,与 AI 加速网关的实际计费无关。 | |
统计周期 | 预算用量的统计与重置周期。可选项:每小时、每天、每周、每月。 |
超过预算后的路由方式
当某个模型(或供应商)的用量达到预算上限后,网关会将其在当前统计周期内剔除,并按实例已配置的 模型路由策略,将后续请求重新分发到 同一调用类型 的其他模型;统计周期重置后,被剔除的模型恢复参与路由。
- 负载均衡(加权轮询):达到上限的模型被剔除,其权重在剩余模型间按原始权重等比例重新分配。
例:模型 A 50% / 模型 B 25% / 模型 C 25%。当模型 A 超过预算上限后,剩余请求按模型 B 50% / 模型 C 50% 分发。 - 主备容灾:主模型达到上限后,请求 100% 切换到下一优先级的备用模型;备用模型再次达到上限时按相同顺序继续切换。
例:主模型 A 、备模型 B 。当模型 A 超过预算上限后,请求 100% 由模型 B 承接。
说明
- 路由策略仅在 同一调用类型(如文本生成、图像生成、语音识别等)的模型之间生效。
- 当同一调用类型的全部模型都达到预算上限时,请求将不再被路由分发。
火山方舟模型配置项
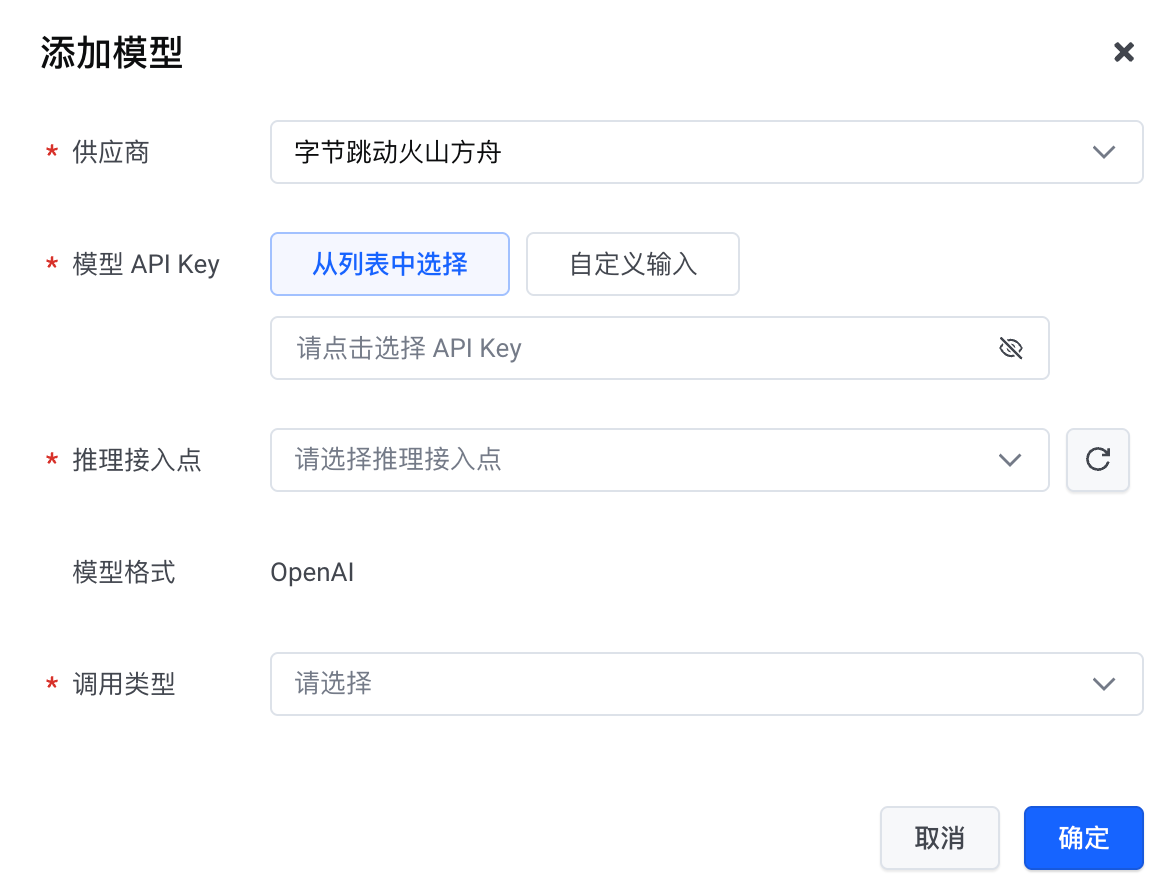
配置项 | 说明 |
|---|---|
供应商 | 选择 字节跳动火山方舟。 |
模型 API Key | 火山方舟模型的访问凭证。推荐选择 从列表中选择,自动加载已创建的 API Key;也支持 自定义输入。 说明 如果不传入,该模型仅支持通过协议透传方式调用(协议透传方式仅支持请求加速能力,不支持其他能力)。 |
推理接入点 | 模型在火山方舟的推理端点地址。 |
模型格式 | 模型通信协议,目前仅支持 OpenAI。 说明 此为 OpenAI 兼容协议模式下的通信协议限制。使用协议透传时,网关原样转发厂商协议。 |
调用类型 | 模型服务场景。可选项:文本生成、图像生成、语音识别、向量模型、语音合成。 |
第三方模型服务商配置项
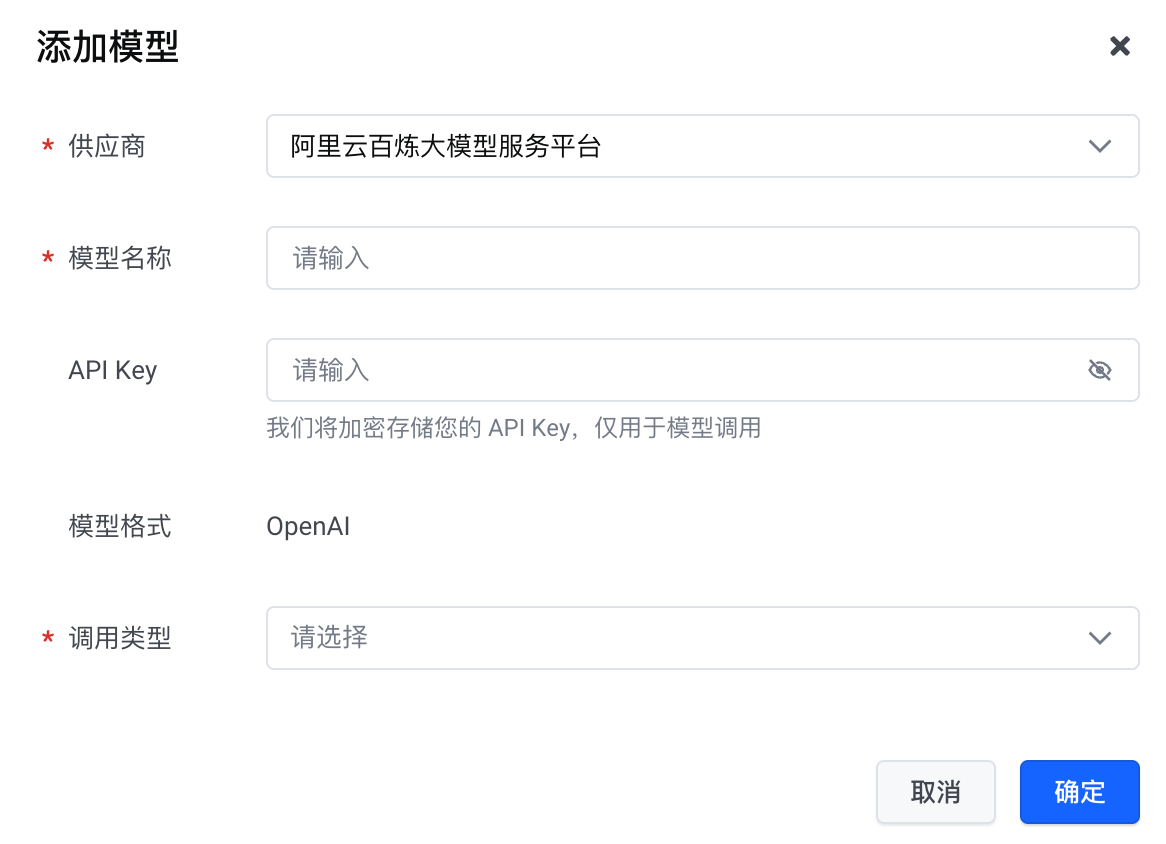
配置项 | 说明 |
|---|---|
供应商 | 选择您的模型服务提供商。支持的第三方模型服务商包括:
|
| 模型名称 | 在网关中显示的自定义名称。 |
API Key | 模型服务商平台提供的 API Key。 说明 如果不传入,该模型仅支持通过协议透传方式调用(协议透传方式仅支持请求加速能力,不支持其他能力)。 |
模型格式 | 模型通信协议,目前仅支持 OpenAI。 说明 此为 OpenAI 兼容协议模式下的通信协议限制。使用协议透传时,网关原样转发厂商协议。 |
调用类型 | 模型服务场景,目前仅支持 文本生成。 |
自部署模型配置项
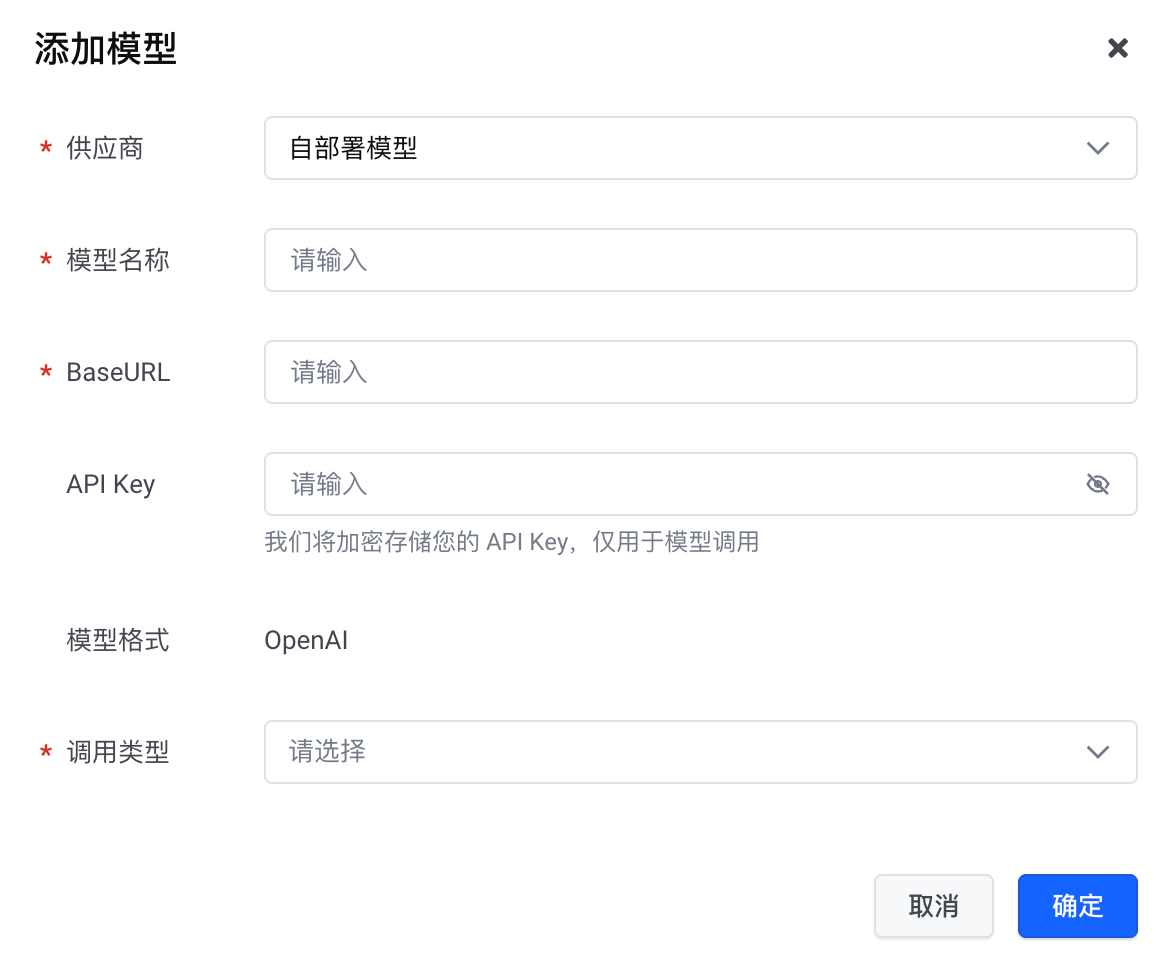
配置项 | 说明 |
|---|---|
供应商 | 选择 自部署模型。 |
| 模型名称 | 在网关中显示的自定义名称。 |
BaseURL | 自部署模型的服务地址。 |
API Key | 自部署模型的 API Key。 注意 自部署模型仅支持通过 OpenAI 兼容协议方式调用。您必须提供 API Key,否则无法调用。 |
模型格式 | 模型通信协议,目前仅支持 OpenAI。 |
调用类型 | 模型服务场景。可选项:文本生成、语音合成、语音识别。对于语音合成和语音识别模型,网关支持透传以下额外配置。 |
协议类型 | (仅语音合成)模型通信协议。可选项:HTTP、WebSocket。 |
采样率 | (仅语音合成)音频采样率(Hz),需输入正整数。 |
位深 | (仅语音合成)音频位深度,目前仅支持 16bit。 |
通道数 | (仅语音合成)音频通道数。可选项:1(单声道)、2(立体声)。 |
集成方式 | (仅 HTTP 语音合成)网关处理用户请求的方式:
|
结果输出方式 | (仅语音识别)识别结果返回方式:
|
是否支持 VAD | (仅语音识别)模型是否支持语音活动检测(Voice Activity Detection)。 |
相关操作
- 编辑实例
在 实例管理 页面,找到目标实例,在 操作 列单击 编辑。您也可以在 实例详情 页面单击右上角的 编辑。 - 删除实例
在 实例管理 页面,找到目标实例,在 操作 列单击 删除,并在确认框中单击 确定。删除后实例数据无法恢复。