工作区选择
最近更新时间:2024.01.31 20:55:02
首次发布时间:2023.06.06 10:27:33
在创建工作区前,您首先需要根据实际业务情况,估算指标数量并选择合适的工作区规格。本文将指导您如何估算规格并选择工作区。
选择数据存储天数
请您需要根据数据保存的时间需求,合理选择数据需要保存的时间段。
估算最大活跃时序数
活跃时序是指有多少时序正在被活跃地写入工作区。每个指标在每个监控对象上产生一个活跃时序。活跃时序是评估数据规模的最首要维度。详情请参见 基本概念。
建议您按照最大活跃时序上限评估和选择的工作区规格。您可以参照以下几个方案,来估算最大活跃时序数。
方案一:根据集群和业务规模进行估算
- 集群指标
当您使用火山引擎容器服务(VKE)或自建 Kubernetes 集群环境时,容器资源、虚机资源和原生 Kubernetes 资源相关指标的数据量可以根据集群规模大致估算。假设您采集的指标包括:node-exporter、kubelet、cadvisor 和 kube-state-metrics,即 Kubernetes 默认采集的所有数据面指标,估算公式如下:
nodeMax × 15,000 + podMax × 200 + podInc × 200
| 参数 | 说明 | 获取方式 |
|---|---|---|
nodeMax | 集群中的最大节点数 | 您可以使用命令 说明
|
podMax | 集群中的最大 Pod 数 | 您可以使用命令 说明
|
| podInc | 集群中每小时新增的最大 Pod 数,包含 重建 的情况 | 如果您的集群中存在 Pod 频繁创建和删除的情况,请估算每小时内新增的最大 Pod 数。包括:新建的 Pod 数 和 删除后重建的 Pod 数。 |
说明
上述估算公式不包含 控制面指标 和 自定义指标。
业务指标
业务指标指的是部署在集群中的业务暴露的指标。该指标完全与您的业务情况相关,包括:
- 业务 Pod 的数量。
- 每个 Pod 对外暴露的最大活跃时序数。
- 业务 Pod 的创建和删除情况。例如:业务 Pod 是否存在频繁删除和创建 Pod 的情况。
您需要根据上述情况合理评估业务指标的最大活跃时序数,并与集群指标的最大活跃时序数相加,即是您选择工作区时所需的最大活跃时序数。
方案二:从已有 Prometheus 迁入
在原生 Prometheus 中,采集侧会自动生成 scrape_samples_scraped(每次采集的总样本数)和 scrape_series_added(相较上次采集新增的时序数)。您可以在已有的 Pormetheus 系统中,使用如下 PromQL 语句,查询这些指标,并对最大活跃时序做出估算。
sum (scrape_samples_scraped{} offset 1h) + sum (sum_over_time(scrape_series_added{}[1h]))

说明
在其它监控系统中,对应指标名可能不完全一致,您可以根据指标的实际含义做相应替换。
方案三:试用标准版工作区
如果您确实无法正确估算出工作区的最大活跃时序数,可以采用试用工作区的方式,获取您环境中的指标规模。托管 Prometheus 为您提供了 vmp.standard.15d 规格的标准版工作区,该工作区的云服务基础指标为免费,非常适合您进行试用。详情请参见 计费方式。
试用标准版工作区的步骤如下:
- 登录 VMP 服务控制台。
- 在顶部导航栏,选择目标地域。
- 在左侧菜单栏中选择 工作区,进入工作区列表页面。
- 单击 创建工作区,选择创建并购买 vmp.standard.15d 规格的标准版工作区。

- 单击 立即创建,完成创建工作区。
- 将您的集群和业务接入创建好的工作区。详情请参见 容器服务接入。
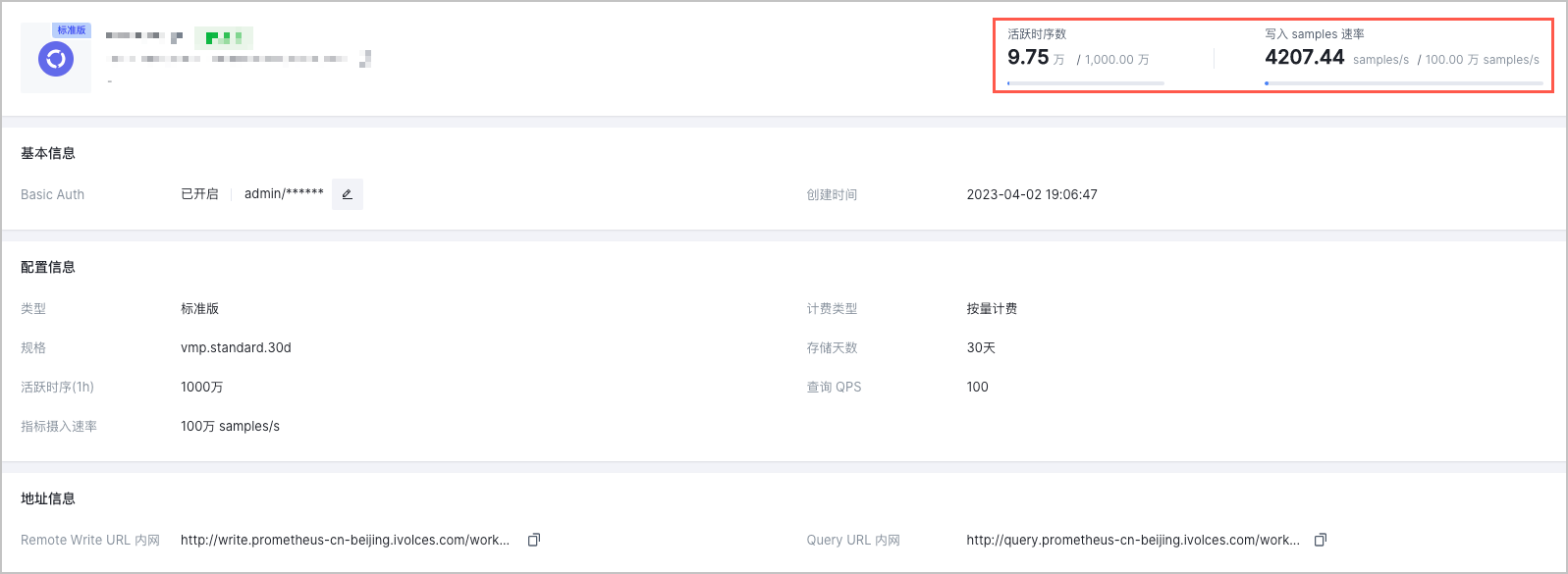
- 集群接入工作区后,您可以在工作区详情中查看到工作区的 最大活跃时序数 和 写入 samples 速率 指标。
- 在左侧菜单栏中选择 工作区,进入工作区列表页面。
- 单击目标工作区名称,进入工作区详情页面,查看工作区的详情信息。
- 根据您的试用情况,考虑是否更换为更高规格的工作区。
说明
由于工作区暂时不支持升降配,如果您在试用过程中发现配额不够,可以采取如下 2 个策略:
- 按合理的维度(例如:开发环境、生产环境)把用指标用量拆解到不同的工作区。
- 购买其他规格的工作区,并将流量切换到新的工作区。注意:切换工作区暂时无法实现旧数据的迁移。
估算其他配额用量(可选)
说明
使用 存储天数 和 最大活跃时序数 选择工作区规格,能够满足大部分使用场景。如果您觉得您的使用场景有所特殊,可以继续评估其他指标。
估算最大指标摄入速率
您可以使用如下公式,估算最大指标摄入速率。
time_series / scrape_interval
其中:
time_series:表示最大活跃时序数。scrape_interval:表示采集间隔,在 prometheus-agent 组件中,默认为 15 秒。
例如:如果您的最大活跃时序数是 1,000 万,采集间隔为 15 秒。则您的最大指标摄入速率为:1000 / 15 = 66.7 万 sample/s。
估算查询 QPS 与查询并发
您可以使用如下公式,估算查询 QPS。
1.5 × panels × persons
其中:
panels:表示最大单屏监控面板数量,即屏幕可同时显示多少面板。persons:表示最大同时使用面板人数。
说明
当您估算出查询 QPS 后,在绝大多数情况下,查询并发也是足够的。
评估综合费用成本
经过估算和筛选后,如果仍有多款工作区规格符合您的需求,可以进一步地综合费用成本进行选择,详情请参见 计费方式。
后续使用
后续随着业务量增长,原有工作区规格可能不再满足您的需求。此时,您可以任意选择如下两种方式解决容量问题:
- 按合理的维度(比如开发/生产环境)把用量简单拆到不同的工作区。
- 购买更高规格的工作区,并将流量切到新的工作区。
说明
暂时不支持工作区的规格更配。