hbase的wal有几个
 社区干货
社区干货
Pulsar 在云原生消息引擎领域为何如此流行?| 社区征文
每个消息都被路由到几个 broker 中的一个。分区在 broker 间的分布由 Pulsar 自动处理。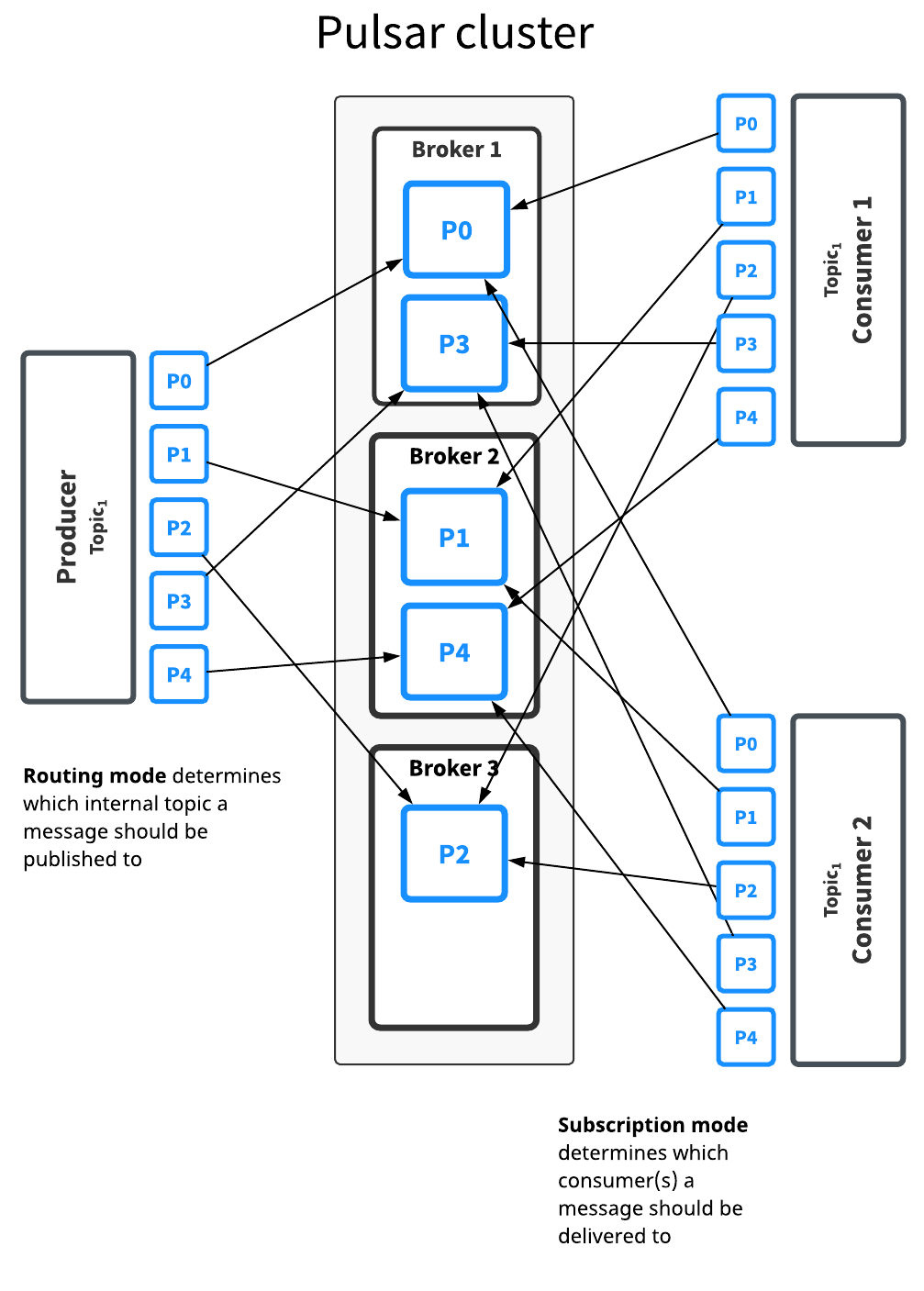如上图,Topic1 主题有 5 个分... 而订阅模式决定将哪些消息发送到哪个消费者。在大多数情况下,可以分别决定路由和订阅模式。通常,吞吐量问题应该指导分区/路由决策,而订阅决策应该根据应用程序语义进行指导。就订阅模式的工作方式而言,分区主题...
数据库顶会 VLDB 2023 论文解读 - Krypton: 字节跳动实时服务分析 SQL 引擎设
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应对...
基于国产化环境的金融级业务系统性能优化实践|社区征文
它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工作负载,或者是传统的OLTP应用。2006年,NonStop SQL的OLAP分支Neoview诞生,而Trafodion直接继承于Neoview和其后续... 多少数据库服务器进行部署,要求最终的TPS,然后按照此目标对OS、DB、应用进行优化。## l **CPU优化**:定时机制调整```jssysctl –w kernel.timer_migration=0;禁止时钟迁移;sysctl –w kernel.numa_balanci...
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应...
 特惠活动
特惠活动
 hbase的wal有几个-优选内容
hbase的wal有几个-优选内容
 hbase的wal有几个-相关内容
hbase的wal有几个-相关内容
数据库顶会 VLDB 2023 论文解读:Krypton: 字节跳动实时服务分析 SQL 引擎设计
结果通过 ETL 导入到 HBase/ES/ClickHouse 等系统提供在线的查询服务。对于实时链路, 数据会直接进入到 HBase/ES 提供高并发低时延的在线查询服务,另一方面数据会流入到 ClickHouse/Druid 提供在线的查询聚合服务。这带来的问题就像引言中所说,数据被冗余存储了多份,导致了很多一致性问题,也造成了大量的资源浪费。为了解决这个问题,我们设计了 Krypton(HSAP),系统的设计目标主要有几个点:1. 可伸缩。我们希望设计一款能够应...
9年演进史:字节跳动 10EB 级大数据存储实战
HBase,日志服务,Kafka 数据存储 - Yarn,Flink 的计算框架平台数据 - Spark,MapReduce 的计算相关数据存储![]()# **字节跳动特色的** **HDFS** **架构**在深入相关的技术细节之前,我们先看看字节跳动的 H... 大的阶段归纳起来会有这样几个阶段。### **第一阶段**业务增长初期,集群规模增长趋势非常陡峭,单集群规模很快在元数据服务器 Name Node 侧遇到瓶颈。引入联邦机制(Federation)实现集群的横向扩展。联邦又带来...
字节跳动数据库的过去、现状与未来
我们把数据库的 Wal 和 Page 放到不同介质里,来实现成本和性能之间的平衡。第三是读写分离。我们最大可以支持一组 15 从的配比,当读流量比较大时,用户可以通过弹性扩充应对读的负载,这在字节跳动内部已经被大规模... 还是 HBase、MongoDB,它们都旨在解决 OLTP 型数据库吞吐量、扩展性不足的问题。到 2010 年,Google 开始大量使用 NoSQL 和 BigData 数据库系统,但很快它就发现了不少问题,比如 NoSQL 不支持事务且每个产品的 NoSQ...
字节跳动数据库的过去、现状与未来
我们把数据库的 Wal 和 Page 放到不同介质里,来实现成本和性能之间的平衡。第三是 **读写分离** 。我们最大可以支持一主 15 从的配比,当读流量比较大时,用户可以通过弹性扩充应对读的负载,这在字节跳动内部已经... 还是 HBase、MongoDB,它们都旨在解决 OLTP 型数据库吞吐量、扩展性不足的问题。到 2010 年,Google 开始大量使用 NoSQL 和 BigData 数据库系统,但很快它就发现了不少问题,比如 NoSQL 不支持事务且每个产品的 NoS...
基于火山引擎 EMR 构建企业级数据湖仓
该服务有几个特点:- 它是独立于集群之外运行的一个常驻服务; - 提供了持久化的 History 的数据存储。当该集群销毁之后,历史数据还可保存 60 天。 - 提供原生的 History Server UI,用户不会感觉生疏。 - ... 还有一种是在线机器学习的场景。在这种场景下,数据通过离线的方式存到数据湖仓。基于离线的数据,可以通过 Spark 进行特征抽取及特征工程,然后把提取出来的特征再返存到湖仓或者 HBase 等键值存储。 基于这些离线的...
OLAP 在火山 EMR 的最佳实践
HBase及调度等多个系统,维护工作大。此外,Kylin还对接了BI系统,相关数据主要提供BI工具使用,相关架构的替换还需要考虑BI兼容性问题。相关架构升级后,SR与mysql及BI工具的适配性好;性能好,无物化视图的情况已经比... 对性能均有比较大的损耗。火山目前在这方面,计划引入行列混存及WAL+MemTable的写入,提升高并发及点查能力。- 云原生升级:目前SR/Doris都在进行CN节点优化,但现在的支持度上更多是支持外表数据的优化,在湖仓场景...
OLAP 在火山引擎 EMR 的最佳实践
HBase及调度等多个系统,维护工作大。此外,Kylin还对接了BI系统,相关数据主要提供BI工具使用,相关架构的替换还需要考虑BI兼容性问题。相关架构升级后,SR与MySQL及BI工具的适配性好;性能好,无物化视图的情况已经比... 对性能均有比较大的损耗。火山目前在这方面,计划引入行列混存及WAL+MemTable的写入,提升高并发及点查能力。- 云原生升级:目前SR/Doris都在进行CN节点优化,但现在的支持度上更多是支持外表数据的优化,在湖仓场景...
观点|SparkSQL在企业级数仓建设的优势
> > > 企业级数仓架构设计与选型的时候需要从开发的便利性、生态、解耦程度、性能、 安全这几个纬度思考。本系列分两次连载, **第一部分(本文)分享我们在企业级数仓建设上的技术选型观点** ,第二个部分则重点介... MapReduce和HBase,形成了早期Hadoop的三大利器。然而这三大利器更聚焦在异构数据的信息提取处理上,没有提供对结构化数据很友好的类似SQL语法的分析入口,同时在编程态的支撑也不够友好,只有Map和Reduce两阶段,...
干货 | 这样做,能快速构建企业级数据湖仓
该服务有几个特点:* 独立于集群之外运行的常驻服务;* 提供持久化的 History 数据存储。当该集群销毁之后,历史数据还可保存 60 天;* 提供原生 History Server UI,用户不会感觉生疏;* 租户间 History 数据隔离;... 并把提取出来的特征返存到湖仓或者 HBase 等键值存储。基于离线的数据可以进行离线训练,如通过 Spark MLlib 搭建传统的机型学习模型,或者通过 TensorFlow 进行深度模型的训练,把深度训练出来的模型部署到模型...
