hbase大规模数据迁移
 社区干货
社区干货
9年演进史:字节跳动 10EB 级大数据存储实战
从集群规模和数据量来说,HDFS 平台在公司内部已经成长为总数十万台级别服务器的大平台,支持了 10 EB 级别的数据量。**当前在字节跳动,** **HDFS** **承载的主要业务如下:**- Hive,HBase,日志服务,Kafka 数据... BookKeeper 在大规模多节点数据同步上表现得更稳定可靠)。Name Node 负责存储整个 HDFS 集群的元数据信息,是整个系统的大脑。一旦故障,整个集群都会陷入不可用状态。因此 Name Node 有一套基于 ZKFC 的主从热备的...
基于国产化环境的金融级业务系统性能优化实践|社区征文
数据库采用国产分布式数据库,QianBase;QianBase是基于Trafodion架构。Trafodion是HP公司资助的一个开源项目。它提供了一个成熟的企业级SQL on HBase解决方案。Trafodion的主要设计思想是处理operational类型的工... 多少数据库服务器进行部署,要求最终的TPS,然后按照此目标对OS、DB、应用进行优化。## l **CPU优化**:定时机制调整```jssysctl –w kernel.timer_migration=0;禁止时钟迁移;sysctl –w kernel.numa_balanci...
火山引擎上云迁移指南(一):上云迁移背景与流程
迁移到其他云上。 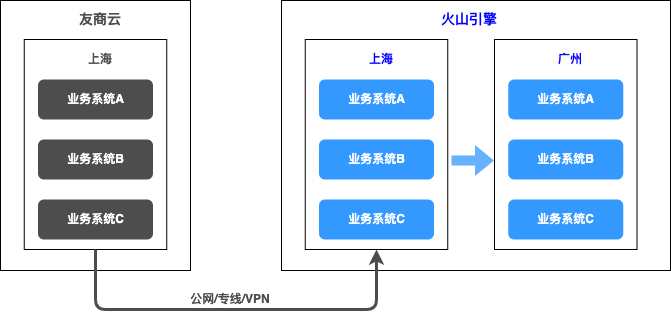### 云迁移策略云迁移可能会涉及到将所有系统和数据迁移到云上,没有放之... 物理机迁移至虚拟机)、V2V(Virtual to Virtual,虚拟机迁移至虚拟机),这种“提升和转移”模式将数据资产从本地转移到云基础架构,尤其适用于大规模迁移。 || 更换平台 | 高 | 也称为 “修补后迁移”,在不改变应用核...
一文读懂火山引擎云数据库产品及选型
纵观整个数据库发展史,关系型数据库系统是历史最悠久并且使用最广泛的一类数据库系统,其理论基础是基于 IBM 研究员 E.F.Codd 博士在 1970 年提出的“关系模型(Relational model)”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着 2000 年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了 No...
 特惠活动
特惠活动
 hbase大规模数据迁移-优选内容
hbase大规模数据迁移-优选内容
 hbase大规模数据迁移-相关内容
hbase大规模数据迁移-相关内容
火山引擎上云迁移指南(一):上云迁移背景与流程
迁移到其他云上。 ### 云迁移策略云迁移可能会涉及到将所有系统和数据迁移到云上,没有放之... 物理机迁移至虚拟机)、V2V(Virtual to Virtual,虚拟机迁移至虚拟机),这种“提升和转移”模式将数据资产从本地转移到云基础架构,尤其适用于大规模迁移。 || 更换平台 | 高 | 也称为 “修补后迁移”,在不改变应用核...
一文读懂火山引擎云数据库产品及选型
纵观整个数据库发展史,关系型数据库系统是历史最悠久并且使用最广泛的一类数据库系统,其理论基础是基于 IBM 研究员 E.F.Codd 博士在 1970 年提出的“关系模型(Relational model)”。关系型数据库也是过去几十年里各行各业使用最多最广泛的数据库类型。随着 2000 年之后移动互联网的大规模爆发,催生出了丰富多彩的面向互联网的应用,这些应用共同的特点是并发量非常高,数据量特别大。基于这些互联网的新场景与新需求,又出现了 No...
功能发布记录
HBase组件中新增ThriftServer服务。 更改、增强和解决的问题【组件】Spark组件版本由3.3.3升级为3.5.1。 【组件】StarRocks组件版本由3.1.6升级为3.2.3,支持Assume role方式访问对象存储TOS,以及访问Paimon数据。... 大数据型 D 系列实例规格组,丰富了集群节点的类型,大规模 HDFS 建议使用 D 系列降低成本。 支持ECS实例 新增集群类型 新增 EMR Stream 集群类型,新增 Kafka、Flink 组件,大数据流式计算场景,可以使用独立的 Kafk...
Flink on K8s 企业生产化实践|社区征文
特征平台旨在解决数据存储分散、口径重复、提取复杂、链路过长等问题,在大数据与算法间架起科学桥梁,提供强有力的样本及特征数据支撑。平台从 Hive 、Hbase 、关系型数据库等大数据 ODS ( Operational Data store ... 以及大数据计算上云原生的趋势# 介绍## 2.1 K8s 简介Kubernetes 为您提供了一个可弹性运行分布式系统的框架。Kubernetes 会满足您的扩展要求、故障转移、部署模式等,Kubernetes 项目的本质,是为用户提供一个...
分布式数据库TiDB的设计和架构
数据量爆发增长,传统数据库高成本,无法线性扩容问题日益突显;分布式及分布式非关系型(NoSQL)开始快速发展,如 MongoDB,HBase。但此类数据库的局限在于无法处理交易类数据及复杂业务逻辑的特性,限制其在非互联网领域... 数据库本身能够自动进行数据修复和故障转移,对业务透明- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景