clickhousekylin
 社区干货
社区干货
观点 | 数据分析引擎百花齐放,为什么要大力投入ClickHouse?
也有ClickHouse、Kylin、Druid、Doris、StarRocks等在不同场景各具特色的新一代分析引擎。这些产品各有胜场,用户在进行选择时需要对各产品有全面的了解,并且要求产品知识紧跟最新版本,才能准确的选出适合自己公司的产品。字节跳动旗下抖音、今日头条等产品的成长速度很快,需要分析处理的数据也随之指数级的快速增长,这对分析的实时性有极高的要求。在选择OLAP引擎时,字节也尝试过Kylin、Druid、Spark等,并且其他产品也做了广泛...
从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
ClickHouse、 Druid、 Elastic Search、 Kylin 等,通过分析用户需求后选择了 ClickHouse:- 能更快地观察算法模型,没有预计算所导致的高数据时延;- ClickHouse 既适合聚合查询,配合跳数索引后,对于明细点查性能也不错;- 字节自研的 ClickHouse 支持 Map 类型,支持动态变更的维度和指标,更加符合需求;- BitSet 的过滤 Bloom Filter 是比较好的解决方案,ClickHouse 原生就有 BF 的支持;- 字节自研的 ClickHouse 引擎...
干货|从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
ClickHouse、 Druid、 Elastic Search、 Kylin 等,通过分析用户需求后选择了 ClickHouse: * 能更快地观察算法模型,没有预计算所导致的高数据时延;* ClickHouse 既适合聚合查询,配合跳数索引后,对于明细点查性能也不错;* 字节自研的 ClickHouse 支持 Map 类型,支持动态变更的维度和指标,更加符合需求;* BitSet 的过滤 Bloom Filter 是比较好的解决方案,ClickHouse 原生就有 BF 的支持;* 字节自研的 ClickHouse 引擎已经通...
从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
ClickHouse、 Druid、 Elastic Search、 Kylin 等,通过分析用户需求后选择了 ClickHouse:* 能更快地观察算法模型,没有预计算所导致的高数据时延;* ClickHouse 既适合聚合查询,配合跳数索引后,对于明细点查性能也不错;* 字节自研的 ClickHouse 支持 Map 类型,支持动态变更的维度和指标,更加符合需求;* BitSet 的过滤 Bloom Filter 是比较好的解决方案,ClickHouse 原生就有 BF 的支持;* 字节自研的 ClickHouse 引擎已经通过 ...
 特惠活动
特惠活动
 clickhousekylin-优选内容
clickhousekylin-优选内容
 clickhousekylin-相关内容
clickhousekylin-相关内容
第一现场 | ClickHouse为啥在字节跳动能这么火?
直到现在它也依然是字节 ClickHouse 最重要的业务场景之一。其实在尝试 ClickHouse 之前,为了解决数据量和分析效率的问题,字节的工程师们已经在数据分析引擎层面做了不少探索,当然也经历了一些曲折。在 OLAP 引擎上,团队尝试过 Kylin、Druid、Spark 等。这些不同的尝试,也是根据当时面临的最迫切的问题做出的选择。比如一开始,最需要解决的是“快”,所以团队选了 Kylin,它的优点是能够提供毫秒级别的查询延时。但 Kylin 也...
干货 | 基于ClickHouse的复杂查询实现与优化
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/a0ddfa72a46a46df81a1fc723458a633~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1713543622&x-signature=awLXUuXfA3BlxXQW%2FAhF%2FKAP8Lg%3D)> > > ClickHouse作为目前业内主流的列式存储数据库(DBMS)之一,拥有着同类型DBMS难以企及的查询速度。作为该领域中的后起之秀,ClickHouse已凭借其性能优势引领了业内新一轮分析型...
干货 | 性能提升5倍!ClickHouse增强计划之“资源隔离”
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/290524aa23b840598102cdbf1065b355~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1713543622&x-signature=OTLwHYnnWO3PD7UIlGSh653ko8o%3D)> > > 字节跳动内部已经将Click> House广泛应用,并在原引擎基础上重构了技术架构,> **本系列文章将从Upsert、多表关联查询、可用性提升、资源隔离等多方面介绍字节跳动基于ClickHou...
干货 | ByteHouse:基于ClickHouse 的实时计算能力升级
选择ClickHouse原因,基于ClickHouse的四个维度优化、多场景实践四个版块,**介绍ByteHouse基于ClickHouse的实时计算能力升级。** 使用原生ClickHouse集群进行节点数据查询和写入时,通常会配合使用chproxy来对查询进行负载均衡。但由于chproxy缺少TCP协议支持,导致性能、查询能力等受限。这也成为困扰众多...
干货|如何基于ClickHouse玩转向量检索?
**火山引擎ByteHouse团队**基于社区ClickHouse进行技术演进**,提出了全新的向量检索功能设计思路,满足业务对向量检索稳定性与性能方面的需求。** 在 12 月 28-29 日上海 QCon 全球软件开发大会上, **火山引擎ByteHouse技术专家田昕晖将分享基于《云原生数仓 ByteHouse 构建高性能向量检索技术实践》话题。** 以下是InfoQ与火山引擎ByteHouse的 **十问十答** ,将提前为您揭秘一款OLAP引擎将如何设计高性能...
字节跳动基于 ClickHouse 优化实践之“资源隔离”
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 相信大家都对大名鼎鼎的 ClickHouse 有一定的了解了,它强大的数据分析性能让人印象深刻。但在字节大量生产使用中,发现了 ClickHouse 依然存在了一定的限制。例如:- 缺少完整的 upsert 和 delete 操作- 多表关联查询能力弱- 集群规模较大时可用性下降(对字节尤其如此)- 没有资源隔离能力本篇将详细介绍我们是如何...
作为国内规模最大的 ClickHouse 用户,字节跳动踩过哪些坑?
ClickHouse 由于其性能方面的突出优势,正在分析型数据库领域掀起一波新的技术浪潮。作为国内规模最大的 ClickHouse 用户,目前字节跳动内部的 ClickHouse 节点总数超过 **15000** 个,管理总数据量超过 **600PB** ... 其实在选 ClickHouse 之前,我们也做了比较多的技术选型工作。当时我们有一个相对比较有挑战的技术场景,是要基于很多明细数据做行为分析,这一块我们研究了挺长时间,当时也试用了 Presto、Kylin 等等各种各样的分析...
基于ClickHouse的复杂查询实现与优化|社区征文
## 项目背景ClickHouse的执行模式与Druid、ES等大数据引擎类似,其基本的查询模式可分为两个阶段。第一阶段,Coordinator在收到查询后,将请求发送给对应的Worker节点。第二阶段,Worker节点完成计算,Coordinator在收到各Worker节点的数据后进行汇聚和处理,并将处理后的结果返回。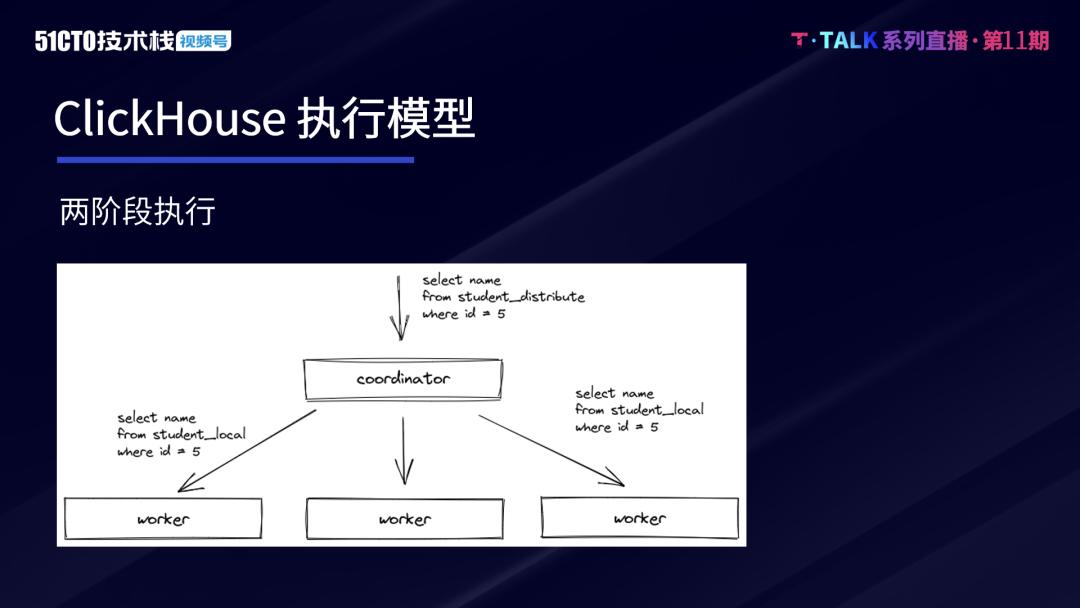两阶段的执行模式能...
