图书馆数据库权力流程图
 社区干货
社区干货
掘地三尺,搞定 Redis 与 MySQL 数据一致性问题 | 社区征文
Redis 拥有高性能的数据读写功能,被我们广泛用在缓存场景,一是能提高业务系统的性能,二是为数据库抵挡了高并发的流量请求,[点我 -> 解密 Redis 为什么这么快的秘密](https://mp.weixin.qq.com/s/z4VjDaDDbspFz1rIB... 由缓存抽象层来完成缓存数据和数据库数据的更新**,时序流程图如下: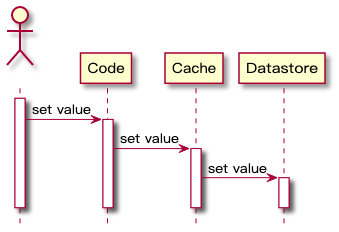`Write-Through` 的主要好处是应用系统的不需要...
火山引擎ByteHouse:分析型数据库如何设计并发控制?
> 更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 分析型数据库设计并发控制的主要原因是为了确保数据的完整性和一致性,同时提高数据库的吞吐量和响应速度。并发控制可以... 事务提交详细流程图- Consistency(一致性)ByteHouse选择的分布式key-value存储系统,ByteKV和Foundation已经提供了一致性的支持,直接复用即可。- Isolation(隔离性)ByteHouse对用户提供Read Committed(...
一文读懂火山引擎云数据库产品及选型
# 1、为什么要做数据库选型## 1.1、数据库选型的重要性与难点发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础软件领域,有三... 可以获得更强的数据库能力,也可以聘请更专业的DBA进行数据库维护,保障数据库系统稳定运行。企业组织中越是重要核心的数据库系统,会获得更多的资源投入。DBA,Database Administrator,是数据库管理员的简称。从名字...
一文读懂火山引擎云数据库产品及选型
为什么要做数据库选型 **数据库选型的重要性与难点**发展数字经济是当下各行各业的重要方向。支撑数字经济的底座是软件,特别是基础软件,可以说基础软件是整个数字经济的坚实底座。在基础... 可以获得更强的数据库能力,也可以聘请更专业的 DBA 进行数据库维护,保障数据库系统稳定运行。企业组织中越是重要核心的数据库系统,会获得更多的资源投入。DBA,Database Administrator,是数据库管理员的简称。从...
 特惠活动
特惠活动
 图书馆数据库权力流程图-优选内容
图书馆数据库权力流程图-优选内容
 图书馆数据库权力流程图-相关内容
图书馆数据库权力流程图-相关内容
NL2SQL:智能对话在打通人与数据查询壁垒上的探索 | 社区征文
它可以充当数据库的智能接口,让不熟悉数据库的用户能够快速地找到自己想要的数据,改善用户与数据库的交互方式。#### 2.2 NL2SQL的目标与定位从技术的角度来看,NL2SQL的本质是将用户的自然语言语句转化为计算机可... 最终的损失函数为loss_wc+loss_wo+loss_ws+loss_sel。模型的优化器可使用Adam优化器,是目前深度模型常用的优化器,包含两阶动量对梯度进行处理,其算法流程图如图五。 # 背景腾讯自选股App在增加了综合得分序的Feed流排序方式:需要每天把(将近1000W数据量)的feed流信息进行算分计算更新后回写到数据层。目前手上的批跑物理机器是16核(因为混部,无法独享CPU),同... [业务流程图.png](https://p9-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/f9026c5796404507b7104e3dec3346f7~tplv-k3u1fbpfcp-5.jpeg?)### 针对上述的业务逻辑,设计出了最初方案- 查询DB或者本地缓存获取索引f...
字节跳动实时数据湖构建的探索和实践
主要用于将在线数据库导入到离线数仓,和不同数据源之间的批式传输。在2020年,我们基于Flink构造了MQ-Hive的实时数据集成通道,主要用于将消息队列中的数据实时写入到Hive和HDFS,在计算引擎上做到了流批统一。到... 这是最终的CDC数据导入流程图。首先,不同的数据库会将Binlog发送到消息队列中,Flink任务会将所有数据转换成HoodieRecord格式,然后通过哈希索引找到对应的文件ID,通过一层对文件ID的shuffle后,数据到达了写入层,写...
云启万物:如何基于云原生打造云上增长新动力
云原生数据库、云原生AI、云原生消息队列等等,开始在为各类技术做着冠名。 对应地火山引擎也推出了面向算力、应用和场景的全栈云原生产品解决方案。在面向算力层,通过VKE、弹性容器可以帮助企业实现更加高效和低成... 形成大数据时代支撑数据密集型科研新范式的新型数字计算“图书馆”,科研成果将会以可计算操作的Workspace形式呈现给大家。 我今天的报告就到这里,谢谢大家! 华泰证券王玲:拥抱云原生的下一代交易平台各位来宾上午好...
干货|什么是瞬态集群?解读火山引擎EMR Stateless 的创新理念以及应用
**左边这个流程图,是一个传统的 Stateful 模式。**在这个模式下,大家要提交一个任务的数据流程通常是这样的,首先必须要有一个长时间运行的集群,有了集群以后,再将任务提交上去,接下来无论是通过 IO 的直接返回... NoSQL 数据库以及机器学习等相关内容。**这个是带有计算特性的集群中,所有带有状态部分的内容都被剥离了。Stateless把 History Serverhe 和 UI 相关的内容都剥离成为独立服务,包含 Spark History Server, Presto...
干货|什么是瞬态集群?解读火山引擎EMR Stateless 的创新理念以及应用
**左边这个流程图,是一个传统的 Stateful 模式。**在这个模式下,大家要提交一个任务的数据流程通常是这样的,首先必须要有一个长时间运行的集群,有了集群以后,再将任务提交上去,接下来无论是通过 IO 的直接返回,还... NoSQL 数据库以及机器学习等相关内容。** 这个是带有计算特性的集群中,所有带有状态部分的内容都被剥离了。Stateless把 History Serverhe 和 UI 相关的内容都剥离成为独立服务,包含 Spark History Server, Presto...
解读火山引擎 EMR Stateless 的创新理念以及应用
**左边这个流程图,是一个传统的 Stateful 模式。**在这个模式下,大家要提交一个任务的数据流程通常是这样的,首先必须要有一个长时间运行的集群,有了集群以后,再将任务提交上去,接下来无论是通过 IO 的直接返回,还... NoSQL 数据库以及机器学习等相关内容。这个是带有计算特性的集群中,所有带有状态部分的内容都被剥离了。Stateless把 History Serverhe 和 UI 相关的内容都剥离成为独立服务,包含 Spark History Server, Presto Hi...
