hashmap存储对象原理
 社区干货
社区干货
万字长文带你漫游数据结构世界|社区征文
**何为逻辑结构和存储结构?****数据元素之间的逻辑关系,称之为逻辑结构**,也就是我们定义了对操作对象的一种数学描述。但是我们还必须知道在计算机中如何表示它。**数据结构在计算机中的表示(又称为映像),称之为... 但是跳表的原理非常简单,实现也比红黑树简单很多。主要的原理是用空间换时间,可以实现近乎二分查找的效率,实际上消耗的空间,假设每两个加一层, `1 + 2 + 4 + ... + n = 2n-1`,多出了差不多一倍的空间。你看它像不...
云原生环境下的日志采集、存储、分析实践
业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的文件。- Streaming Sidecar:有一些业务系统的日志不是标准输出,而是文件输出。Streaming Sidecar 的方式可以把这些文件输出通过 Sidecar 容... 当日志存储达到一定周期,不再需要实时分析之后,用户可以把日志投递到成本更低的火山引擎对象存储服务中,或者通过 Kafka 协议投递到其他云产品。如果用户有更高阶的分析需求,TLS 也支持把日志消费到实时计算、流式计...
年终学习大礼包|云原生大数据知识地图
存储统一负载为特点,可以支持多种计算负载,计算调度更弹性,存储效能更高的大数据处理和分析平台。云原生大数据带来了大数据在使用和运维方面的巨大变化,从以下三个角度来看:* **业务层面**:传统模式下,业务独立... 但此时计算存储是单独管理的。 **存算分离负载** :* 降低扩缩容和数据 Rebalance 时间:云原生数据湖、数据仓、消息队列、搜索引擎如果支持存算分离的部署模式,将存储放在统一的大数据文件存储或对象存储上,这...
轻量级 Kubernetes 多租户方案的探索与实践
作者:任静思,火山引擎云原生工程师> 本文整理自火山引擎开发者社区 Meetup 第八期演讲,主要介绍了字节跳动轻量级 Kubernetes 多租户方案 KubeZoo 的适用场景和实现原理。## Kubernetes 多租户模型伴随着云原... 不同租户之间的请求被映射到了后端集群的不同 Namespace 或者不同的 Cluster scope 的对象上,租户之间相互不干扰。 - 同时它又能够提供比较完整的 Kubernetes API,租户既能使用 Namespace 级别的资源,又能使...
 特惠活动
特惠活动
 hashmap存储对象原理-优选内容
hashmap存储对象原理-优选内容
 hashmap存储对象原理-相关内容
hashmap存储对象原理-相关内容
云原生环境下的日志采集、存储、分析实践
开源系统的采集配置难以管理,数据源也比较单一。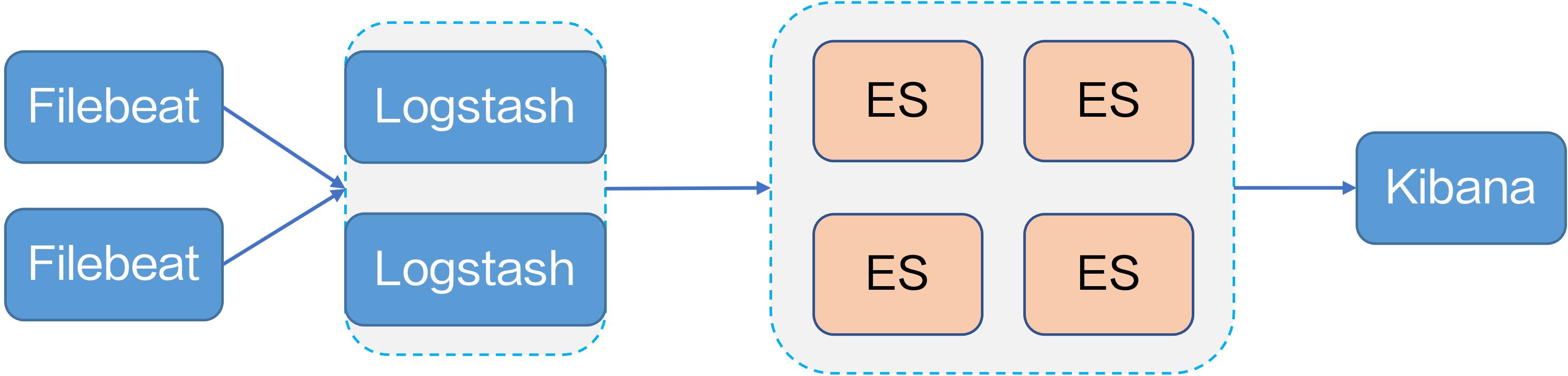### Kubernetes 下的日志采集Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的...
追加上传(Android SDK)
对象被覆盖且对象类型由 Appendable 变为 Normal。反之通过 putObject 上传的对象不支持追加写操作。 appendObject 创建的对象不支持拷贝。 如果您的存储桶处于开启或者暂停多版本功能的状态下,或存储桶的类型为低... import java.util.HashMap;import java.util.Map;public class AppendObjectExample extends AppCompatActivity { @Override protected void onCreate(Bundle savedInstanceState) { String endpoint...
普通上传(Java SDK)
上传对象时,对象名必须满足一定规范,详细信息,请参见对象命名规范。 TOS 是面向海量存储设计的分布式对象存储产品,内部分区存储了对象索引数据。为横向扩展您上传对象和下载对象时的最大吞吐量和减小热点分区的概... import java.util.HashMap;import java.util.Map;public class PutObjectWithMetaOptionsExample { public static void main(String[] args) { String endpoint = "your endpoint"; String regio...
追加上传(Java SDK)
追加上传指的是在已存在的对象数据末尾追加写入新数据。追加上传创建的对象类型为追加类型(Appendable Object),可在对象末尾追加写入数据。普通上传和分片上传创建的对象类型为普通类型(Normal Object),无法追加写... custom = new HashMap<>();// custom.put("name", "volc_user");// // 在 TOS 服务端存储的元数据为:"X-Tos-Meta-name: volc_user"// options.setCustomMetadata(custom);// ...
TOS 中操作 Iceberg 表(适用于 EMR 2.x 版本)
Iceberg 表的数据,可以放在火山引擎对象存储服务 TOS 中。本章节为您介绍不同引擎组件中在 TOS 中创建 Iceberg 表的示例。 1 Spark 组件操作示例1.1 使用前提已创建包含 Iceberg、Spark 组件的火山引擎 E-MapReduc... val properties = new util.HashMap[String, String]properties.put("warehouse", "/user/hive/warehouse/iceberg/hive")properties.put("uri", "thrift://emr-master-1:9083")catalog.initialize("hive", propert...
9年演进史:字节跳动 10EB 级大数据存储实战
# 背景## **HDFS** **简介**HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:- 和本地文件系统一样的目录... Name Node 负责存储整个 HDFS 集群的元数据信息,是整个系统的大脑。一旦故障,整个集群都会陷入不可用状态。因此 Name Node 有一套基于 ZKFC 的主从热备的高可用方案。Name Node 还面临着扩展性的问题,单机承载能...
分片上传(Android SDK)
对象的服务端加密方式,当前只支持 AES256 options.setServerSideEncryption("AES256"); // 自定义对象的元数据,对于自定义的元数据,SDK 会自动对 key 添加 // "X-Tos-Meta-" 的前缀,并保存在服务端。 Map custom = new HashMap<>(); custom.put("name", "volc_user"); // 在 TOS 服务端存储的元数据为:"X-T...
大对象场景(Java SDK)
本文介绍 TOS 中较大对象的常见使用场景。 上传大对象:请参见分片上传。 下载大对象:请参见范围下载。 拷贝大对象:请参见分片拷贝。
免费公测|火山引擎大数据文件存储公测现已开启!
计算资源和存储资源扩容速度不匹配 ,不同时期需要不同的存储空间和计算能力配比,导致机器选型不便;2. 计算资源和存储资源按某一比例强绑定,系统扩容必须按节点数目增加,导致内存或磁盘的浪费;3. 在云计算场景下,因计算集群中包含数据,导致不能实现真正的弹性计算。企业可以通过云上存算分离架构,以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO...
