用对象存储数据的优点
 社区干货
社区干货
免费公测|火山引擎大数据文件存储公测现已开启!
以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO 瓶颈)、接口兼容性等问题,火山引擎推出自研的 **大数据文件存储(CloudFS)**作为解决方案。火山引擎大数据文件存储以对象存储为底座,针对大数据和机器学习场景进行了完整的兼容和优化,助力更多企业改善云上大数据体验。 **现已开放免费公测,欢迎申请试用。** **CloudFS** **大...
免费公测|火山引擎大数据文件存储公测现已开启!
以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO 瓶颈)、接口兼容性等问题,火山引擎推出自研的**大数据文件存储(CloudFS)** 作为解决方案。火山引擎大数据文件存储以对象存储为底座,针对大数据和机器学习场景进行了完整的兼容和优化,助力更多企业改善云上大数据体验。**现已开放免费公测,欢迎申请试用。**# 大数据文件存储 CloudFS大数据文件存储是...
火山引擎上云迁移指南(二):迁移实施
是一个线上存储迁移服务,可以帮助您将其他云服务商对象存储服务的数据在线迁移至火山引擎对象存储TOS中。- **源端支持场景** - 阿里云 - 腾讯云 - 华为云 - 其他S3协议对象存储 - 对象存储-火山引擎 - **迁移流程** 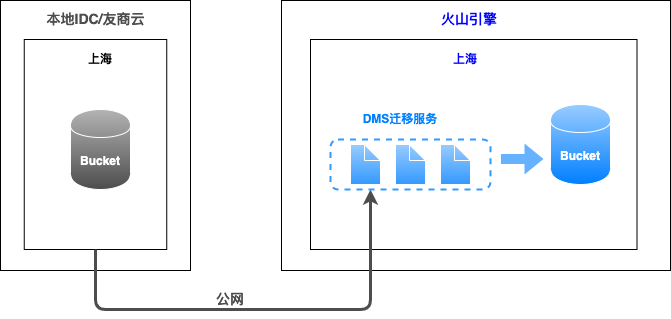- **产品优势** - 简单易用:提供GUI界面操作,使用简单 - 安全认证:采用AK/S...
基于火山引擎 EMR 构建企业级数据湖仓
开放存储:数据不局限于某种存储底层,支持包括从本地、HDFS 到云对象存储等多种底层。 - Table 格式:本质上是基于存储的、 Table 的数据+元数据定义。具体来说,这种数据格式有三个具体的实现:Delta Lake、Iceberg 和 Hudi。三种格式提出的出发点略有不同,但是它们的场景需求里都不约而同地包含了事务支持和流式支持。而它们在具体的实现中也采用了比较相似的做法,即在数据湖的存储之上定义一个元数据,并跟数据一样保存在...
 特惠活动
特惠活动
 用对象存储数据的优点-优选内容
用对象存储数据的优点-优选内容
 用对象存储数据的优点-相关内容
用对象存储数据的优点-相关内容
免费公测|火山引擎大数据文件存储公测现已开启!
以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO 瓶颈)、接口兼容性等问题,火山引擎推出自研的 **大数据文件存储(CloudFS)**作为解决方案。火山引擎大数据文件存储以对象存储为底座,针对大数据和机器学习场景进行了完整的兼容和优化,助力更多企业改善云上大数据体验。 **现已开放免费公测,欢迎申请试用。** **CloudFS** **大...
数据迁移
veImageX 支持创建云端数据迁移任务以及拥有公网访问 URL 本地数据迁移任务,实现将数据从国内外其他云服务商的对象存储中在线,自动化拉取到 veImageX 的服务中。源对象存储可能会产生流量费用,具体费用需要参考源对象存储云厂商的定价。 已支持数据源 阿里云OSS、腾讯云COS、七牛云KODO、百度云BOS、华为云OBS、 优刻得(Ucloud File)、AWS国际站、URL 列表、其他支持 S3 协议的存储服务 说明 对于您的本地数据,您可以选择以下几个...
免费公测|火山引擎大数据文件存储公测现已开启!
以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO 瓶颈)、接口兼容性等问题,火山引擎推出自研的**大数据文件存储(CloudFS)** 作为解决方案。火山引擎大数据文件存储以对象存储为底座,针对大数据和机器学习场景进行了完整的兼容和优化,助力更多企业改善云上大数据体验。**现已开放免费公测,欢迎申请试用。**# 大数据文件存储 CloudFS大数据文件存储是...
使用对象存储静态存储卷
本文介绍如何创建对象存储类型存储卷和存储卷声明,以及工作负载如何使用对象存储静态存储卷。 前提条件已创建容器服务集群,操作方法参见 创建集群。 确保当前集群已安装对象存储服务组件 csi-tos。操作方法,请参见... 单击存储卷列表左上角 创建存储卷。 在弹出的 创建存储卷 页面,完成参数配置。 配置项 说明 创建方式 选择存储卷的创建方式,目前支持静态创建。 名称 根据系统提示,自定义存储卷的名称,需确保存储卷名称在集群内...
IDC共享云上对象存储服务
本文将介绍如何通过私网连接服务将火山引擎对象存储服务共享给本地IDC。 场景介绍云上VPC或云下IDC通过私网连接服务可以安全地访问云上的对象存储服务(Tinder Object Storage,简称TOS)。本文为您介绍使用私网连接打通TOS服务时不同场景的的配置指导。 若希望通过私网连接区分服务类型和存储桶对象,请使用接口终端节点泛域名功能。 若希望通过私网连接终端节点控制VPC访问存储桶的范围,请使用网关终端节点。 具体组网场景如下图所...
实现 vePFS 与对象存储 TOS 之间数据流动
本文介绍如何实现文件存储 vePFS 与对象存储 TOS 之间的数据流动。 适用场景加载数据集场景(TOS->vePFS):数据集从 TOS 流动到 vePFS,用于数据清洗和 GPU 训练。 训练数据归档场景(vePFS->TOS):GPU 训练的 CheckPoint 数据和训练结果归档到的至对象存储。 前提条件ECS 和 TOS 带宽均满足数据流动需求。 不同规格的 ECS 实例的网络带宽不同,建议您选择网络出入带宽 20Gbps 以上的 ECS 实例。ECS 规格详情,请参见 ECS 规格说明。 ...
挂载 TOS 对象存储
函数服务支持挂载 TOS 对象存储,将数据存储至火山引擎的 对象存储 TOS。本文为您介绍如何挂载 TOS 对象存储。 前提条件已开通火山引擎对象存储 TOS。 已在函数待部署地域,创建 TOS Bucket,详细操作可参见 创建存储桶。 已获取 API 访问密钥,要求访问密钥具有 TOS 的访问权限。具体操作可参见 Access Key(密钥)管理 和 创建用户并授权。注意 为了更好地进行权限管控,推荐使用最小化授权的 IAM 用户密钥,不建议直接使用火山引擎账号...
将 vePFS 中的数据定时备份到对象存储
适用场景保存在 vePFS 的训练的核心数据,对数据安全性要求比较高,需要把数据进行定期备份。 训练过程中的 checkpoint 数据,定期同步到对象存储中,及时释放 vePFS 的存储空间。 前提条件ECS 和 TOS 带宽均满足备份需求。 不同规格的 ECS 实例的网络带宽不同,规格详情,请参见 ECS 规格说明。 TOS 带宽的约束限制,请参见约束限制。 已创建对象存储 Bucket,具体步骤,请参见创建存储桶。 已在 ECS 挂载文件存储 vepfs,具体步骤...
CloudFS优势
用的分布式文件系统。 相比自建 HDFS 存储,使用火山引擎大数据文件存储服务 CloudFS 可以节约维护成本,降低数据安全风险。 易使用CloudFS 兼容了标准的 HDFS 协议接口,您无需对现有大数据分析应用做任何修改,即可通过火山引擎 ECS 或容器使用文件存储系统。此外,CloudFS 也和 Serverless Spark、Serverless Flink 等数据生态无缝打通,您可以轻松地接入其他数据产品。 海量存储CloudFS 依托对象存储的超大容量和成本优势,存储海量...
