can对象字典存储
 社区干货
社区干货
2022技术盘点之平台云原生架构演进之道|社区征文
对象存储/CFS,数据库有MongoDB分片集群/MySQL/Redis/ElasticSearch/RabbitMQ进行各类业务数据计算和存储## 三 流量管控、比例(-XX:SurvivorRatio=8)、(Xms)堆内存最小值、(-Xmx)堆内存最大值、(-Xmn)堆内存分配给新生代、...
免费公测|火山引擎大数据文件存储公测现已开启!
计算资源和存储资源扩容速度不匹配 ,不同时期需要不同的存储空间和计算能力配比,导致机器选型不便;2. 计算资源和存储资源按某一比例强绑定,系统扩容必须按节点数目增加,导致内存或磁盘的浪费;3. 在云计算场景下,因计算集群中包含数据,导致不能实现真正的弹性计算。企业可以通过云上存算分离架构,以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO...
 特惠活动
特惠活动
 can对象字典存储-优选内容
can对象字典存储-优选内容
 can对象字典存储-相关内容
can对象字典存储-相关内容
免费公测|火山引擎大数据文件存储公测现已开启!
计算资源和存储资源扩容速度不匹配 ,不同时期需要不同的存储空间和计算能力配比,导致机器选型不便;2. 计算资源和存储资源按某一比例强绑定,系统扩容必须按节点数目增加,导致内存或磁盘的浪费;3. 在云计算场景下,因计算集群中包含数据,导致不能实现真正的弹性计算。企业可以通过云上存算分离架构,以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO...
对象存储事件通知功能接口变更说明
为了给您提供更加优质的服务,火山引擎对象存储产品预计将于 2024 年 01 月 15 日优化事件通知功能,将同一事件仅支持推送至一个目标,优化为支持推送至多个不同的目标。 预计变更时间2024 年 01 月 15 日,具体变更时间请以控制台变更为准。 变更说明TOS 事件通知功能当前仅支持将同一事件推送至一个目标,变更后,支持将同一事件推送至多个不同的目标(通过新增 V2 版本接口实现)。接口变更影响如下: 如果您希望将事件推送至多个目标,...
云原生环境下的日志采集、存储、分析实践
开源系统的采集配置难以管理,数据源也比较单一。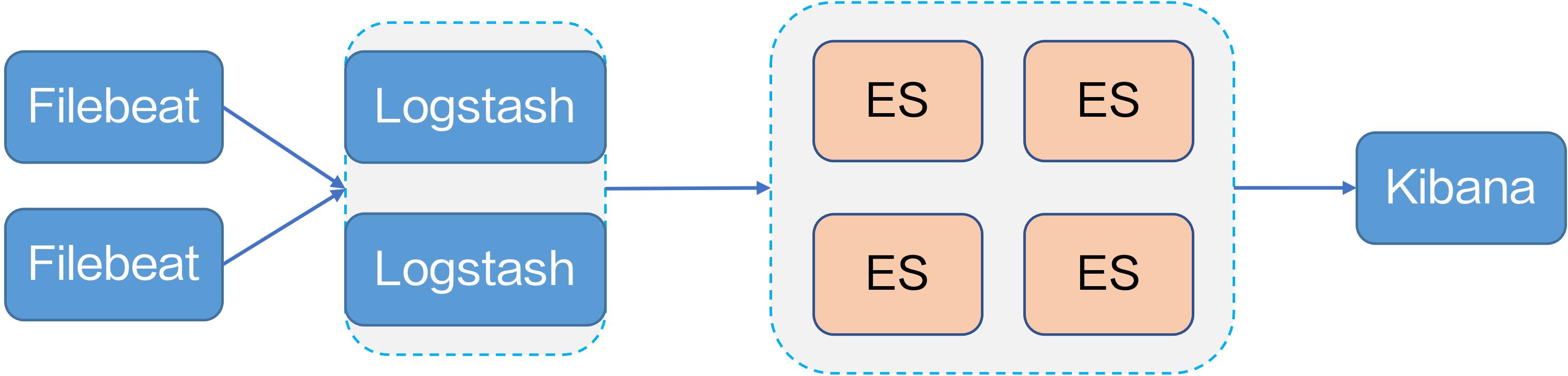### Kubernetes 下的日志采集Kubernetes 下如何采集日志呢? 官方推荐了四种日志采集方案:- DaemonSet:在每台宿主机上搭建一个 DaemonSet 容器来部署 Agent。业务容器将容器标准输出存储到宿主机上的文件,Agent 采集对应宿主机上的...
干货|ClickHouse 在UBA系统中的字典编码优化实践
Parquet的存储空间会更加有优势。同时,大多这类数据的事件属性都有低基数的特征,例如事件属性中的城市、性别、品牌等等。Parquet会自动对低基数列做字典编码,因此会获得更高的存储效率。同时ClickHouse官方也提... 另外在构建字典的过程中,是通过一个HashTable实现,这样在做Merge时这块的性能损耗较大,所以优化的关键点就是在于字典的构建过程。这里实现了一种先构建字典后做具体Merge的思路,即多个Part的Merge过程中,词典只需...
火山引擎云原生存储加速实践
底层是存储服务,目前来看存算分离是业界未来的趋势,对于云上一些标准的存储服务,可以分成以下三大类: - 第一类是对象存储,主要以 AWS S3 为标品,各个云厂商在标准能力基础上也都有一些创新服务; - ... 各个云厂商都推出了对象存储与 PFS 结合的能力,愿景是冷数据存放在对象存储,热数据在 PFS。但实际的业务体验并不是很方便,两边的数据流动也需要很多的治理成本。# 什么是“好”的存储加速我们理解的“好”的存...
免费公测|火山引擎大数据文件存储公测现已开启!
3. 在云计算场景下,因计算集群中包含数据,导致不能实现真正的弹性计算。企业可以通过云上存算分离架构,以低成本的对象存储作为存储底座,完美地解决以上问题。而针对在大数据和机器学习场景下,由对象存储带来的诸如存储性能(IO 瓶颈)、接口兼容性等问题,火山引擎推出自研的**大数据文件存储(CloudFS)** 作为解决方案。火山引擎大数据文件存储以对象存储为底座,针对大数据和机器学习场景进行了完整的兼容和优化,助力更多企业...
干货|ClickHouse 在UBA系统中的字典编码优化实践
Parquet的存储空间会更加有优势。同时,大多这类数据的事件属性都有低基数的特征,例如事件属性中的城市、性别、品牌等等。Parquet会自动对低基数列做字典编码,因此会获得更高的存储效率。 同时Click... 另外在构建字典的过程中,是通过一个HashTable实现,这样在做Merge时这块的性能损耗较大,所以优化的关键点就是在于字典的构建过程。这里实现了一种先构建字典后做具体Merge的思路,即多个Part的Merge过程中,词典只...
干货|揭秘字节跳动对Apache Doris 数据湖联邦分析的升级和优化
如果存储在数仓等系统中会非常昂贵,因此需要存储在对象存储等较便宜的存储系统中。利用湖仓一体这种架构,实现存算分离模式。 **● 更好的开放性。**支持 Parquet、ORC 等常见的大数据存储格式,也支持 H... 增加新的 ScanNode。例如,在 Hive、JDBC、ES 的设计中,分别内置了 FileScanNode、JDBCScanNode 和 ESScanNode。 在统一的调度框架下 Scanner Scheduler 下,我们会将 ScanNode 产生的 Scanner 提交到 Sca...
