kafka中的数据更新怎么处理
 社区干货
社区干货
Kafka 消息传递详细研究及代码实现|社区征文
## 背景新项目涉及大数据方面。之前接触微服务较多,趁公司没反应过来,赶紧查漏补缺。Kafka 是其中之一。Apache Kafka 是一个开源的分布式事件流平台,可跨多台计算机读取、写入、存储和处理事件,并有发布和订阅事件流的特性。本文将研究 Kafka 从生产、存储到消费消息的详细过程。 ## Producer### 消息发送所有的 Kafka 服务器节点任何时间都能响应是否可用、是否 topic 中的 partition leader,这样生产者就能发送它的...
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
可以根据需要随时读取主题中的事件——与传统消息传递系统不同,事件在消费后不会被删除。相反,您可以通过每个主题的配置设置来定义 Kafka 应该保留您的事件多长时间,之后旧事件将被丢弃。Kafka 的性能在数据大小方... metadataManager.requestUpdate(); return null; }}```### 3.5 发起网络请求发起网络请求后续会单独出一篇文章来讲### 3.6 Controller 服务端接收客户端请求服务端接收客户端请求的源码入口: ...
Kafka数据同步
即可实现实时数据同步。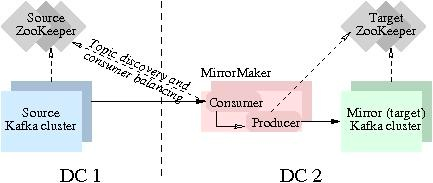本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的S... 由于火山对下载的消息进行了 Base64 编码传输(或可通过升级实例解决编码造成的),因此很难确认消息是否正确性、完整性。可以通过客户端消费如下(客户端下载与使用可参考:[https://www.volcengine.com/docs/6439/12...
消息队列选型之 Kafka vs RabbitMQ
Kafka 和 RabbitMQ 比较好用,用哪个更好呢?”想必大家也曾有过类似的疑问。对此本文将在接下来的内容中以 Kafka 和 RabbitMQ 为例分享消息队列选型的一些经验。消息队列即 Message+Queue,消息可以说是一个数据传... 最重要的优势就是能用来平滑处理系统中的高峰流量。当系统面临瞬时高流量时,消息队列可以作为一个缓冲层,将大量的请求消息存储在队列中,然后按照系统处理能力逐渐消费这些消息,平稳地处理高峰流量。 特惠活动
特惠活动
 kafka中的数据更新怎么处理-优选内容
kafka中的数据更新怎么处理-优选内容
 kafka中的数据更新怎么处理-相关内容
kafka中的数据更新怎么处理-相关内容
聊聊 Kafka:Topic 创建流程与源码分析 | 社区征文
可以根据需要随时读取主题中的事件——与传统消息传递系统不同,事件在消费后不会被删除。相反,您可以通过每个主题的配置设置来定义 Kafka 应该保留您的事件多长时间,之后旧事件将被丢弃。Kafka 的性能在数据大小方... metadataManager.requestUpdate(); return null; }}```### 3.5 发起网络请求发起网络请求后续会单独出一篇文章来讲### 3.6 Controller 服务端接收客户端请求服务端接收客户端请求的源码入口: ...
Kafka
1. 概述 Kafka Topic 数据能够支持产品实时数据分析场景,本篇将介绍如何进行 Kafka 数据模型配置。 温馨提示:Kafka 数据源仅支持私有化部署模式使用,如您使用的SaaS版本,若想要使用 Kafka 数据源,可与贵公司的客户成功经理沟通,提出需求。 2. 快速入门 下面介绍两种方式创建数据连接。 2.1 从数据连接新建(1)在数据准备模块中选择数据连接,点击新建数据连接。(2)点击 Kafka 进行连接。(3)填写连接的基本信息,点击测试连接,显示连...
消息队列 Kafka版-火山引擎
消息队列 Kafka版是一款基于 Apache Kafka 构建的分布式消息中间件服务。具备高吞吐、高可扩展性等特性,提供流式数据的发布/订阅和多副本存储机制,广泛应用于日志压缩收集、流式数据处理、消息解耦、流量削峰去谷等应用场景
Kafka/BMQ
Kafka 连接器提供从 Kafka Topic 或 BMQ Topic 中消费和写入数据的能力,支持做数据源表和结果表。您可以创建 source 流从 Kafka Topic 中获取数据,作为作业的输入数据;也可以通过 Kafka 结果表将作业输出数据写入到 Kafka Topic 中。 注意事项使用 Flink SQL 的用户需要注意,不再支持 kafka-0.10 和 kafka-0.11 两个版本的连接器,请直接使用 kafka 连接器访问 Kafka 0.10 和 0.11 集群。Kafka-0.10 和 Kafka-0.11 两个版本的连接...
Kafka数据同步
即可实现实时数据同步。本实验主要聚焦跑通Kafka MirrorMaker (MM1)数据迁移流程。实验中的S... 由于火山对下载的消息进行了 Base64 编码传输(或可通过升级实例解决编码造成的),因此很难确认消息是否正确性、完整性。可以通过客户端消费如下(客户端下载与使用可参考:[https://www.volcengine.com/docs/6439/12...
Kafka消息订阅及推送
1. 功能概述 VeCDP产品提供强大的开放能力,支持通过内置Kafka对外输出的VeCDP系统内的数据资产。用户可以通过监测Kafka消息,及时了解标签、分群等数据变更,赋能更多企业业务系统。 2. 消息订阅配置说明 topic规范... updater 改 被谁操作 updater 变更字段前后值 changes 建议规范,并非强制规范 "changes": [{"field_name": "name", "data_type":"String", "before": "seg_1", "after": "seg_2"},{"field_name": "d...
什么是消息队列 Kafka版
消息队列 Kafka版是一款基于 Apache Kafka 构建的分布式消息中间件服务,具备高吞吐、高可扩展性等特性,提供流式数据的发布/订阅和多副本存储机制,广泛应用于日志压缩收集、流式数据处理、消息解耦、流量削峰去谷等应用场景。 消息队列 Kafka版开箱即用,业务代码无需改造,帮助您将更多的精力专注于业务快速开发,免除繁琐的部署和运维工作。 产品功能高效的消息收发:海量消息堆积的情况下,消息队列 Kafka版仍然维持Kafka集群对消息...
配置 Kafka 数据源
为确保同步任务使用的独享集成资源组具有 Kafka 库节点的网络访问能力,您需将独享集成资源组和 Kafka 数据库节点网络打通,详见网络连通解决方案。 若通过 VPC 网络访问,则独享集成资源组所在 VPC 中的 IPv4 CIDR ... 3 支持的字段类型目前支持的数据类型是根据数据格式来决定的,支持以下两种格式: JSON 格式: json { "id":1, "name":"demo", "age":19, "create_time":"2021-01-01", "update_time":"2022-01-01"...
读取 Kafka 数据写入 TOS 再映射到 LAS 外表
Flink 是一个兼容 Apache Flink 的全托管流式计算平台,支持对海量实时数据的高效处理。LAS 是湖仓一体架构的 Serverless 数据平台,提供海量数据存储、管理、计算和交互分析功能。本文通过一个示例场景模拟 Flink 与... 并映射为湖仓一体分析服务 LAS 外表进行数据分析。在 Flink 控制台通过开发 Flink SQL 任务,实现 Datagen -> Kafka -> TOS 的数据流转链路,然后在 LAS 控制台创建外表,从 TOS 数据源读取文件并映射到新建的外表中。...
