a100支持cuda
 社区干货
社区干货
GPU实例ECC报错处理方法
请参考英伟达官方网站对于ECC的说明[NVIDIA A100 GPU 内存错误管理](https://docs.nvidia.com/deploy/a100-gpu-mem-error-mgmt/index.html)# 解决方案如果ECC报错不影响业务,则可以直接忽略,若影响到业务,直接重启,看是否能恢复,若不能恢复,提交工单对实例进行冷迁移。# 问题分析什么是ECC请参考文档[ECC说明](https://en.wikipedia.org/wiki/ECC_memory)**如果您有其他问题,欢迎您联系火山引擎**[技术支持服务](https://co...
在GPU实例中安装配置dcgm-exporter
> 测试环境:VeLinux 1.0## 创建并连接GPU实例## 安装CUDA驱动* 下载并安装CUDA依次执行以下命令,完成CUDA的下载。```javascriptnvidia-smi //查看该实例驱动信息wget https://developer.download.nvidia... > 更多信息可参考Nvidia官方地址:[NVIDIA HGX A100 Software User Guide :: NVIDIA Tesla Documentation](https://docs.nvidia.com/datacenter/tesla/hgx-software-guide/index.html#dcgm)* 开启FM服务```jav...
加速3.47倍!火山引擎助力AIGC突破性能瓶颈
AIGC(AI-Generated Content 人工智能生成内容)一经推出火爆全网,各种画风和产品形态频频出现且快速演进。以Stable Diffusion模型为例,一次完整的预训练大约需要在128张A100计算卡上运行25天,用户付费上百万,高额的研发费用是用户的痛点之一。同时,AIGC产品演进快速,对性能和资源提出更高要求。火山引擎云服务,为此类问题提供了解决方案,推动AIGC产业的发展。火山引擎打造同时支持训练加速与推理加速的自主研发高性能算子库,在全...
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 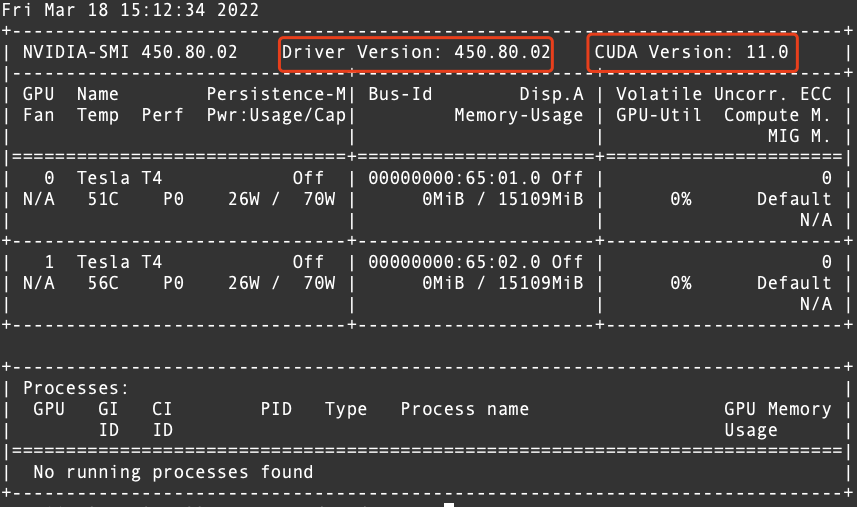 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
 特惠活动
特惠活动
 a100支持cuda-优选内容
a100支持cuda-优选内容
 a100支持cuda-相关内容
a100支持cuda-相关内容
GPU-部署Baichuan大语言模型
模型支持FP16、INT8、INT4三种精度,可以在GPU实例上部署并搭建推理应用。该模型对GPU显存的需求如下: 精度 显存需求 推荐实例规格 GPU显卡类型 FP16 27 GB ecs.g1ve.2xlarge V100 * 1(单卡32 GB显存) INT8 17 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) INT4 10 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) 软件要求注意 部署Baichuan大语言模型时,需保证CUDA版本 ≥ 11.8。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。...
GPU实例部署PyTorch
在CUDA、GPU驱动已经安装的情况下,依然不能使用,很可能是版本不匹配的问题。本文从GPU驱动开始从头彻底解决版本不匹配问题。 关于实验级别:初级 相关产品:ECS云服务器 受众:通用 操作系统:CentOS 7.8 软件版本:CUDA 11.6,GPU Driver 510.85.02,Anaconda3,Python 3.8.3 操作步骤步骤一:查看GPU驱动版本是否符合需求查看本机的驱动是否满足要求nvidia-smi回显如下,表示当前系统的驱动版本是470.57.02,其支持最高版本的CUDA是11.4. ...
GPU实例ECC报错处理方法
请参考英伟达官方网站对于ECC的说明[NVIDIA A100 GPU 内存错误管理](https://docs.nvidia.com/deploy/a100-gpu-mem-error-mgmt/index.html)# 解决方案如果ECC报错不影响业务,则可以直接忽略,若影响到业务,直接重启,看是否能恢复,若不能恢复,提交工单对实例进行冷迁移。# 问题分析什么是ECC请参考文档[ECC说明](https://en.wikipedia.org/wiki/ECC_memory)**如果您有其他问题,欢迎您联系火山引擎**[技术支持服务](https://co...
GPU A100/A800 多卡机型 RDMA 网络连通异常如何处理?
问题现象如下图所示,搭载了多张 A100/A800 显卡的节点,多张显卡间的网络无法连通。 原因分析NVIDIA-Fabric Manager 服务能够保证多张支持 NVSwitch 的显卡(例如:A100、A800)间通过 NVSwitch 互联,确保网络正常连通。当节点中未能启动 NVIDIA-Fabric Manager 服务时,将导致多张支持 NVSwitch 的显卡间网络无法连通。 解决方案创建节点池或节点扩容等新增节点场景,可将 NVIDIA-Fabric Manager 软件包内置到自定义镜像中;已有节点场...
加速3.47倍!火山引擎助力AIGC突破性能瓶颈
AIGC(AI-Generated Content 人工智能生成内容)一经推出火爆全网,各种画风和产品形态频频出现且快速演进。以Stable Diffusion模型为例,一次完整的预训练大约需要在128张A100计算卡上运行25天,用户付费上百万,高额的研发费用是用户的痛点之一。同时,AIGC产品演进快速,对性能和资源提出更高要求。火山引擎云服务,为此类问题提供了解决方案,推动AIGC产业的发展。火山引擎打造同时支持训练加速与推理加速的自主研发高性能算子库,在全...
在GPU实例中安装配置dcgm-exporter
> 测试环境:VeLinux 1.0## 创建并连接GPU实例## 安装CUDA驱动* 下载并安装CUDA依次执行以下命令,完成CUDA的下载。```javascriptnvidia-smi //查看该实例驱动信息wget https://developer.download.nvidia... > 更多信息可参考Nvidia官方地址:[NVIDIA HGX A100 Software User Guide :: NVIDIA Tesla Documentation](https://docs.nvidia.com/datacenter/tesla/hgx-software-guide/index.html#dcgm)* 开启FM服务```jav...
新功能发布记录
支持从多个 GPU 版本之间选择。帮助用户通过 VKE 更加灵活地使用 GPU 计算资源。通过选择特定的 GPU 驱动版本,对业务侧使用的 CUDA 等软件不同版本进行适配。 华北 2 (北京) 2024-01-31 自定义 GPU 驱动安装说明 华... A100 等机型多显卡间通过 NVSwitch 互联。解决实例无法正常使用的场景,优化用户体验。 华北 2 (北京) 2023-06-13 创建节点池 华南 1 (广州) 2023-06-12 华东 2 (上海) 2023-06-06 2023年05月功能名称 功能描述 发布...
实例规格介绍
平台提供多种GPU计算规格供您选择,不同计算规格提供的虚拟化能力不同,支持覆盖多种业务应用和服务场景。 根据底层硬件能力的不同,计算规格区分为不同规格族,各规格族采用不同的Intel处理器、CPU/内存配比、GPU显卡... 实例类型 GPU显卡类型 GPU计算型 GPU计算型gni2 A10 GPU计算型ini2 A30 GPU计算型pni2 A100 GPU计算型g1vc V100 GPU计算型g1ve V100 GPU计算型g1te T4 GPU计算型g1tl T4 高性能计算GPU型 高性能计算GPU型ebmhp...
GPU-部署ChatGLM-6B模型
支持在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。ChatGLM-6B使用了和ChatGLM相同的技术,针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。 软件要求注意 部署ChatGLM-6B语言模型时,需保证CUDA版本 ≥ 11.4。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以535.86.10为例...
