z370cuda支持
 社区干货
社区干货
在GPU实例中安装配置dcgm-exporter
> 测试环境:VeLinux 1.0## 创建并连接GPU实例## 安装CUDA驱动* 下载并安装CUDA依次执行以下命令,完成CUDA的下载。```javascriptnvidia-smi //查看该实例驱动信息wget https://developer.download.nvidia... 您应该会看到系统中所有支持的 GPU(以及任何 NVSwitch)的列表dcgmi nvlink -s //检查 DCGM 是否可以枚举系统中存在的 NVLink``` 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
【高效视频处理】一窥火山引擎多媒体处理框架-BMF|社区征文
BMF完整支持GPU硬件,提供CPU到GPU的数据传输。我们可以实现视频解码和视频过滤等任务的GPU加速,显著提升处理效率。它还支持不同框架如CUDA和OpenCL之间的异构计算。从这些建议简单实验开始, 开发者就可以感受到BMF模块化设计及其强大的处理能力。同时,它提供Python、C++和Go三种语言接口,语法简洁易用,无门槛上手。通过这些基础功能,我们已经看到BMF在视频管道工程中的广阔地平线。> 深入原理学习如何创建自己的视频处理模...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
而且支持相应的维度越界检查。除了 -1 轴之外,其他维度支持任意 stride 访存,此外,GEMM、TPC、DMA 的指令序列是独立的,pipeline 运行时是 latency 会被隐藏起来。此外,TPC 也添加了 AI 负载常见的激活函数,作为... 而各家 ASIC 由于具备类似 CUDA 的开发生态,往往都需要单独适配,且各家 ASIC 往往都会自带一套自身的软件栈,从使用方式,硬件管理,监控接入等层面,都需要额外开发。这些相比沿用 GPU,都是额外成本。...
 特惠活动
特惠活动
 z370cuda支持-优选内容
z370cuda支持-优选内容
 z370cuda支持-相关内容
z370cuda支持-相关内容
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 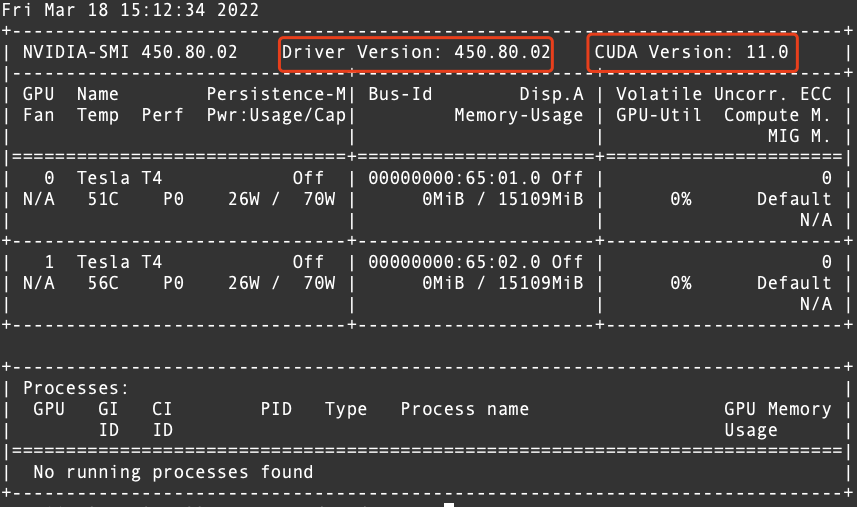 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
GPU-部署Baichuan大语言模型
模型支持FP16、INT8、INT4三种精度,可以在GPU实例上部署并搭建推理应用。该模型对GPU显存的需求如下: 精度 显存需求 推荐实例规格 GPU显卡类型 FP16 27 GB ecs.g1ve.2xlarge V100 * 1(单卡32 GB显存) INT8 17 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) INT4 10 GB ecs.gni2.3xlarge A10 * 1(单卡24 GB显存) 软件要求注意 部署Baichuan大语言模型时,需保证CUDA版本 ≥ 11.8。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。...
【高效视频处理】一窥火山引擎多媒体处理框架-BMF|社区征文
BMF完整支持GPU硬件,提供CPU到GPU的数据传输。我们可以实现视频解码和视频过滤等任务的GPU加速,显著提升处理效率。它还支持不同框架如CUDA和OpenCL之间的异构计算。从这些建议简单实验开始, 开发者就可以感受到BMF模块化设计及其强大的处理能力。同时,它提供Python、C++和Go三种语言接口,语法简洁易用,无门槛上手。通过这些基础功能,我们已经看到BMF在视频管道工程中的广阔地平线。> 深入原理学习如何创建自己的视频处理模...
AI ASIC 的基准测试、优化和生态系统协作的整合|KubeCon China
而且支持相应的维度越界检查。除了 -1 轴之外,其他维度支持任意 stride 访存,此外,GEMM、TPC、DMA 的指令序列是独立的,pipeline 运行时是 latency 会被隐藏起来。此外,TPC 也添加了 AI 负载常见的激活函数,作为... 而各家 ASIC 由于具备类似 CUDA 的开发生态,往往都需要单独适配,且各家 ASIC 往往都会自带一套自身的软件栈,从使用方式,硬件管理,监控接入等层面,都需要额外开发。这些相比沿用 GPU,都是额外成本。...
VirtualBox制作ubuntu14镜像
实验介绍CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。 Pytorch使... 其他根据自己需求选择 根据需要选择 步骤三:设置ssh远程登录由于VirtualBox不支持鼠标,也不知道快捷键复制粘贴,为了方便后续操作,推荐ssh登录远程虚拟机 选择虚拟机,选择“设置” 选择网络,点击“高级” 选择...
GPU-部署ChatGLM-6B模型
支持在消费级的显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。ChatGLM-6B使用了和ChatGLM相同的技术,针对中文问答和对话进行了优化。经过约1T标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的ChatGLM-6B已经能生成相当符合人类偏好的回答。 软件要求注意 部署ChatGLM-6B语言模型时,需保证CUDA版本 ≥ 11.4。 NVIDIA驱动:GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以535.86.10为例...
预置镜像列表
CUDA平台提供的 CUDA 镜像基于 nvidia/cuda 系列镜像构建,提供的 CUDA 版本包括 11.7.0、11.6.0、11.3.0、11.1.1。 内含 GPU 加速工具库、编译器、开发工具和 CUDA 运行时环境,适合通用的高性能计算场景。 镜像的主要特性: 支持平台的高性能网络基础设施,提供了 nccl-tests 用于测试。 支持不同版本的 Python ,涵盖 3.7 到 3.10 。 内置常用开发工具,如 git, rclone, vim 。 pip 、 conda 和 apt 使用国内镜像源。 内置 CUDNN 8...
GPU实例部署paddlepaddle-gpu环境
本文介绍 GPU 实例部署深度学习Paddle环境。 前言 在ECS GPU实例上部署深度学习Paddle环境。 关于实验 预计实验时间:20分钟级别:初级相关产品:ECS受众: 通用 环境说明 本文测试规格如下:实例规格:ecs.pni2.3xlargeGPU 类型:Tesla A100 80G显存容量:81920MiB实例镜像:velinux - 1.0 with GPU DriverNVIDIA-SMI:470.57.02NVIDIA Driver version:470.57.02CUDA version:11.4CUDA Toolkit version:11.2Python version:Python 3.7.3pa...
【发布】多模态 VisualGLM-6B,最低只需 8.7G 显存
支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共 78 亿参数。VisualGLM-6B 依靠来自于 CogVie... .half().cuda() image_path = "your image path" response, history = model.chat(tokenizer, image_path, "描述这张图片。", history=[]) ...
