a+卡有cuda
 社区干货
社区干货
在GPU实例中安装配置dcgm-exporter
> 测试环境:VeLinux 1.0## 创建并连接GPU实例## 安装CUDA驱动* 下载并安装CUDA依次执行以下命令,完成CUDA的下载。```javascriptnvidia-smi //查看该实例驱动信息wget https://developer.download.nvidia... curl localhost:9400/metrics //检索指标```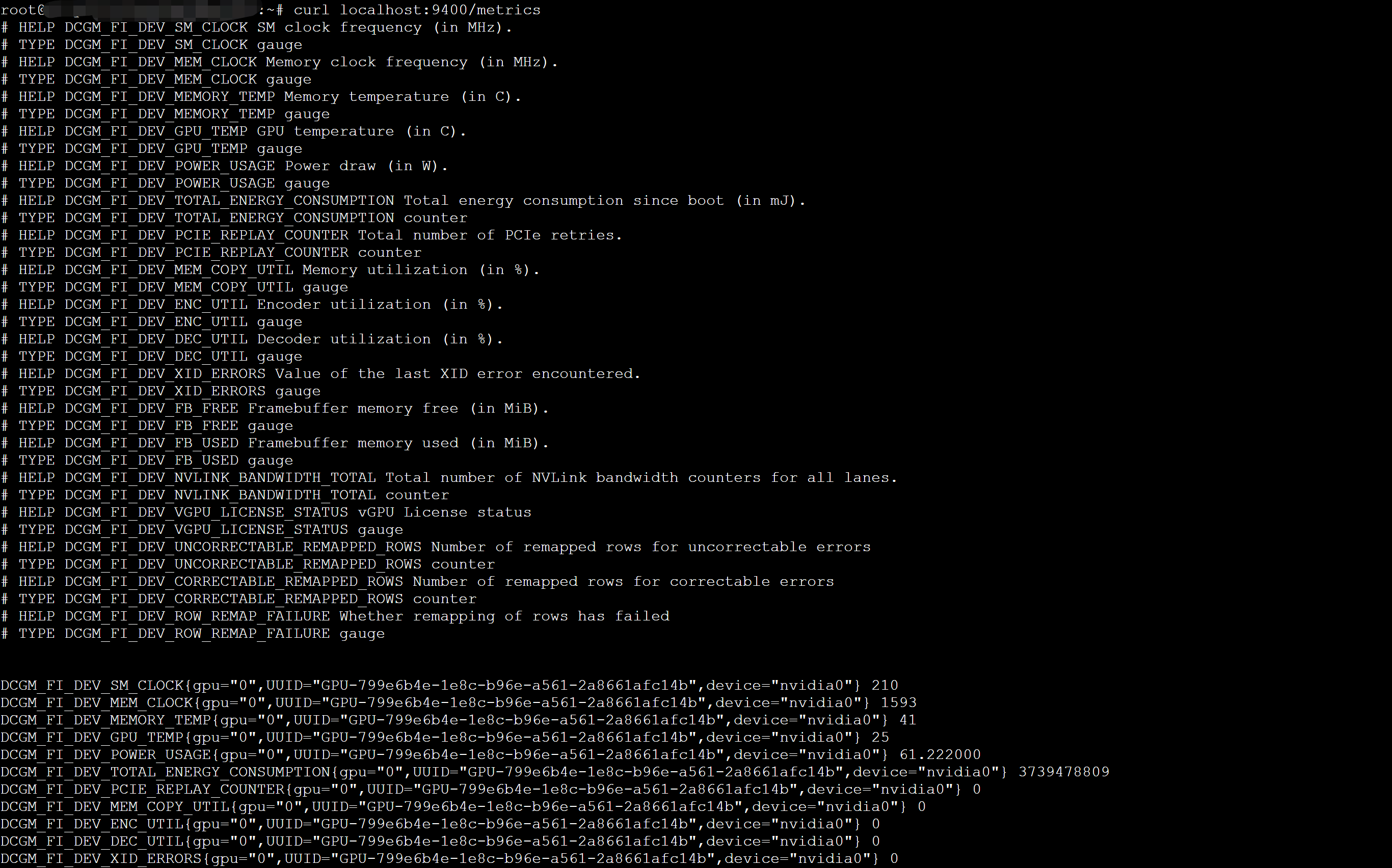可成功获取到GPU卡信息。如果您有其他问题,欢...
大模型:深度学习之旅与未来趋势|社区征文
我们还通过BertTokenizer.from_pretrained()方法加载了预训练的tokenizer。最后,我们通过BertForTokenClassification.from_pretrained()方法加载了BERT模型。3.输入文本进行NER:```pythondef ner_inference(text): input_ids = tokenizer.encode(text, add_special_tokens=True) input_tensors = torch.tensor([input_ids]) # 使用GPU进行推理(如果可用) device = torch.device("cuda" if torch.cuda.is_a...
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。 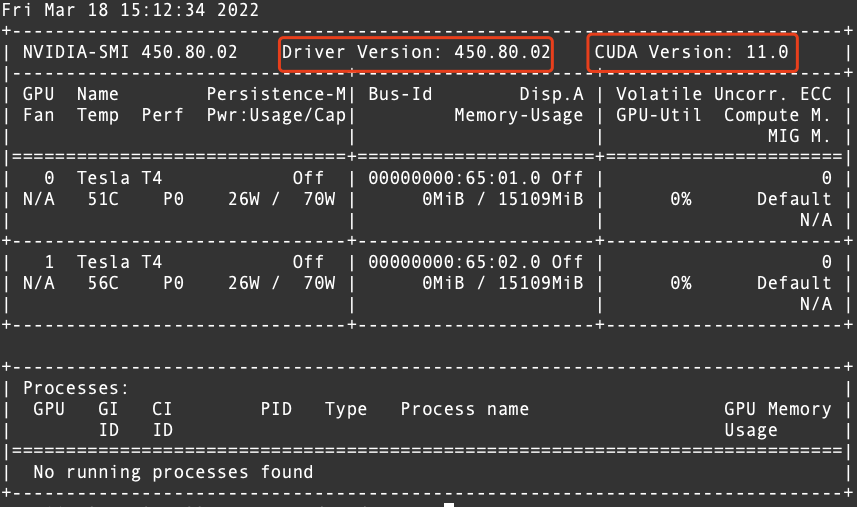 从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
# 前言大语言模型(LLM,Large Language Model)是针对语言进行训练处理的大模型,建立在Transformer架构基础上的语言模型,大语言模型主要分为三类:编码器-解码器(Encoder-Decoder)模型、只采用编码器(Encoder-Only)模... test_data['label'], tokenizer)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=32)# 训练模型device = torch.device('cuda' ...
 特惠活动
特惠活动
 a+卡有cuda-优选内容
a+卡有cuda-优选内容
 a+卡有cuda-相关内容
a+卡有cuda-相关内容
大模型:深度学习之旅与未来趋势|社区征文
我们还通过BertTokenizer.from_pretrained()方法加载了预训练的tokenizer。最后,我们通过BertForTokenClassification.from_pretrained()方法加载了BERT模型。3.输入文本进行NER:```pythondef ner_inference(text): input_ids = tokenizer.encode(text, add_special_tokens=True) input_tensors = torch.tensor([input_ids]) # 使用GPU进行推理(如果可用) device = torch.device("cuda" if torch.cuda.is_a...
Linux安装CUDA
# 运行环境* CentOS* RHEL* Ubuntu* OpenSUSE# 问题描述初始创建的火山引擎实例并没有安装相关cuda软件,需要手动安装。# 解决方案1. 确认驱动版本,以及与驱动匹配的cuda版本,执行命令`nvidia-smi`显示如下。  从上图中可以确认CUDA的版本为 11.02. 从英伟达官方网站下载相对应的 CUDA 版本的...
新功能发布记录
table th:nth-of-type(4) { width: 15%;}table th:nth-of-type(5) { width: 30%;}2024年04月12日序号 功能描述 发布地域 阶段 文档 1 创建GPU云服务器时,支持后台自动安装更高版本的GPU驱动、CUDA和CUDNN库。... 邀测 管理vePFS存储资源 2022年12月13日序号 功能描述 发布地域 阶段 文档 1 搭载T4显卡的GPU计算型g1te、g1tl实例支持手动安装GRID驱动并激活License服务。 华北2(北京) 商用 安装GRID驱动 卸载GRID驱动 2022...
新功能发布记录
2024-02-27 AIOps 支持 GPU 链路故障检测和自愈 【邀测·申请试用】支持在 GPU 链路故障和性能下降场景下的故障检测和禁止调度能力。当 GPU 链路性能下降时,用户能够根据训练任务特性或 GPU 卡资源库存,决定是否降... 对业务侧使用的 CUDA 等软件不同版本进行适配。 华北 2 (北京) 2024-01-31 自定义 GPU 驱动安装说明 华南 1 (广州) 2024-01-30 华东 2 (上海) 2024-01-30 AIOps 套件支持生成和下载巡检/故障诊断报告 【邀测·申请...
探索大模型知识库:技术学习与个人成长分享 | 社区征文
# 前言大语言模型(LLM,Large Language Model)是针对语言进行训练处理的大模型,建立在Transformer架构基础上的语言模型,大语言模型主要分为三类:编码器-解码器(Encoder-Decoder)模型、只采用编码器(Encoder-Only)模... test_data['label'], tokenizer)train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=32)# 训练模型device = torch.device('cuda' ...
火山引擎部署ChatGLM-6B实战指导
[picture.image](https://p6-volc-community-sign.byteimg.com/tos-cn-i-tlddhu82om/85544e397eed48848081f9d06d9e8276~tplv-tlddhu82om-image.image?=&rk3s=8031ce6d&x-expires=1713630067&x-signature=47dtgxnrdjAZH9ceExH4hJBfIHI%3D)2. 在实例类型中,选择GPU计算型,可以看到有A30、A10、V100等GPU显卡的ECS云主机,操作系统镜像选择Ubuntu 带GPU驱动的镜像,火山引擎默认提供的GPU驱动版本为CUDA11.3,如果需要升级版本的话可...
HPC裸金属-基于NCCL的单机/多机RDMA网络性能测试
关键组件 说明 NVIDIA驱动 GPU驱动:用来驱动NVIDIA GPU卡的程序。 CUDA工具包:使GPU能够解决复杂计算问题的计算平台。 cuDNN库:NVIDIA CUDA(®) 深度神经网络库,用于实现高性能GPU加速。 OpenMPI OpenMPI是一个开源的 Message Passing Interface 实现,是一种高性能消息传递库,能够结合整个高性能计算社区的专业知识、技术和资源,建立现有的最佳MPI库。OpenMPI在系统和软件供应商、应用开发者和计算机科学研究人员中有广泛...
GPU-基于Diffusers和Gradio搭建SDXL推理应用
Diffusers已经支持SDXL 1.0的base和refiner模型,可生成1024 × 1024分辨率的图片。 软件要求GPU驱动:用来驱动NVIDIA GPU卡的程序。本文以470.57.02为例。 Pytorch:开源的Python机器学习库,实现强大的GPU加速的同时还支持动态神经网络。本文以2.0.0为例。Pytorch使用CUDA进行GPU加速时,在GPU驱动已经安装的情况下,依然不能使用,很可能是版本不匹配的问题,请严格关注虚拟环境中CUDA与Pytorch的版本匹配情况。 Anaconda:获取包且对...
关于对Stable Diffusion 模型性能优化方案分享 主赛道 | 社区征文
Stable Diffusion技术作为一种先进的生成模型,具有在生成图像任务中表现出色的潜力。然而,在实际部署中,要确保模型在端侧设备上的高效运行,需要面对一系列挑战,包括性能瓶颈和资源利用率。通过模型优化方案,参赛者... import argparsefrom PIL import Imagefrom PIL.PngImagePlugin import PngInfoimport osfrom tensorflow_model_optimization.python.core.sparsity.keras import prune_low_magnitudeos.environ["CUDA_DE...
